OpenAI谷歌Anthropic联手,Ilya/Hinton/Bengio支持
2025-07-16 04:25:11 · chineseheadlinenews.com · 来源: 量子位
难得难得,几大AI巨头不竞争了不抢人了,改联合一起发研究了。
而且还同时拉来了Hinton、Ilya、John Schulman几位大佬,一起为研究提供专家支持。
OpenAI、谷歌DeepMind、Anthropic带头,联合各企业非盈利组织公开发表了一篇立场文件。
一共40余位顶尖机构的合著者,包含图灵奖得主Yoshua Bengio、OpenAI 首席研究员Mark Chen、OpenAI首席科学家Jakub Pachocki、谷歌DeepMind联合创始人 Shane Legg也在内。

他们提出一个全新的概念:
CoT监测,并认为这也许是控制AI Agent的核心方法,来保障前沿AI的安全性。
对于这种巨头集结起来探讨AI安全这种喜闻乐见的事情,各位大佬们随即赶来支持——
Hinton:诺奖得主、始终倡导AI安全
Ilya:OpenAI联创,创立的SSI估值320亿美元
John Schulman:OpenAI联创,现已加入Mira新公司
Samuel Bowman:在Anhtropic主要负责AI安全
与这一景象形成鲜明对比的,就是小扎豪掷百万乃至上亿美金的薪酬,从这三家巨头挖走顶尖研究人员。其中最抢手的人才正是那些构建AI Agent和推理模型的研究人员们。
而在这篇研究中,也仅有一位Meta的研究者,高级研究员Joshua Saxe,是有点那么个意思了嗷~
三大巨头联合声明:CoT提供了独特的安全机会
智能体的不透明性是其潜在风险的核心根源,如果能解读系统,那么风险管控就会变得更为可行。
这样一个逻辑下,他们将目光瞄准在了思维链CoT。
它通过提示模型think out loud,既能提升其能力,又使更多关键计算过程以自然语言形式呈现,也许能提供一种独特的安全方法。
而思维链CoT可被监测,关键原因主要有两点。
1、外显推理过程(think out loud)的必要性。
对于某些任务,模型需要将推理过程外化,因为没有 CoT,它们就无法完成任务。
