英伟达两篇论文,带来具身智能的新范式
2026-02-11 02:25:18 · chineseheadlinenews.com · 来源: 腾讯科技
英伟达提出世界动作模型(WAM)新范式,突破当前主流VLA模型在物理泛化上的局限。WAM通过端到端联合预测视频与动作,学习物理规律,实现更强的零样本与跨机体泛化。研究揭示关键转变:物理智能依赖数据多样性而非数据量,可通过海量人类视频而非昂贵遥操作进行训练。这标志着具身智能正从“语义翻译”迈向“物理模拟”的新阶段。
2025年,具身智能领域最火的词就是VLA(视觉-语言-动作模型)。
它成了一种席卷全行业的共识,一个关于具身基础模型的标准答案。在过去的一年里,资本和算力疯狂涌入这条赛道,基本上所有的模型大厂,都在用这套范式。
但很快,现实的物理世界给所有从业者泼了一盆冷水。因为VLA在物理动作执行上很弱。
它能懂极其复杂的文字指令。但当机械臂真正去抓取时,它可能连如何调整手腕姿态以避开杯柄的阻挡都做不好,更别提让它去执行解开鞋带这种涉及复杂物理形变的动作了。
VLA的另一个致命痛点是泛化。本来之所以大家要做模型更新,为的就是不用为每个特殊环境编程,看重的正是大模型的泛化能力。结果现在,任何超越训练规定环境的动作,VLA基本都无法泛化,甚至出了训练环境类似的环境都做不了。
整个行业把泛化的无力,归结于数据的不足。大厂们开始投入亿万资金,用各种方式去采集数据,试图用海量的模拟演示来填补VLA的常识空缺。
但2026年初,英伟达(NVIDIA)发布了两篇论文《DreamZero: World Action Models are Zero-shot Policies》和《DreamDojo: A Generalist Robot World Model from Large-Scale Human Videos》两篇论文,构建了一套全新的具身智能基础模型范式,打破了数据内卷的僵局。
它们一起,给出了一个完全从视频里学习,Zero-shot(零样本)就能泛化执行不同工作的具身模型的可能。
VLA缺的不是数据,而是世界模型
要理解DreamZero和Dream Dojo的颠覆性,必须先从底层剖析VLA的系统性缺陷。
VLA的最大问题,就是缺乏世界模型。VLA的底层架构限制了它的认知方式。从谱系上看,VLA和LLM的亲缘更强,反而和纯视觉、纯物理的亲缘较弱。它通过交叉注意力机制(Cross-Attention)将图像的像素块映射到文本的语义空间中,在这个空间里,它理解了杯子和桌子的概念,理解了它们在二维画面中的相对位置。
