知网已删,此地独存:协和4+4之董袭莹博士论文
2025-05-04 22:25:36 · chineseheadlinenews.com · 来源: 中国数字时代
北京协和医学院临床医学专业毕业论文
学校代码:10023
学 号: B2019012012
跨模态图像融合技术在医疗影像分析中的研究
专业年级:北京协和医学院临床医学专业 2019 级试点班
姓名: 董袭莹
导师: 邱贵兴(教授)
北京协和医学院 临床学院(北京协和医院)
骨科
完成日期:2023年5月
目录
摘要 …………………………………………………………………………………………………………………… 1
Abstract ………………………………………………………………………………………………………………. 3
基于特征匹配的跨模态图像融合的宫颈癌病变区域检测 ………………………………… 6
1.1. 前言 …………………………………………………………………………………………………….. 6
1.2. 研究方法 ……………………………………………………………………………………………… 7
1.2.1. 研究设计和工作流程 ………………………………………………………………….. 7
1.2.2. 跨模态图像融合 …………………………………………………………………………. 7
1.2.3. 宫颈癌病变区域检测 ………………………………………………………………… 11
1.3. 实验 …………………………………………………………………………………………………… 11
1.3.1. 临床信息和影像数据集 …………………………………………………………….. 11
1.3.2. 模型训练过程 …………………………………………………………………………… 12
1.3.3. 评价指标 ………………………………………………………………………………….. 13
1.3.4. 目标检测模型的结果与分析 ……………………………………………………… 14
1.4. 讨论 …………………………………………………………………………………………………… 15
1.5. 结论 …………………………………………………………………………………………………… 16
基于特征转换的跨模态数据融合的乳腺癌骨转移的诊断 ………………………………. 18
2.1. 前言 …………………………………………………………………………………………………… 18
2.2. 研究方法 ……………………………………………………………………………………………. 19
2.2.1. 研究设计和工作流程 ………………………………………………………………… 19
2.2.2. 骨转移目标区域检测 ………………………………………………………………… 20
2.2.3. 基于特征转换的跨模态数据融合 ………………………………………………. 20
2.2.4. 乳腺癌骨转移的分类模型 …………………………………………………………. 21
2.3. 实验 …………………………………………………………………………………………………… 22
2.3.1. 临床信息和影像数据集 …………………………………………………………….. 22
2.3.2. 模型训练过程 …………………………………………………………………………… 23
2.3.3. 评价指标 ………………………………………………………………………………….. 24
2.3.4. 单模态骨转移灶检测模型及基于特征转换的跨模态分类模型的结果与分析 ……………………………………………………………………………………………….. 25
2.4. 讨论 …………………………………………………………………………………………………… 30
2.5. 结论 …………………………………………………………………………………………………… 32
全文小结 ………………………………………………………………………………………………………….. 33
参考文献 ………………………………………………………………………………………………………….. 35
缩略词表 ………………………………………………………………………………………………………….. 40
文献综述 ………………………………………………………………………………………………………….. 41
跨模态深度学习技术在临床影像中的应用 ……………………………………………………. 41
3.1 Preface ………………………………………………………………………………………………… 41
3.2. Deep Neural Network (DNN) ……………………………………………………………….. 42
3.2.1. Supervised learning ……………………………………………………………………. 43
3.2.2. Backpropagation ………………………………………………………………………… 46
3.2.3. Convolutional neural networks (CNN) …………………………………………. 46
3.3. Cross-modal fusion ………………………………………………………………………………. 49
3.3.1. Cross-modal fusion methods ……………………………………………………….. 50
3.3.2. Cross-modal image translation …………………………………………………….. 51
3.4. The application of cross-modal deep learning ………………………………………….. 52
3.5. conclusion …………………………………………………………………………………………… 55
参考文献 …………………………………………………………………………………………………… 57
致谢 …………………………………………………………………………………………………………………. 60
独创性声明 ………………………………………………………………………………………………………. 61
学位论文版权使用授权书 …………………………………………………………………………………. 61
摘要
背景
影像学检查是医疗领域最常用的筛查手段,据统计,医疗数据总量中有超过90%是由影像数据构成[1]。然而,根据亲身参与的临床病例[2]可知,很多情况下,仅凭医生的肉眼观察和主观诊断经验,不足以对影像学异常作一明确判断。而诊断不明引起的频繁就医、暄腆病情,则会严重影响患者的生活质量。
