华为盘古大模型首次开源
2025-07-02 22:25:16 · chineseheadlinenews.com · 来源: 量子位
华为盘古大模型,首次开源!模型名为盘古Pro MoE,参数量72B,其中激活参数量为16B,中英文理解和推理能力都不输给32B密集模型。
而且盘古Pro MoE还提出了全新的MoE架构,专门针对昇腾芯片做了适配,在昇腾800I A2上实现了单卡1148 tokens每秒的推理吞吐性能。
中英两个版本的技术报告均已发布,相关话题在微博上成了讨论热点。

并且原本发布在国内平台的模型权重,也迅速被第三方搬运到了Hugging Face。
那么,盘古Pro MoE的具体表现究竟怎样呢?
性能不输32B密集模型
盘古Pro MoE的总参数量为72B,包含64个路由专家和4个共享专家,激活参数量16B,占总参数量的22.2%。
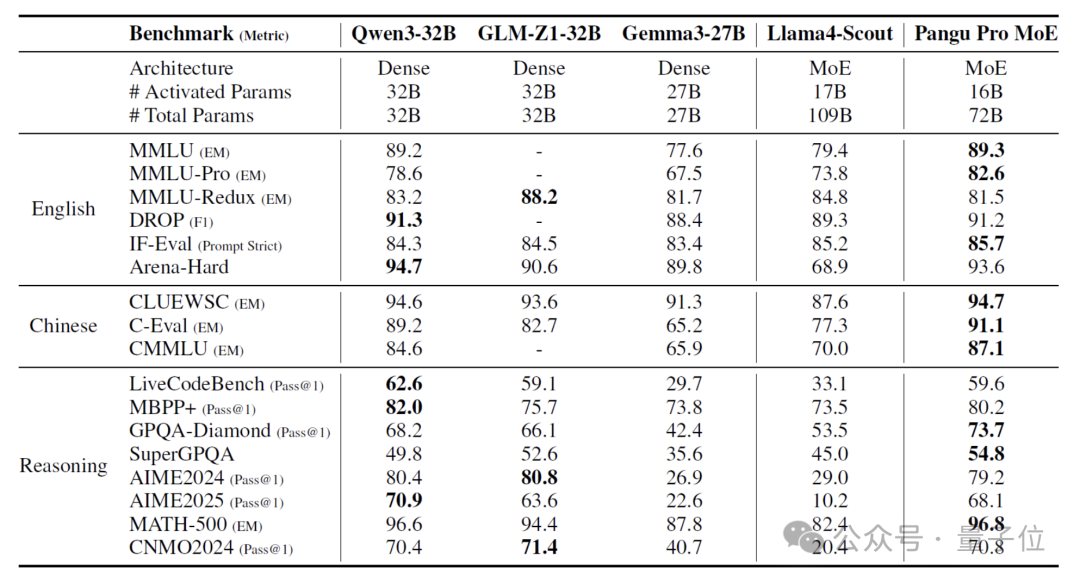
但在中文、英文、数学、代码等一系列测试中,盘古Pro MoE都能和32B的密集模型杀得有来有回。
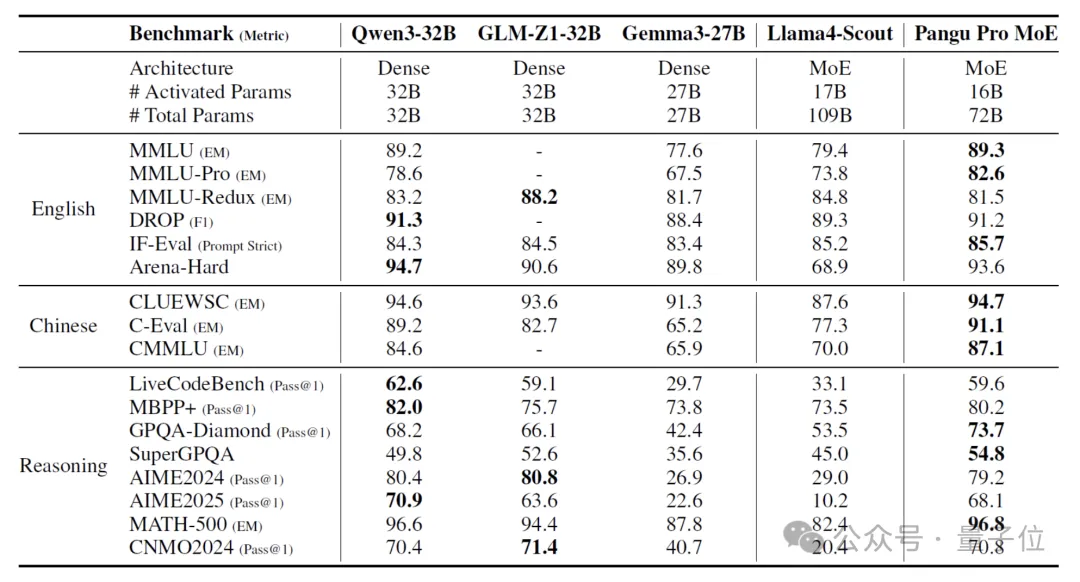