但物理世界不是二维的语义切片。物理世界是连续的,充满了质量、摩擦力、重力和几何碰撞。
VLA对物理动作和世界的理解相对较弱,因为它本质上是一个“翻译器”。
我们可以用物理学中的状态转移方程来解释。一个完整的世界模型,本质上是在学习一个条件概率分布。它能在给定当前世界的状态(视觉观测)和机器人即将执行的动作,预测世界下一秒会变成什么样。
VLA从来没有学过这个方程。VLA学习的是静态视觉观测+语言指令直接映射到可执行动作的函数关系;却没被系统性地训练去预测动作后果、做反事实试错。所以一旦环境、材质、约束关系稍微变形,性能就会断崖式下滑。
这就好比让一个人在不理解几何原理的情况下,去死记硬背一万道几何题的答案。遇到原题,他能快速写出完美答案;遇到条件稍微变动的新题,他就彻底宕机。
VLA的泛化,本质上只是高维语义空间中的插值。当物理形态超出训练集的包络面时,插值就会失效。
与之对比的,是视频生成模型。在Veo3、Sora 2和最近大火的Seedance 2生成的物理交互画面已经相当逼真,流体、刚体、柔性材料的动作如此连贯,几乎与现实世界难以区分。这说明,大规模视频生成模型在海量的互联网视频中,很可能已经隐式地压缩并内化了物理世界的基础运行规律,形成了一些世界模型。
即使强大如斯,视频生成之前仍然主要被用在给VLA提供模拟数据,而不是整合进机器人的工作流中。
其实,大家想利用视频生成模型来控制机器人的念头并不是从此开始的。在DreamZero之前,学术界和工业界也提出了多个解决方法。但这些方法无一例外地陷入了工程和逻辑的死胡同。
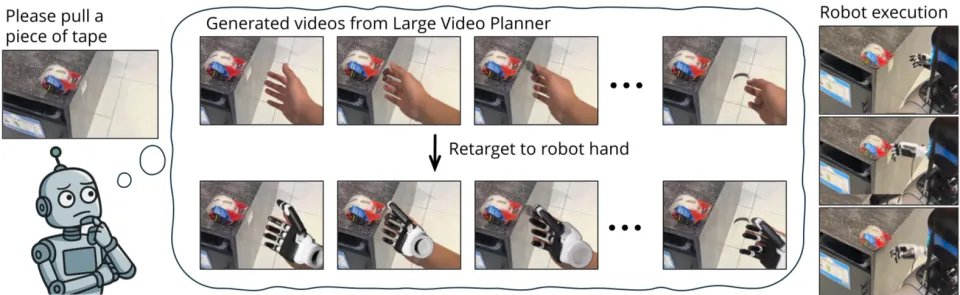
比如 LVP(大规模视频规划器)。它的思路是从一张图和一句话,直接生成应该如何完成任务的未来视频计划。再把视频中的人手运动重建成 3D 轨迹。是用视频预训练,而不是语言预训练,作为机器人基础能力的主轴。
第二种则是类似英伟达自己的DreamGen这种,生成视频后,再反推动作。这是之前被寄予厚望的路线。它把整个基础模型的架构切分为两半,上半部分是一个视频模型,负责预测未来;下半部分是一个独立训练的IDM网络,负责看着预测出来的视频,反推并输出动作。
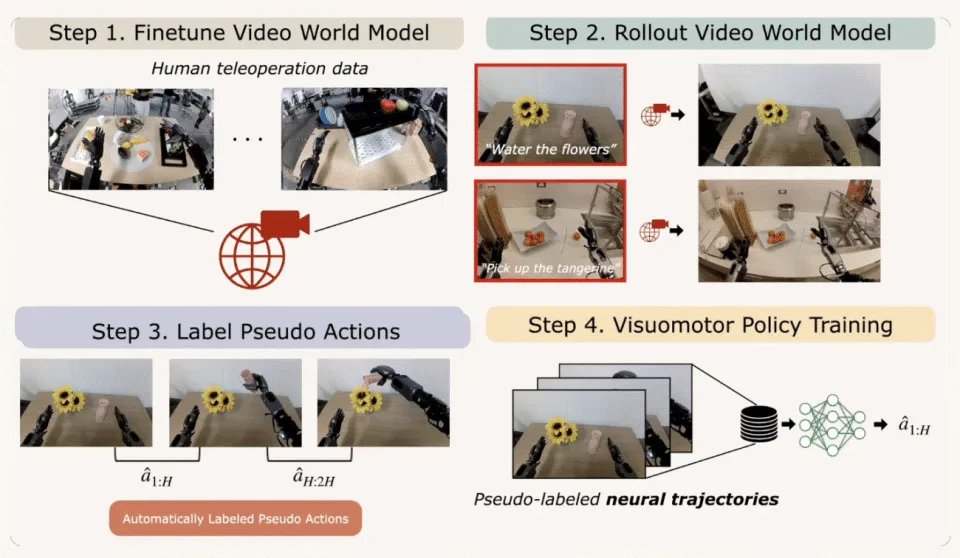
以上两种分阶段的模式,最大的问题就是动作和视频生成对不齐。动作那块要求特别准确,但视频生成很难完美。一旦它产生的未来画面带有微小的像素伪影或物理幻觉,那不管是IDM或者点追踪,都直接懵圈,成倍放大错误。视频里机器人的手指位置偏了一微米,现实中机器人就根本什么都抓不住了。鲁棒性极差。
