RISC之父David Patterson:AI推理需要另一种硬件
2026-03-14 02:25:42 · chineseheadlinenews.com · 来源: DeepTech深科技
近日,2017 年图灵奖得主、被称为“RISC 之父”的 David Patterson 最近与 Google DeepMind 高级工程师马晓宇在 IEEE Computer 联合发表了一篇论文——“关于大语言模型推理硬件的挑战与研究方向”,引发了科技圈的关注与讨论。

(来源:arXiv)
David Patterson,这位 RISC 架构的奠基人、影响了全球 99% 微处理器设计的计算机科学家,在论文开篇就抛出了一个尖锐的判断:
当前 AI 芯片的设计思路,即满载的算力、堆叠的 HBM(High Bandwidth Memory,高带宽内存)、带宽优先的互联,与大语言模型推理的实际需求严重错配。

(来源:UC Berkeley)

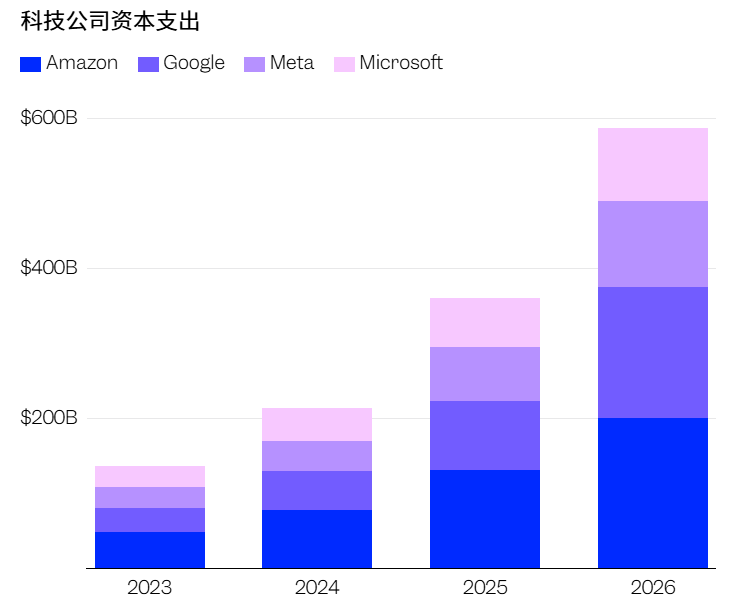
(来源:四家公司财报数据)