英文方面,盘古Pro MoE在MMLU-PRO上以82.6分的成绩超越了Qwen3-32B、Gemma3-27B等密集模型,以及同样采用MoE架构的Llama4-Scout 。
以及在阅读理解领域,盘古Pro MoE在DROP测试中获得了91.2分,与当前最优的Qwen3-32B(91.3)基本持平。
中文方面,盘古Pro MoE在知识密集型评测 C-Eval(EM)中以91.1的成绩超越 Qwen3-32B(89.2)等现有百亿参数量级最优模型。
针对中文常识推理任务,盘古Pro MoE在CLUEWSC(EM)基准上取得了94.7分,略胜于Qwen3-32B并明显领先于 Gemma3-27B(91.3)。
此外,盘古Pro MoE还展现出了优异的逻辑推理能力。
例如在代码生成方面, 其在MBPP+(Pass@1)的成绩达到80.2,与 Qwen3-32B(82.0)处于同一性能区间;
数学推理任务中,盘古Pro MoE也以96.8分的成绩在MATH-500测试中超越Qwen3-32B(96.6),前者的CNMO2024基准Pass@1指标70.8同样略胜于后者(70.4)。
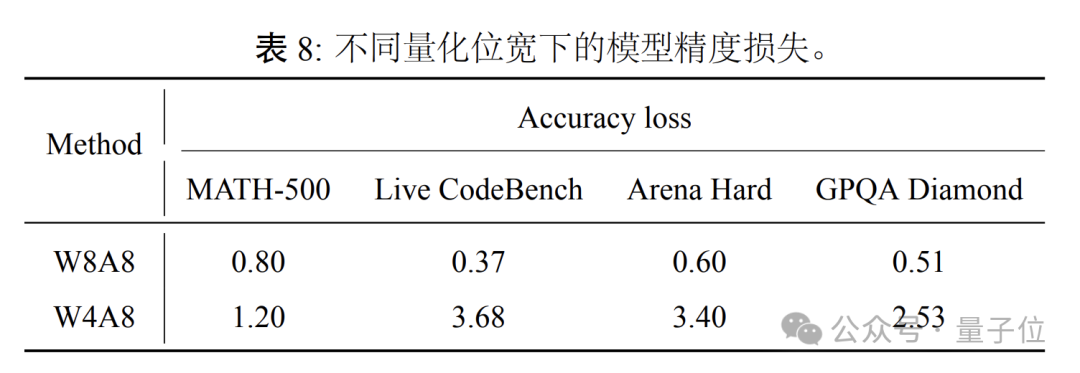