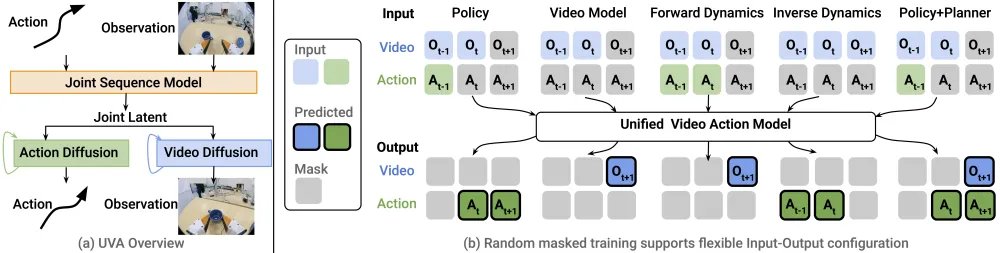
第三种是Unified Video-Action(UVA,联合视频-动作生成)。这算是最先进的方法了,它尝试把视频和动作放在同一个扩散模型里的潜空间里学习,兼顾了视频预测和动作预测。而推理时又通过“解码解耦”跳过视频生成,以保证速度。但它的架构使用了双向扩散(Bidirectional Diffusion)架构。为了匹配语言指令的长度,必须对生成的视频序列进行大幅压缩。这种做法彻底扭曲了原生的视频时间流。时间都扭曲了,动作指令与视觉画面的对齐几乎就不可能了,所以这种方式的泛化性自然极差。
除此之外,这些方法都有一个致命的共同缺陷,就是太慢。视频扩散模型需要多步迭代去噪,生成几秒钟的动作往往需要几十秒的计算。要是一个机器人把碗放进碗柜要5分钟,你怕是在边上看着都得急疯。
因此在2026年前所有新具身智能企业中,几乎只有前一阵刚推出家用机器人的1X Technologies在尝试这种视频预测的方法。他们利用海量的“影子模式”(Shadow Mode)数据,即在人类遥操作时,让模型在后台同步运行预测,用这种极高质量的配对数据去硬生生训练那个脆弱的IDM。
但一时的失败,并不意味着方向被否定。
在去年的机器人大会上,我采访了很多国内的具身智能学者。彼时正是谷歌 Veo 3和 Genie 3刚刚发布不久之时。大多数学者都对此印象深刻,意识到了视频生成模型的世界理解能力。
因此在交流中,他们几乎是以一种共识的口吻,提出生成可能是后续具身智能最靠谱的路径。这比在模拟环境下(Simulation)产生数据要可能性更高。模拟器(如Isaac Gym或MuJoCo)受限于人类硬编码的物理引擎,永远无法穷尽真实世界材质的复杂性、光影的多变性和接触力的非线性。而吸收了全人类视频数据的生成模型,才是那个真正包含了万物物理法则的超级模拟器。
但当时,这个思维还是停留在“数据”这个层面上,视频生成取代VLA这个讲法,基本还没进入视野。
但英伟达的研究,很可能就是让这个想法,第一次变成有效的工程化路径的转折点。
DreamZero,以世界模型为基地的具身智能
前面已经讲了,过去利用视频生成模型去构建机器人动作所面对的三个主要问题。
一是分步导致的对齐问题。二是合一模式太差,没法用的问题。三是太慢的问题。针对于此,英伟达先用DreamZero,给出了一条解决方法。