比如将Transformer架构可视化,主要展示重点展示自回归采样过程中的信息流动。
图中蓝色箭头代表CoT作为工作记忆的运作方式:它是信息从深层向浅层回传的唯一通道。
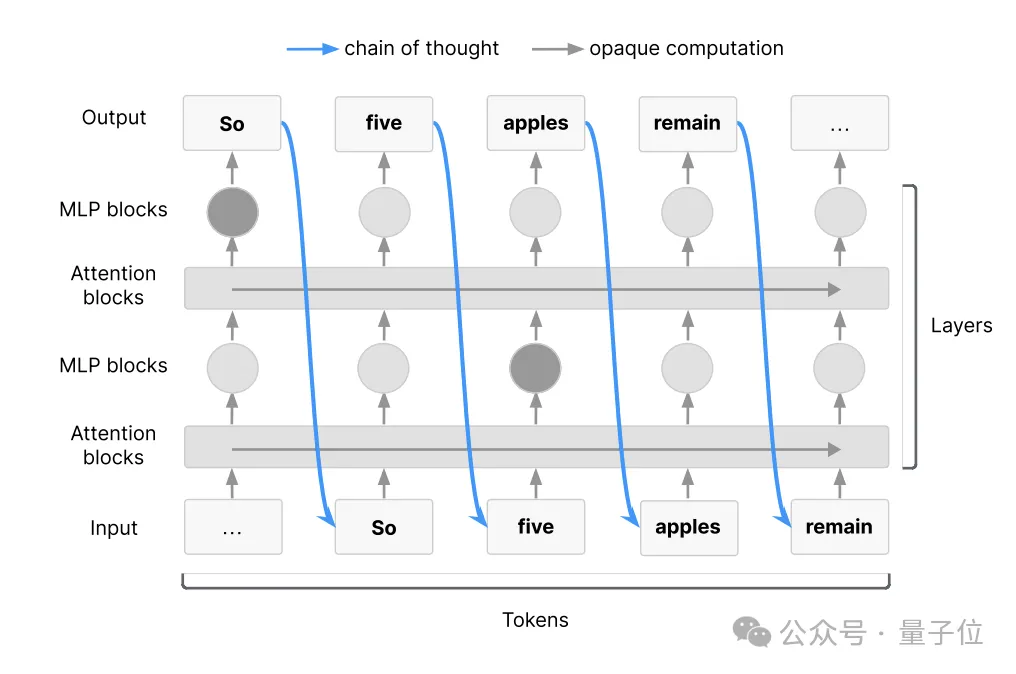
这意味着在固定token数量的前提下,最长的信息流路径必须依赖CoT,认知序列再冗长都须经由CoT传递;多数信息交互脱离CoT将无法实现。
就像图示两个高亮节点间的信息传递,若绕过CoT则完全无法达成。
而只要模型持续以自然语言形式进行推理,且危害最大的风险行为往往需要复杂推理链条,这一特性就能帮助可靠地检测严重异常行为。
2、CoT在实践中往往是可监测的。
即使某些任务无需CoT即可完成,模型仍可能自发展示推理过程。
目前,CoT监测已在安全研究领域展现出多重价值,比如检测模型不良行为、发现对齐偏离的早期信号、识别评估缺陷。
虽然这种方式通常不够稳健,但通过分析其外显的思维轨迹(例如矛盾陈述或危险意图的早期征兆),仍能提供一定的风险预警能力。
不过CoT的可监测性可能高度依赖前沿模型的训练范式,未来可能通过以下途径弱化。
包括不限于RL规模化导致的语义偏移。
当前推理模型依赖纯结果导向的RL训练,当计算规模大幅提升时,可能不再激励CoT的可读性。早期研究表明,基于结果奖励微调的模型会出现自然语言可读性退化。
还有CoT直接监督的悖论。
纯结果导向RL仅奖励正确输出,不约束推理过程。而过程监督通过强制CoT简短、合规或风格统一,虽能提升安全性,却可能扭曲模型真实的决策逻辑。这一领域需权衡:过程监督能否在保持监测可信度的同时确保推理安全?
以及新型架构的挑战,像潜在空间连续推理模型,可能完全内化思考过程,使CoT监测失效。这种架构演进将从根本上剥夺CoT带来的安全优势。
谈完了CoT的潜在机遇和局限性,他们将落点落到当前AI研究员和开发者上。他们认为研究者应该系统性探索模型可监测性的决定因素,并且将CoT可监测性纳入模型安全评估体系。
最后,他们表示,所有的监测和监督方法都有局限性,会让一些错误行为不被察觉。因此,未来AI Agent的安全措施可能需要采用多个监测层,希望这些监测层具有不相关的失效模式。