相较于传统的主观阅片,人工智能技术通过深度神经网络分析大量影像和诊断数据,学习对病理诊断有用的特征,在客观数据的支持下做出更准确的判断。为了模拟临床医生结合各种成像模式(如 CT、MRI 和 PET)形成诊断的过程,本项目采用跨模态深度学习方法,将各种影像学模态特征进行有机结合,充分利用其各自的独特优势训练深度神经网络,以提高模型性能。鉴于肿瘤相关的影像学资料相对丰富,本项目以宫颈癌和乳腺癌骨转移为例,测试了跨模态深度学习方法在病变区域定位和辅助诊断方面的性能,以解决临床实际问题。
方法
第一部分回顾性纳入了220 例有FDG-PET/CT 数据的宫颈癌患者,共计72,602张切片图像。应用多种图像预处理策略对PET 和CT 图像进行图像增强,并进行感兴趣区域边缘检测、自适应定位和跨模态图像对齐。将对齐后的图像在通道上级联输入目标检测网络进行检测、分析及结果评估。通过与使用单一模态图像及其他 PET-CT 融合方法进行比较,验证本项目提出的 PET-CT 自适应区域特征融合结果在提高模型目标检测性能方面具有显著性优势。第二部分回顾性纳入了233 例乳腺癌患者,每例样本包含 CT、MRI、或 PET 一至三种模态的全身影像数据,共有3051 张CT 切片,3543 张MRI 切片,1818 张PET 切片。首先训练YOLOv5 对每种单一模态图像中的骨转移病灶进行目标检测。根据检测框的置信度划分八个区间,统计每个影像序列不同置信度区间中含有检出骨转移病灶的个数,并以此归一化后作为结构化医疗特征数据,采用级联方式融合三种模态的结构化特征实现跨模态特征融合。再用多种分类模型对结构化数据进行分类和评估。将基于特征转换的跨模态融合数据与特征转换后的单模态结构化数据,以及基于 C3D 分类模型的前融合方式进行比较,验证第二部分提出的方法在乳腺癌骨转移诊断任务中的优越性能。
结果
第一部分的基于跨模态融合的肿瘤检测实验证明,PET-CT 自适应区域特征融合图像显著提高了宫颈癌病变区域检测的准确性。相比使用CT 或PET 单模态图像以及其他融合方法生成的多模态图像作为网络输入,目标检测的平均精确度分别提高了 6.06%和 8.9%,且消除了一些假阳性结果。上述测试结果在使用不同的目标检测模型的情况下保持一致,这表明自适应跨模态融合方法有良好的通用性,可以泛化应用于各种目标检测模型的预处理阶段。第二部分基于特征转换的跨模态病例分类实验证明,跨模态融合数据显著提高了乳腺癌骨转移诊断任务的性能。相较于单模态数据,跨模态融合数据的平均准确率和AUC分别提高了7.9%和8.5%,观察 ROC 曲线和 PR 曲线的形状和面积也具有相同的实验结论:在不同的分类模型中,使用基于特征转换的跨模态数据,相比单模态数据,对于骨转移病例的分类性能更为优越。而相较于基于 C3D 的前融合分类模型,基于特征转换的后融合策略在分类任务方面的性能更优。
结论
本项目主要包含两个部分。第一部分证实了基于区域特征匹配的跨模态图像融合后的数据集在检测性能上优于单模态医学图像数据集和其他融合方法。第二部分提出了一种基于特征转换的跨模态数据融合方法。使用融合后的数据进行分类任务,其分类性能优于仅使用单模态数据进行分类或使用前融合方法的性能。根据不同模态医学图像的特征差异与互补性,本项目验证了跨模态深度学习技术在病变区域定位和辅助诊断方面的优势。相比于只使用单模态数据进行训练的模型,跨模态深度学习技术有更优的诊断准确率,可以有效的成为临床辅助工具,协助和指导临床决策。
关键词:跨模态融合,深度学习,影像分析,宫颈癌,乳腺癌骨转移
Abstract
Background
Imaging examinations serve as the predominant screening method in the medical field. As statistics reveal, imaging data constitute over 90% of the entire medical dataset. Nonetheless, clinical cases have demonstrated that mere subjective diagnoses by clinicians often fall short in making definitive judgments on imaging anomalies. Misdiagnoses or undiagnosed conditions, which result in frequent hospital visits and delayed treatment, can profoundly affect patients’ quality of life.
Compared to the traditional subjective image interpretation by clinicians, AI leverages deep neural networks to analyze large-scale imaging and diagnostic data, extracting valuable features for pathology diagnosis, and thus facilitating more accurate decision-making, underpinned by objective data. To emulate clinicians’ diagnostic process that integrates various imaging modalities like CT, MRI, and PET, a cross-modal deep learning methodology is employed. This approach synergistically merges features from different imaging modalities, capitalizing on their unique advantages to enhance model performance.
Given the ample availability of oncologic imaging data, the project exemplifies the efficacy of this approach in cervical cancer segmentation and detection of breast cancer bone metastasis, thereby addressing pragmatic challenges in clinical practice.