面对这些挑战,论文将问题归结为两堵“墙”:内存墙与延迟墙。
内存墙的本质是硬件发展的不均衡。Patterson 引用了一组数据:从 2012 年到 2022 年,NVIDIA GPU 的 64 位浮点运算能力提升了 80 倍,但内存带宽只增长了 17 倍。这个差距还在持续扩大。
更麻烦的是,HBM 的成本不降反升。论文援引花旗银行的研究数据指出,从 2023 年到 2025 年,HBM 的单位容量成本(/GB)和单位带宽成本(/GBps)都上涨了约 35%。这与传统 DDR DRAM 形成了鲜明对比,后者的成本在同期下降了近一半。
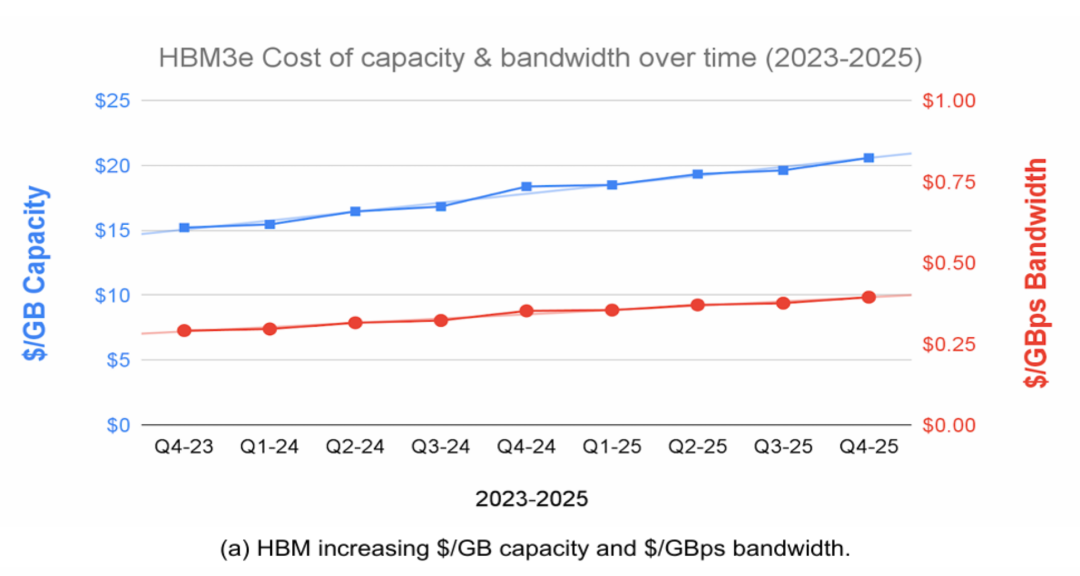
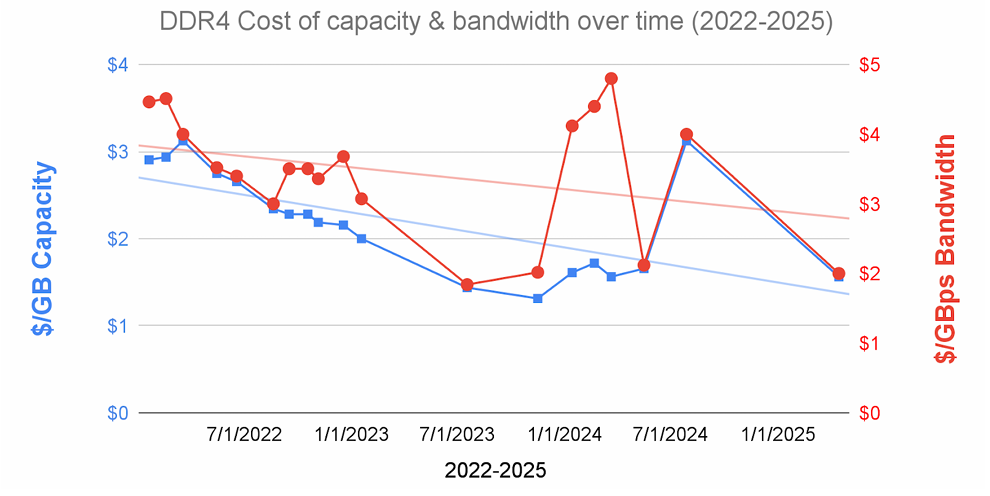
图 | HBM(上)和 DDR(下)的单位容量成本和单位带宽成本随时间变化的趋势线(来源:论文)
造成这种分化的原因在于制造工艺:HBM 需要堆叠多层 DRAM die,封装难度随着堆叠层数和密度的增加而上升,良率问题愈发严峻。
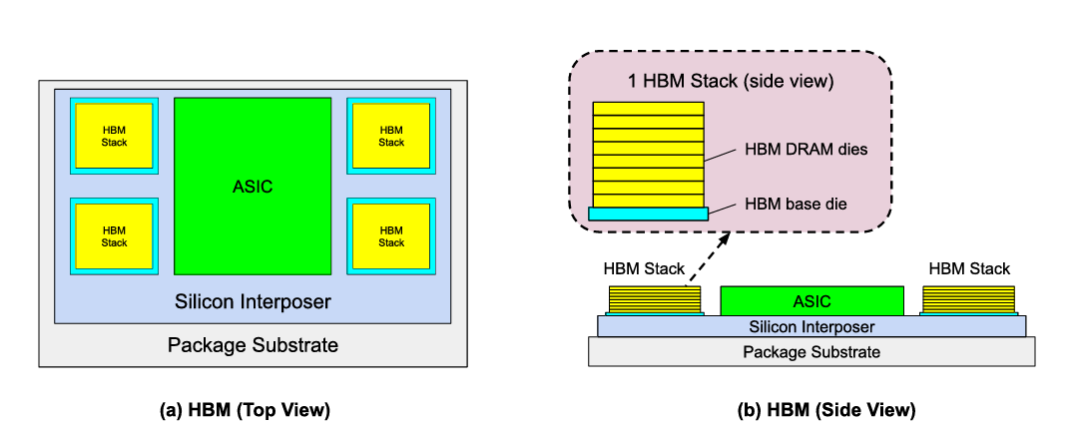
图 | (a) 高带宽内存 HBM 封装俯视图,(b) HBM 侧视图(来源:论文)