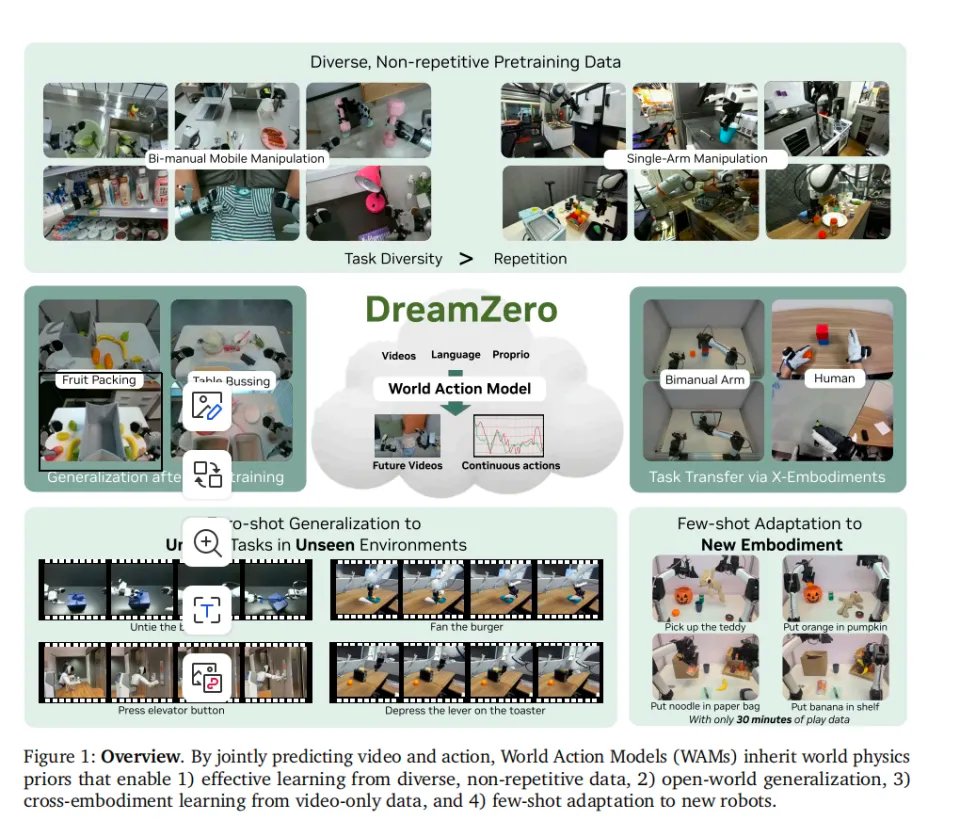
首先,DreamZero采用了视频和动作预测同步端到端训练的方式。这就解决了过去分阶段模式的不对齐问题。
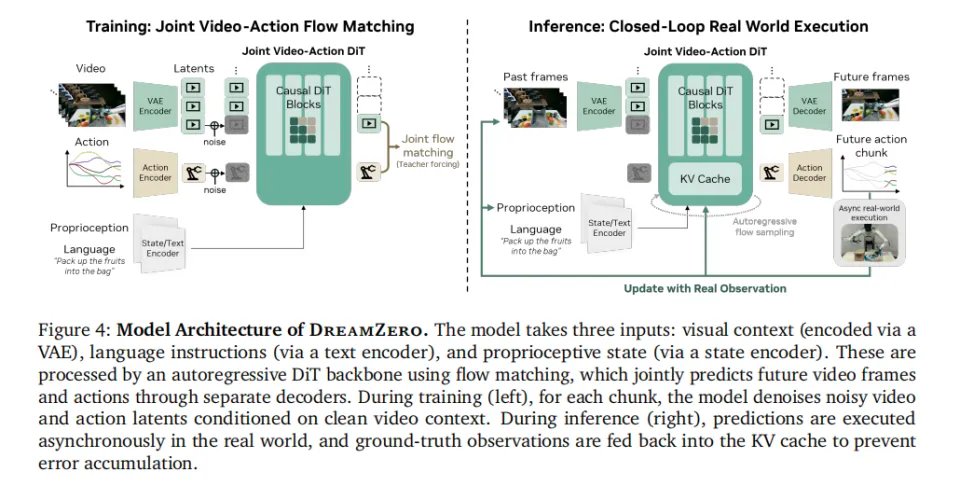
其次,针对UVA的时空错乱问题,DreamZero彻底抛弃了早期的双向架构,转而构建了一个14B参数的自回归 Diffusion Transformer (DiT)。这是目前标准的视频生成模型架构。它像语言模型生成文本一样,严格按照时间顺序,从左到右预测视频和动作。在同一次扩散前向里,同时预测视频与动作。
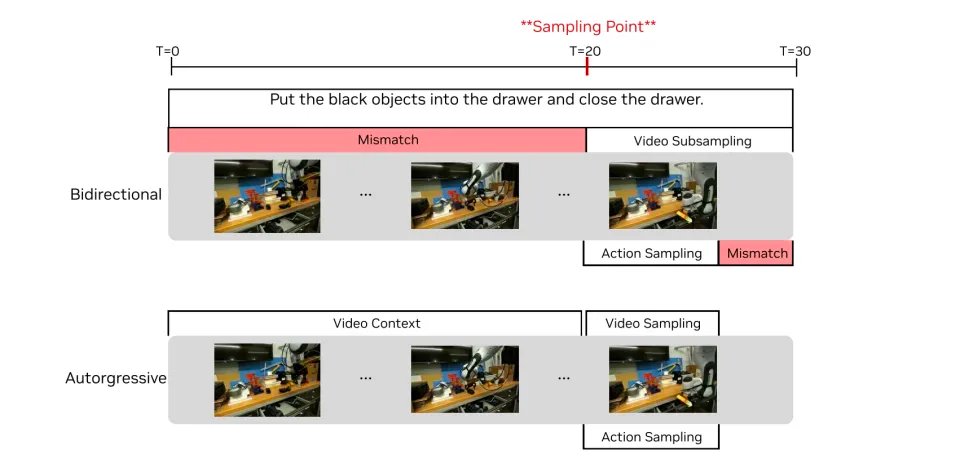
这带来了两个好处。第一,保留了原生帧率,动作和画面在时间轴上实现了绝对对齐。第二,它利用了KV Cache(键值缓存)技术。模型不需要每次都从头计算历史画面,极大地节省了算力。
之后,为了解决自回归导致的“误差累积”和幻觉问题。DreamZero还引入了真实观测注入。
模型预测出未来1.6秒的画面和动作,机器人执行完毕。而在动作执行完的瞬间,获取摄像头拍下的绝对真实的当前物理世界画面,直接编码并塞入KV Cache,覆盖、替换掉模型刚才生成的假画面。
这一步,瞬间斩断了误差积累的因果链。模型被迫永远站在绝对真实的物理基石上,去思考下一步。
最后,也是最重要的一步,是解决生成慢的问题。
为了达到机器人控制需要的频率,DreamZero发明了DreamZero-Flash技术。扩散模型慢,是因为推理时需要走完漫长的去噪链。如果强行减少步数(比如只用1步去噪),生成的动作质量会断崖式下跌,因为画面还处在充满噪点的模糊状态,模型无法从中提取精确的动作。
DreamZero-Flash的解法是“解耦噪声调度”。在训练时,它不再让视频和动作处于相同的噪声级别。它强制模型看着极度模糊、充满高强度噪声的视觉画面,去预测完全干净、精准的动作信号。这等于是在训练模型在看不清未来的情况下,凭借物理直觉做出正确反应。
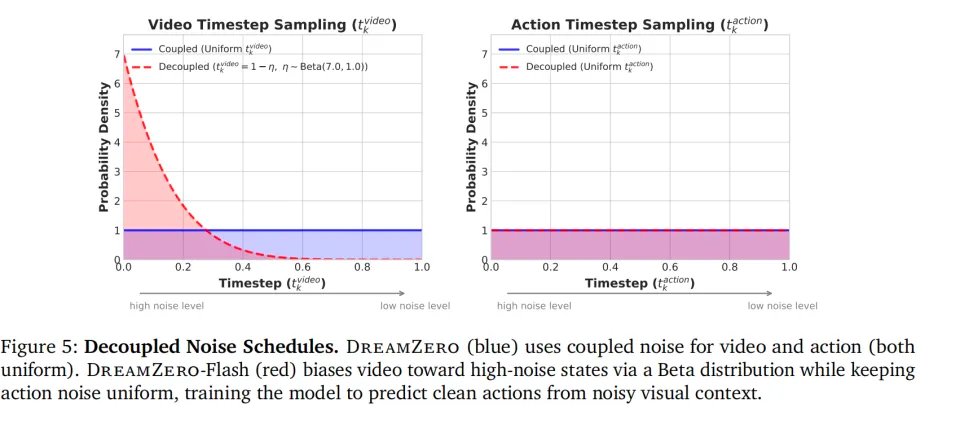
对于人来讲,这是不可能的任务,看不清就是做不了动作。但对模型来讲,这似乎完全行得通。经过这一训练,到了推理阶段,模型只需要进行仅仅1步去噪就能生成准确动作。推理时间从350毫秒瞬间压缩到了150毫秒。
这使得系统能够以7Hz的频率输出动作块,结合底层控制器,实现了相对平滑的实时执行。