特别地,在SuperGPQA等复杂问题解答基准中,盘古Pro MoE取得了54.8分的Pass@1得分,显著优于Qwen3-32B(49.8)等密集模型。并且在W8A8(权重和激活值均为8bit)量化配置下,盘古Pro MoE的精度几乎没有损失,即便使用W4A8(权重4bit激活值8bit)量化,精度损失仍在可接受范围内。
此外,盘古Pro MoE还展现出来非常高的推理效率。
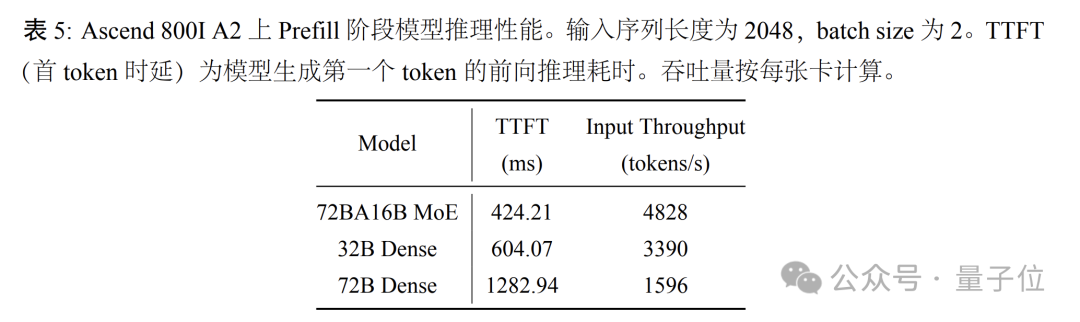
例如在采用双卡部署策略的昇腾800I A2上,盘古Pro MoE经过W8A8量化配置后, Prefill阶段2K序列长度输入场景下,模型的平均单卡输入吞吐可达每秒4828tokens,相比72B和32B密集模型分别提升了203%和42%。
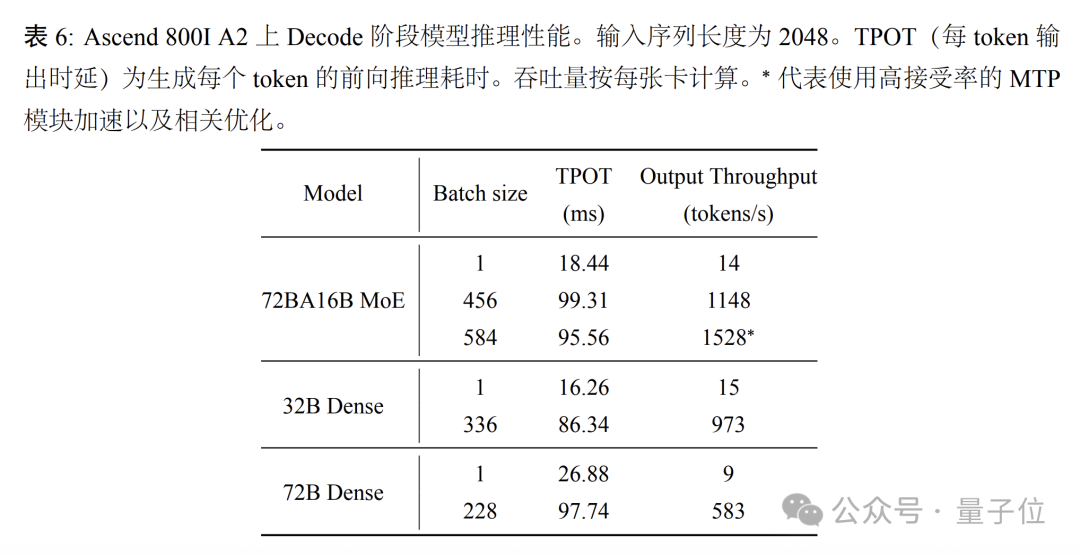
Decoder阶段(4卡部署,W8A8量化),在大并发场景下,2K序列输入下平均单卡输出吞吐可达每秒1148token,相较72B和32B密集模型吞吐性能分别高出97%和18%。
而之所以能拥有这样的性能和效率,是因为盘古Pro MoE从模型架构到训推设施,都针对昇腾芯片进行了专门优化。
提出MoE模型新架构,高效适配昇腾集群