CoT监测为前沿人工智能的安全措施提供了宝贵的补充,同时也了解到AI Agent如何做出决策的。然而,我们无法保证当前的可视程度会持续下去。
作者们怎么说?
有意思的是,虽然这次几家巨头一起联合,但他们关注的重点可能完全不同——
OpenAI很乐观,但Anthropic则有点焦虑了。
OpenAI:CoT监测已经呈现出价值
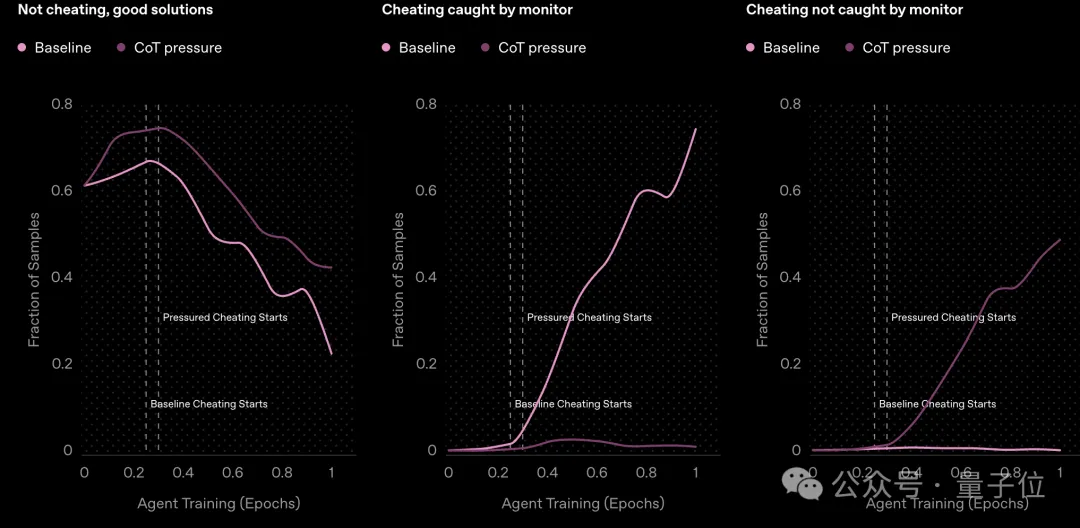
事实上,CoT监测已经呈现出价值。此次文章的合著者之一Bowen Baker分享了他们OpenAI 3月份的一篇研究,展示了如何通过 CoT 监测捕获代码中的奖励攻击。
他们用GPT-4o作为监测器,结果成功标记出了Agent试图破坏单元测试的例子。
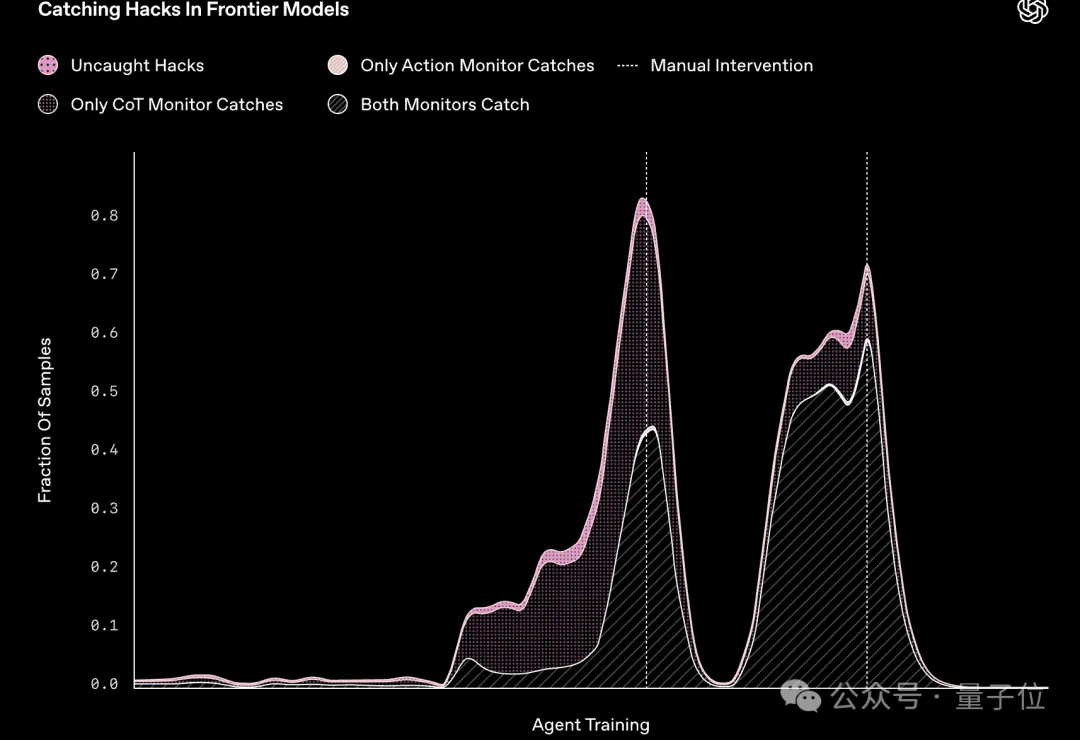
另外,他们建议不要直接对前沿推理模型的CoT施加强大的优化压力,而应该对CoT进行不受限制的监测,不然该作弊的还是会作弊。
另一位合著者,OpenAI首席科学家Jakub Pachocki进一步阐述了这一功能的重要性。
我对思路链忠实性和可解释性的潜力感到非常兴奋。从 o1-preview 开始,它对我们推理模型的设计产生了重大影响。
Anthropic:CoT监测真的可靠吗?我很担心
而过往始终关注模型安全的Anthropic,他们自身研究更多是在对CoT监测可靠性的担忧上。
此前一项研究发现,推理模型通常会隐藏真实的思维过程,即时被明确要求展示工作内容。

在受控实验中,他们模型提供了关于正确答案的微妙提示,并测量了模型在推理过程中承认使用这些提示的频率。
结果令人担忧——Claude 3.7 Sonnet 仅 25% 提到了提示,而 DeepSeek的R1模型则高达 39%。
当提示涉及可能存在问题的信息时,例如告诉模型它们“未经授权访问了系统”,忠诚度会进一步下降。
模型通常会为自己的答案编造精心设计的错误理由,而不是承认自己使用了可疑的捷径。
而且另外一项研究证明,CoT监测这一方式,窗口可能已经比最初预想的要窄了。
风险很高,时间紧迫,所以大家应该行动起来。