经过了这一系列改造。DreamZero展现出了视频生成世界模型的恐怖潜力。
最突出的是泛化能力。在AgiBot双臂机器人的测试中,研究人员抛出了训练集里完全没有见过的任务解开打结的鞋带、从假人模型头上摘下帽子、拿着刷子画画。
让从头训练的VLA来做,任务进度几乎为零,开始的地方都做不好。但DreamZero的平均任务进度达到了39.5%,某些特定任务(如摘帽子)甚至高达85.7%。
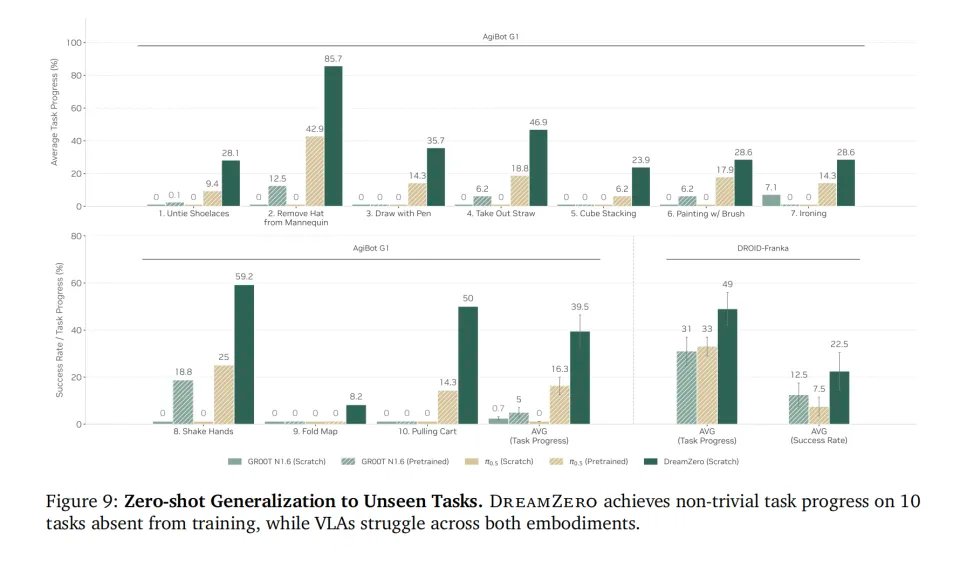
这是因为DreamZero的学习过程是颠覆性的。在训练时联合预测视频和动作,它被迫在潜空间中建立事物演变的因果链条。它知道如果不松开夹爪,被夹住的物体就不会掉落;它知道如果向前推倒一杯水,水会洒出来。
因为预设了基于视频的世界模型,WAMs拥有了物理直觉。当遇到未见过的任务时,它不是在记忆库里搜索类似的动作,而是在脑海中模拟出了动作的物理后果。只要这个物理后果符合语言指令的语义目标,它就能直接涌现出执行动作。
这就是为什么它能在Zero-shot的情况下完成解鞋带这种复杂任务。
更让人震撼的是跨机体(Cross-Embodiment)能力。
在传统的VLA范式下,你要让一台新形态的机器人干活,就必须雇人去给这台机器人录制专属的遥操作数据。但在DreamZero中,研究人员只让模型观看了人类视角的录像(纯视频,没有任何电机动作参数),仅仅看了12分钟。模型在未见任务上的表现就实现了42%的相对提升。
随后,他们把在AgiBot上训练的模型,直接迁移到一台完全不同的YAM机器人上。仅仅给它喂了30分钟的非结构化“玩耍数据”(Play Data),模型就完成了躯体适应,并且完美保留了零样本泛化执行复杂指令的能力。
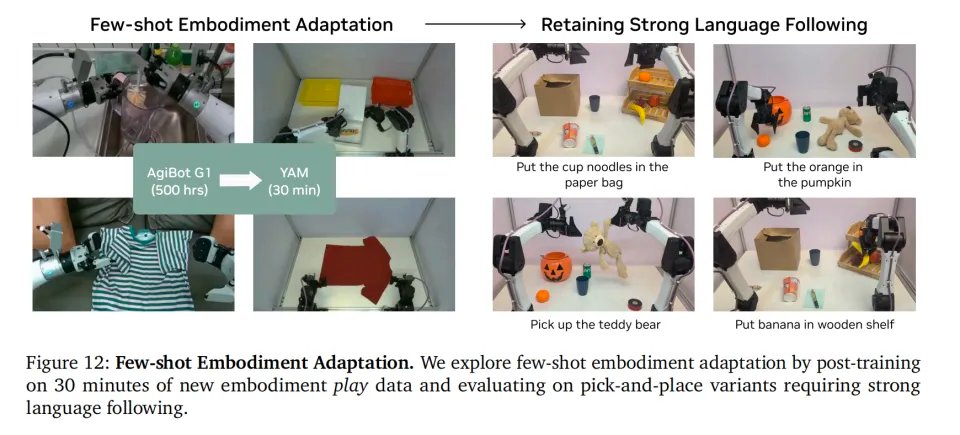
这就是世界模型的降维打击。物理规律是通用的,它只需要极少的数据去微调自己对新躯体运动学边界的认知。
VLA最大的问题,DreamZero这样预设了世界模型的动作模型 WAM(World Action Model)完美解决了。它不需要海量的机器人数据训练就能达成很好的泛化。
但我们必须保持清醒。基于视频生成的工程化路径,其实依然有很多卡点。
相对于VLA动辄在消费级显卡上跑出20Hz、30Hz的惊人速度,DreamZero拼尽全力优化后的7Hz依然很慢。并且,它对硬件要求更高,依赖于H100或GB200这样的顶级芯片组成的计算集群来进行并行推理。对于边缘端部署的独立机器人来说,这在目前的算力成本下是不可接受的。