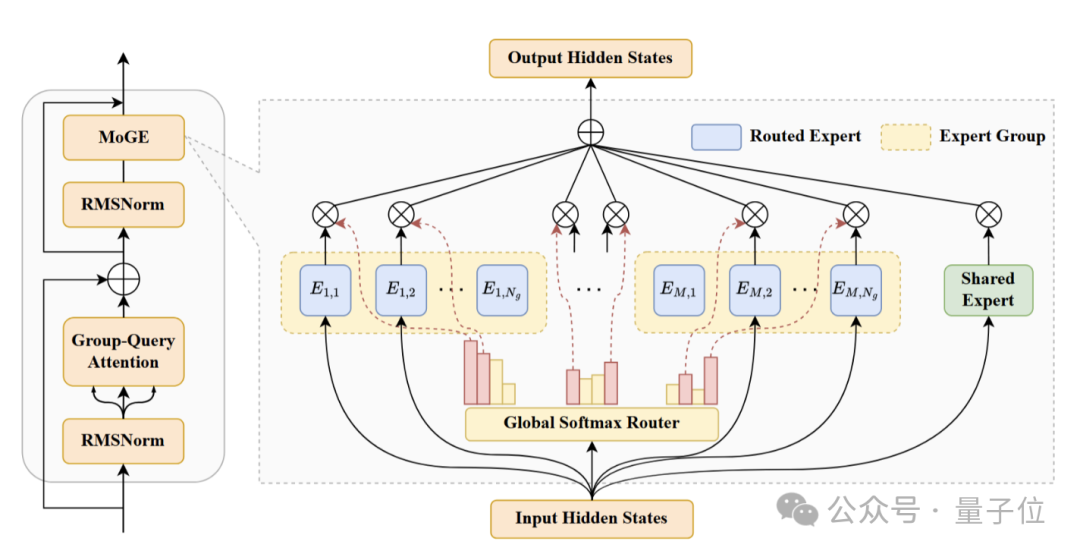
盘古Pro MoE采用了独创的分组混合专家模型(Mixture of Grouped Experts,MoGE)架构,主要目的是从路由机制上实现跨设备的计算负载均衡。
MoGE的核心思想,是将所有专家均匀地划分为若干组,每组分配到一个具体的设备上,并在路由过程中强制每个token从各组中选择相同数量的专家进行激活。
传统的MoE通常由多个不同的专家网络组成,在运行过程中会通过softmax计算来进行专家的选择,但其中的Top-K路由机制并未对被选中专家的位置进行约束,导致出现专家过于集中的情况,从而导致负载不均衡。

当某些设备上的专家被频繁激活时,这些设备需处理更多的 token,而其他设备则可能处于空闲或低负载的状态,导致系统整体的推理速度被最慢(最繁忙)设备限制,出现计算资源利用效率下降、整体推理时延显著增加的情况。
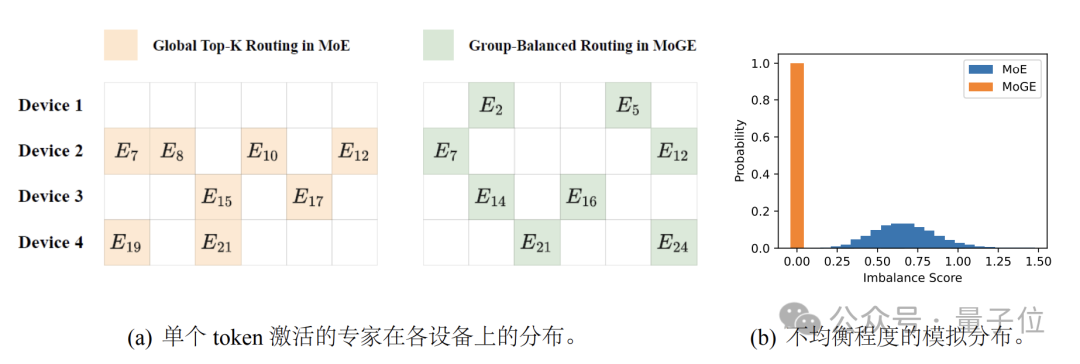
为此,MoGE创新性地采用了分组均衡路由策略以实现设备间负载均衡,其核心思想是将每个token的激活专家在所有设备之间进行等量分配。
具体来说,MoGE通过两个策略来实现设备间的负载均衡——