过去,数据中心的推理通常在单芯片上完成,只有训练需要超级计算机级别的集群。因此,连接这些芯片的互联网络主要优化带宽而非延迟。但 LLM 改变了游戏规则:模型太大,推理也需要多芯片系统;软件层面的分片(sharding)意味着频繁通信;而 Decode 阶段的小 batch size 导致网络消息往往很小。对于这种“频繁、小消息、大网络”的场景,延迟比带宽更重要。


这个方向有两种实现路径:一种是在 HBM 的 base die 上集成计算逻辑,复用现有 HBM 设计,带宽与 HBM 相当但功耗降低 2 到 3 倍;另一种是定制化 3D 方案,通过更宽更密的接口和更先进的封装技术,实现超越 HBM 的带宽和效率。挑战在于散热:3D 结构的表面积更小,散热更难,以及需要建立内存-逻辑接口的行业标准。
第四个方向是低延迟互联。
论文建议重新审视网络设计中延迟与带宽的权衡。具体措施包括:采用高连接性拓扑(如树形、蜻蜓、高维 Torus),减少跳数从而降低延迟;引入网络内处理(Processing-in-Network),让 LLM 常用的通信原语(如 all-reduce、MoE 的 dispatch 和 collect)在交换机中加速;优化芯片设计,让小包数据直接存入片上 SRAM 而非外部 DRAM,或将计算引擎靠近网络接口以缩短传输时间;甚至在可靠性设计上做文章,部署本地备用节点减少故障迁移的延迟和吞吐影响,或者在 LLM 推理对完美通信要求不高时,用假数据或历史结果替代超时消息,而非等待掉队者。
Patterson 在论文中还不忘强调个人观点:他批评了当前学术界与产业界的脱节。
1976 年他入行时,计算机架构会议上约 40% 的论文来自工业界,而到 2025 年的 ISCA(International Symposium on Computer Architecture),这个比例已经跌破 4%。
他呼吁学术研究者把握 LLM 推理这个"诱人的研究目标",并建议开发基于 Roofline 模型的性能模拟器,配合现代的性能/成本指标(如 TCO、功耗、碳排放),为 AI 推理硬件创新提供更实用的评估框架。
当前,全球正经历一场因 AI 引发的内存供应危机。由于 HBM 生产挤占了传统 DRAM 的晶圆产能,2026 年全球 DRAM 价格大幅上涨。三星、SK Hynix 等厂商正将更多资源转向高利润的 HBM 产品线,这虽然满足了 AI 数据中心的需求,却加剧了消费级内存的短缺。这种供应紧张可能持续到 2027 年甚至更久。
在这种背景下,Patterson 提出的 HBF、PNM 等替代路径,或许不仅是技术上的探索,也是产业寻找 Plan B 的现实需求。
当然,论文也承认这些方向并非可以一蹴而就的方案。每一个都涉及复杂的工程权衡:HBF 需要解决软件如何处理有限写入耐久性和高延迟读取的问题;PNM 和 3D 堆叠需要新的软件分片策略和内存-逻辑接口标准;低延迟互联可能需要牺牲部分带宽。
论文鼓励将这些方向组合使用,因为它们在很大程度上是互补的。更高的内存带宽可以缩短每次 Decode 迭代的延迟,更大的单节点内存容量可以减少系统规模从而降低通信开销。
作为 RISC 架构的共同发明人、RAID 存储系统的开创者,Patterson 的职业生涯几乎就是"挑战现有范式"的代名词。40 多年前,他和 John Hennessy 提出的精简指令集思想曾被工业界视为异端,如今 99% 的新芯片都采用 RISC 架构。
Patterson 和马晓宇选择发表这篇论文的方式也很有意思,它不是一篇技术细节密集的顶会论文,而是发在 IEEE Computer 这本面向更广泛读者的杂志上,语气像是在发布一封公开信。值得注意的是,他们在致谢中提到了 Martin Abadi、Jeff Dean、Norm Jouppi、Amin Vahdat 和 Cliff Young,这串名字几乎覆盖了 Google AI 基础设施的核心架构师。