不过,算力成本的下降服从摩尔定律,而算法架构的物理认知上限则是天花板。用昂贵的算力去换取原本根本不存在的泛化能力,这笔交易在技术演进的长期视角下是绝对划算的。
DreamZero的成功,意味着从VLA转向视频世界模型,不再是一个学术幻想,而是一个已经跑通的可能。
世界模型需要的数据,和VLA不一样
在 DreamZero 的实验中,英伟达发现了一个反直觉的结论。
我们通常认为数据越多越好。如果机器人学不会,那就再采集一万小时数据。 但在世界模型的语境下,这个定律失效了。
DreamZero 揭示了新的法则 数据多样性 > 数据重复量。
研究人员做了一组对照实验 ,准备了两份数据,总时长都是 500 小时。
数据集 A(重复组):包含 70 个任务,每个任务有大量重复的演示,位置和环境变化很小。这是传统 VLA 喜欢的“刷题”模式。
数据集 B(多样组):包含 22 个不同环境、数百个任务,数据极其杂乱,几乎不重复。
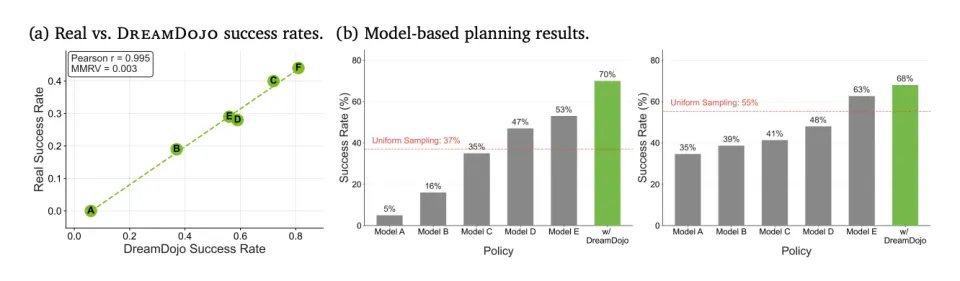
结果使用杂乱数据训练的 DreamZero,在未见任务上的泛化成功率达到了 50%。 而使用精美重复数据训练的模型,成功率只有 33%。
为什么? 这是因为 VLA 和 WAM 的学习逻辑根本不同。 VLA 是在背诵。WAM 是在学物理。
DreamZero 证明了对于学习物理规律而言,看 1 次在火星上煎蛋,比看 1000 次在厨房里煎蛋更有价值。
因为前者提供了新的物理边界条件,而后者只是在通过重复增加冗余。世界模型需要的是覆盖率,而不是重复率。
下一步,是把世界模型训练的更好
DreamZero 的意义,是证明了WAM这条路完全能走通,还能非常好的泛化。
但想要持续提升DreamZero这样模型的能力,我们还需要对它加以训练。尽可能强化它基于视频生成的世界模型,最好还有个更严格的后验裁判,能够指导它在后训练中持续提升准确性。
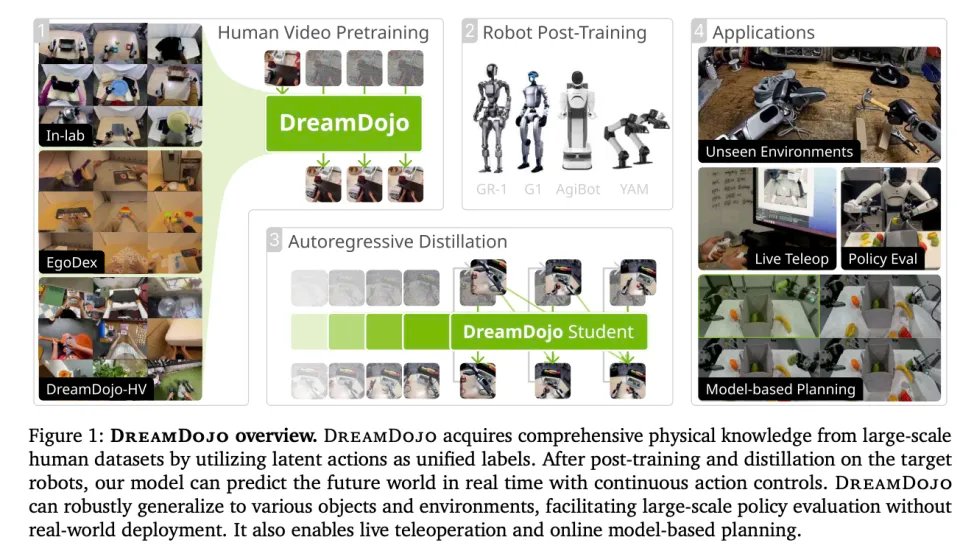
这就是另一篇论文中 Dream Dojo 的作用。DreamZero 造出了引擎,DreamDojo 炼出了持续优化这个引擎的燃油。
正如其名,它像是一座道场,要把世界模型训练这件事,从DreamZero这种一次性的科研 demo,丰富成一套可重复的工业流程。这套流程涵盖了从数据摄入、表征对齐,到滚动预测、误差诊断的全生命周期。
在 DreamDojo 出现之前,VLA(视觉-语言-动作)模型在数据上总是碰壁,面临三重死穴。