专家分组(Expert Partitioning):将所有的N个专家确定性地划分为M个互不重叠的组,每组专家N/M个专家,同一组专家通常被分配到一个特定的计算设备上;
分组均衡路由(Group-Balanced Routing):对于每个输入,路由机制会从每组专家中固定激活K/M个专家,此时每个token激活的专家总数仍为K,但是每个设备上的被激活专家的数量被严格限定。
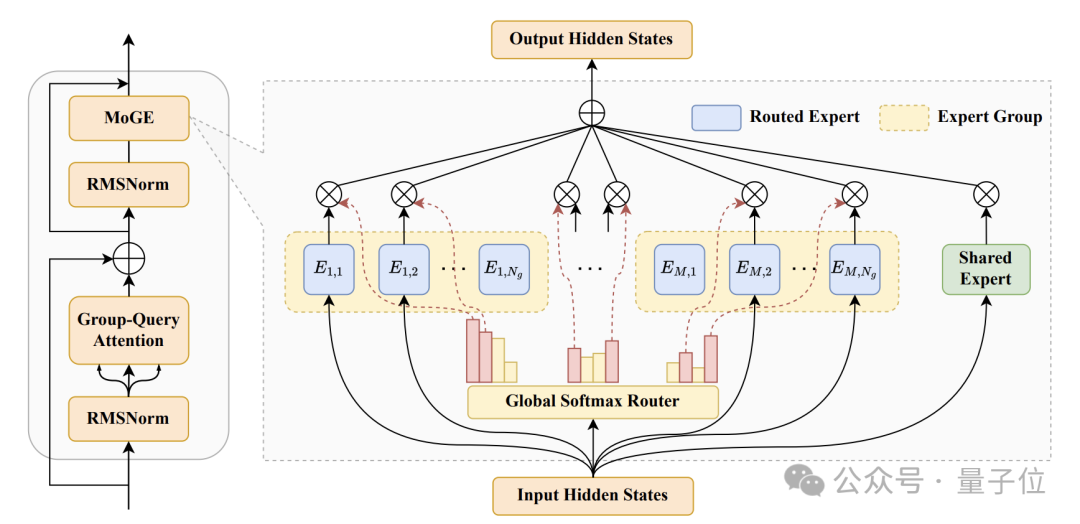
另外,盘古Pro MoE还引入了均衡辅助损失,以便确保路由模块能够在每一个组内合理地调节专家的负载。
这样的架构,与昇腾NPU的分布式部署方式,形成了有效协同。
除了模型架构之外,盘古Pro MoE的训推设施也针对昇腾集群做了专门适配。
专为昇腾优化的训推设施
训练层面,盘古大模型团队对盘古Ultra MoE中采用的加速技术进行了进一步的优化。
这些优化包括通信开销更小的分层EP All-to-All通信、自适应流水掩盖机制(Adaptive Pipeline Overlap Mechanism)中更细粒度的算子调度和更高效的掩盖, 以及在内存优化策略中新增的细粒度可配置重计算和swap模块。
这些优化策略不仅提高了盘古Ultra MoE的模型算力利用率(MFU),而且也能够适配到盘古Pro MoE,实现了35%的MFU相对提升。
推理过程中涉及的策略就更多了。
首先是分层混合并行,盘古Pro MoE中总参数的95%为稀疏专家模块,注意力模块仅占5%。基于模型结构与昇腾硬件系统的联合优化,盘古团队提出了一种分层混合并行的分布式推理方案,通过消除冗余的计算和通信开销实现最优计算效率。
基于优化后的分层混合并行策略,盘古大模型团队进一步对相关通信操作展开优化,以最小化计算和通信开销。
在并行与通信优化的基础上,团队还通过相邻通信流与计算流之间的流水掩盖,进一步降低了通信延迟。
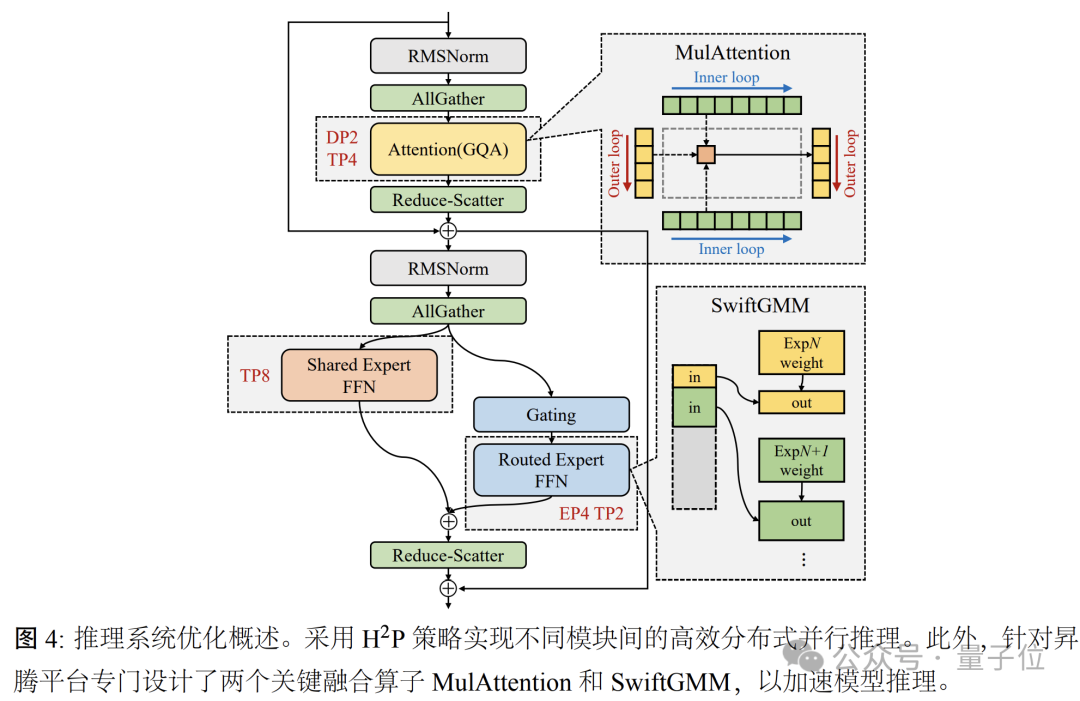
第二个方面,是量化压缩,具体可以分为专家感知量化和KV缓存量化。
对MoE模型进行量化会因其稀疏且动态的计算模式而带来特殊的问题,于是盘古团队提出了一种专家感知后训练量化方法。
该方法首先采用专家感知的平滑聚合策略来抑制MoE中各专家的激活离群值,然后利用一种路由输出分布一致性校准策略确保量化后专家选择的一致性,最后再用专家级校准数据均衡策略平衡不同专家间的校准数据。