1. 标签稀缺:互联网视频浩如烟海,但只有画面,没有动作数据(Action Labels)。
2. 工程地狱:机器人的身体千奇百怪。不同的自由度(DOF)、不同的控制频率、不同的接口格式。试图统一这些数据,是工程师的噩梦。
3. 不可控:很多模型生成的视频看着像,但在物理因果上是错的。如果动作和后果不对齐,模型就无法进行反事实(Counterfactual)推演。无法推演,就无法规划。
但现在,因为有了视频生成模型,这些就都不是问题了。DreamDojo 不是从零做 world model,它是站在“视频基础模型已经把世界的视觉与时空规律学到一定程度”的台阶上,再强化对于具身智能来讲,至关重要的交互因果和可控性。
既然人类视频里没有电机数据,那我们就不要电机数据了。
DreamDojo 不再执着于传感器里的读数,而是去寻找动作的物理本质。动作,本质上就是一种让世界状态发生改变的力。
DreamDojo 设计了一个自监督编码器,专门盯着视频的前后帧看。它在不断地问自己一个问题,到底是什么力量,让上一帧变成了下一帧?
机器自动提取出来的这个答案,就是连续潜在动作。
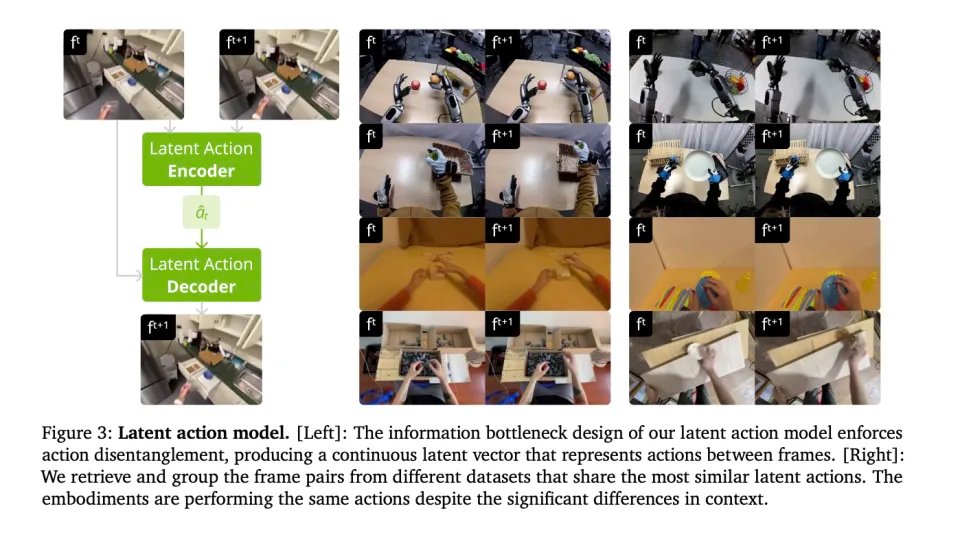
DreamDojo 不再记录绝对的关节姿态。因为绝对姿态在高维空间里太稀疏、太难学。 它记录的是变化量。每一帧都以当前状态为基准归零。这让动作的分布变得更窄、更集中,模型更容易学会向左移一点这种通用的物理规律,而不是死记坐标。
这就好比不需要知道一个人用了哪块肌肉(传感器数据),只要看他挥手砸杯子,杯子碎了,模型提取出挥手击碎这个潜在动作的整个过程。
同时,为了增强可控性。DreamDojo 不把整段动作轨迹当作全局条件灌进去,而是把连续 4 个动作拼成 chunk,只注入到对应的 latent frame。通过这样的拆分,模型被强制要求理解是这一个微小的动作切片,导致了下一刻的画面变化。让世界模型不会造成因果混淆。
视频模型在这个过程中,把训练目标从预测未来像不像,推向动作改变未来的方向与幅度是否一致。
这彻底打通了不同具身体之间物种隔离。 不同身体、不同场景做同一种动作,潜动作会趋于相近。模型不再需要知道手肘电机转动 30 度,它只需要知道这个潜在动作会导致杯子被拿起。
而因为这个潜空间的动作规律对谁都一样,不存在空间异构,不存在数据格式不通。
DreamDojo 在视频生成这个世界模型的基础上,用连续潜在动作这个数学上的通用语,把全人类的视频资产转换成了机器人可以理解的经验。