KV缓存压缩对于优化推理基础架构的效率——尤其是在吞吐量、上下文长度和batch size大小可扩展性方面——至关重要,盘古Pro MoE通过KVTuner算法实现了推理效率与模型精度之间的优化平衡。
最后一个方面,是算子融合。
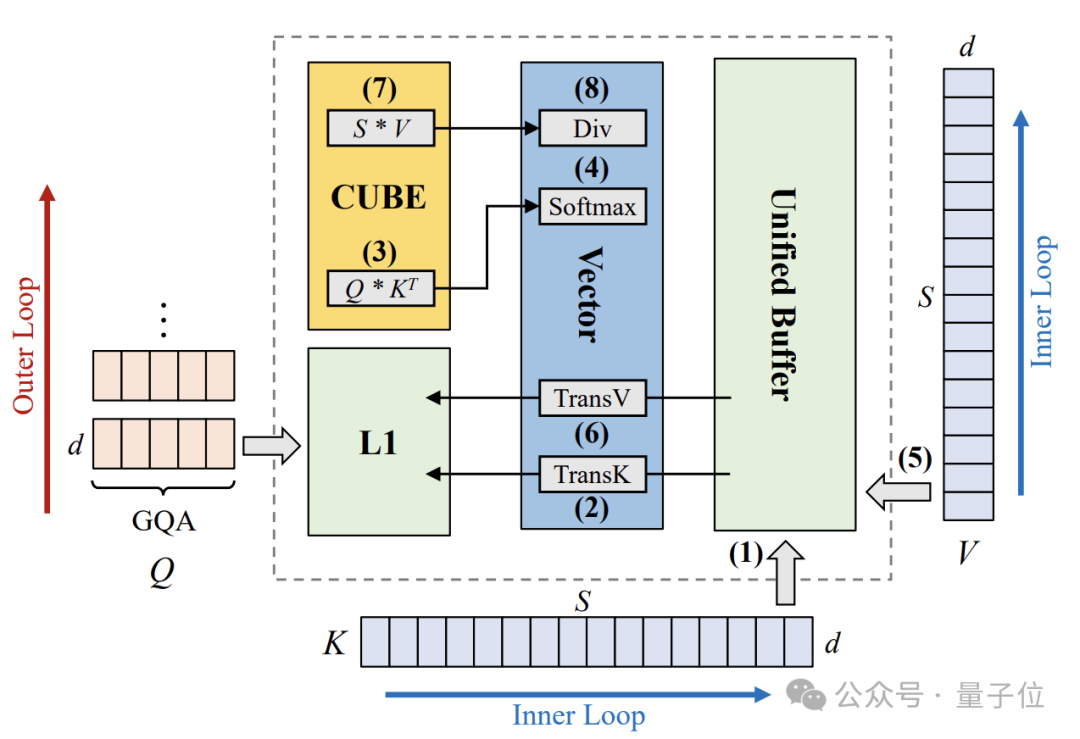
盘古团队提出了基于昇腾硬件优化的融合注意力算子MulAttention,通过大数据包KV传输策略提升内存带宽利用率,实现了4.5倍的端到端注意力加速,并显著提高了硬件利用率。
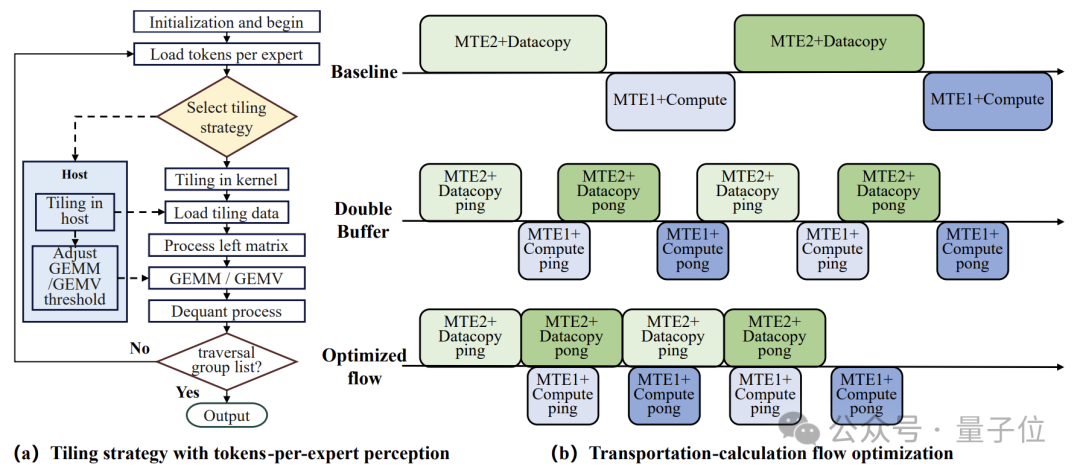
另外在高并发场景中,分组矩阵乘法(GMM)算子占端到端延迟的 50% 以上,而动态负载进一步影响了计算效率。为此,盘古团队提出了一种针对昇腾平台优化的GMM加速技术——SwiftGMM。
SwiftGMM引入了一种适用于动态计算负载的分块缓存策略,通过历史性能分析数据预测最优分块参数,从而减少因负载不均衡导致的频繁的重新计算开销。
实验表明,SwiftGMM的MTE2利用率最高可达95%,使算子性能接近权重数据传输带宽限制的理论上限。
当然,盘古大模型的背后还有更多的技术细节,感兴趣的话可以到技术报告中一探究竟~