为了达成这个目标,英伟达团队构建了一个 DreamDojo-HV(加上 In-lab 与 EgoDex)的数据集,是一个约 44,711 小时的第一视角人类交互混合数据集,覆盖极其广的日常场景与技能分布。包含上万级场景、数千级任务、数万级对象的长尾分布。
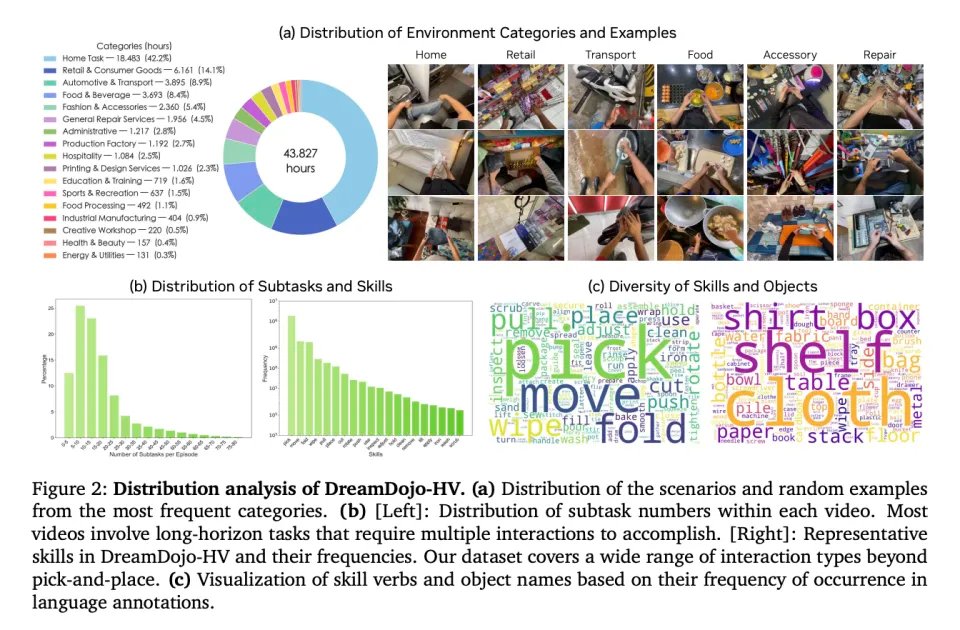
这个规模,比之前最大的机器人世界模型数据集大了 15 倍,场景丰富度高了 2000 倍。
结果 DreamDojo 在没见过任何真机器人的情况下,仅凭看人类视频预训练,就能在极少量的微调后,操控真机器人完成从未见过的任务。再通过蒸馏技术,他们把这个庞大的世界模型压缩到了能跑 10 FPS 的实时速度。
至此,结合Dream Dojo和DreamZero,这套建立在世界模型上的具身智能的闭环终于合上了。
它的底座是视频生成模型,因为它懂物理。构架是DreamZero 代表的世界动作模型(WAM),它能通过预测未来来决策,而且让可执行与低延迟够薄,能用。而其进步的燃料,是DreamDojo 把物理与可检验性做厚,让全网的人类视频,通过潜在动作转化为机器人的经验。
我们不再需要让几万个博士去遥操作机器人了。只要让机器人坐在那里,日夜不停地看人类干活的视频,它就能学会关于物理世界的一切。
这,很可能是具身智能的范式转变
DreamZero的出现,敲响了具身智能纯VLA时代的丧钟。
这场范式的转变可能,将深刻地重塑整个行业的生态。
首先是数据采集哲学的颠覆。在VLA范式下,从业者陷入了遥操作数据的囚徒困境,认为只有花重金采集几万小时的精准动作配对数据,机器人才能变聪明。但DreamZero展示了跨机体学习的恐怖潜力,仅仅通过观看人类行为的纯视频,模型就能汲取物理策略。
而Dream Dojo则意味着,YouTube、TikTok上那数以百亿计的人类生活视频,那座原本被认为缺乏动作标签而对机器人无用的数据金矿,将被彻底解锁。
从高成本的实体遥操作,转向低成本的互联网视频挖掘,这是获取常识的降维打击。
最重要的是,我们对机器智能的认知正在发生根本性转移。
VLA时代,我们试图通过教会机器认字来让它干活,结果得到了一个笨拙的翻译官。现在,我们开始教会机器做梦,在脑海中生成、预测、模拟物理世界的演变。
当一台机器不再是机械地复读数据,而是能够在内部构建一个符合物理定律的微缩宇宙,并在其中推演自己的行为后果时,我们就已经站在了通用具身智能的真正起点上。
这是一条更陡峭的路径,但也必定通往更广阔的未来。