Methods
The first part retrospectively analyzed 72,602 slices of FDG-PET/CT scans from 220 cervical cancer patients. Various preprocessing strategies were applied to enhance PET and CT images, including edge detection, adaptive ROI localization, and cross-modal image
fusion. The fused images were then concatenated on a channel-wise basis and fed into the object detection network for the precise segmentation of cervical cancer lesions. Compared to single modality images (either CT or PET) and alternative PET-CT fusion techniques,
the proposed method of PET-CT adaptive fusion was found to significantly enhance the object detection performance of the model. The second part of the study retrospectively analyzed 3,051 CT slices, 3,543 MRI slices and 1,818 PET slices from 233 breast cancer patients, with each case containing whole-body imaging of one to three modalities (CT, MRI, or PET). Initially, YOLOv5 was trained to detect bone metastases in images across different modalities. The confidence levels of the prediction boxes were segregated into eight tiers, following which the number of boxes predicting bone metastases in each imaging sequence was tallied within each confidence tier. This count was then normalized and utilized as a structured feature. The structured features from the three modalities were fused in a cascaded manner for cross-modal fusion. Subsequently, a variety of classification models were then employed to evaluate the structured features for diagnosing bone metastasis. In comparison to feature-transformed single-modal data and the C3D early fusion method, the cross-modal fusion data founded on feature transformation demonstrated superior performance in diagnosing breast cancer bone metastasis.
Results
The first part of our study delivered compelling experimental results, showing a significant improvement in the accuracy of cervical cancer segmentation when using adaptively fused PET-CT images. Our approach outperformed other object detection algorithms based on either single-modal images or multimodal images fused by other methods, with an average accuracy improvement of 6.06% and 8.9%, respectively, while also effectively mitigating false-positive results. These promising test results remained consistent across different object detection models, highlighting the robustness and universality of our adaptive fusion method, which can be generalized in the preprocessing stage of diverse object detection models. The second part of our study demonstrated that cross-modal fusion based on feature transformation could significantly improve the performance of bone metastasis classification models. When compared to algorithms employing single-modal data, models based on cross-modal data had an average increase in accuracy and AUC of 7.9% and 8.5%, respectively. This improvement was further corroborated by the shapes of the ROC and PR curves. Across a range of classification models, feature-transformed cross-modal data
consistently outperformed single-modal data in diagnosing breast cancer bone metastasis. Moreover, late fusion strategies grounded in feature transformation exhibited superior performance in classification tasks when juxtaposed with early fusion methods such as C3D.
Conclusions
This project primarily consists of two parts. The first part substantiates that deep learning object detection networks founded on the adaptive cross-modal image fusion method outperform those based on single-modal images or alternative fusion methods. The second part presents a cross-modal fusion approach based on feature transformation. When the fused features are deployed for classification models, they outperform those utilizing solely single-modal data or the early fusion model. In light of the differences and complementarity in the features of various image modalities, this project underscores the strengths of cross-modal deep learning in lesion segmentation and disease classification. When compared to models trained only on single-modal data, cross-modal deep learning offers superior diagnostic accuracy, thereby serving as an effective tool to assist in clinical decision-making.
Keywords: cross-modal fusion, deep learning, image analysis, cervical cancer, breast cancer bone metastasis
1. 基于特征匹配的跨模态图像融合的宫颈癌病变区域检测
1.1. 前言
宫颈癌是女性群体中发病率第四位的癌症,每年影响全球近 50 万女性的生命健康[3] 。准确和及时的识别宫颈癌至关重要,是否能对其进行早期识别决定了治疗方案的选择及预后情况[4]。氟代脱氧葡萄糖正电子发射计算机断层显像/电子计算机断层扫描(fluorodeoxyglucose-positron emission tomography/computed tomography, FDG-PET/CT),因其优越的敏感性和特异性,成为了一个重要的宫颈癌检测方式[5] 。由于CT 能够清晰地显示解剖结构,FDG-PET 能够很好地反映局灶的代谢信息形成功能影像,FDG-PET/CT 融合图像对可疑宫颈癌病灶的显示比单独使用高分辨率 CT 更准确,特别是在检测区域淋巴结受累和盆腔外病变扩展方面[6] ,[7] ,[8] 。然而,用传统方法为单一患者的 FDG-PET/CT 数据进行分析需要阅读数百幅影像,对病变区域进行鉴别分析,这一极为耗时的过程已经妨碍了临床医生对子宫颈癌的临床诊断。
随着计算机硬件和算法的进步,尤其是以深度学习[9] 、图像处理技术[10] ,[11] 为代表的机器学习技术的革新,这些人工智能算法在临床医学的许多领域中起着关键作用[12]。基于其强大有效的特征提取能力[13] ,[14] ,深度学习中的卷积神经网络可以通过梯度下降自动学习图像中的主要特征[15 ,极大地提高目标识别的准确性 [16],使深度学习成为计算机图像处理领域的主流技术[17] ,[18]。利用深度学习技术对宫颈癌影像进行分析可以辅助临床医生做出更为准确的判断,减轻临床医生的工作负担,提高诊断的准确性[19]。
目前已经有很多在单一模态图像中(CT 或 PET)基于深度学习技术进行病变检测的工作:Seung等使用机器学习技术依据PET图像对预测肺癌组织学亚型[20];Sasank 进行了基于深度学习算法检测头 CT 中关键信息的回顾性研究[21];Chen 使用随机游走(random walk)和深度神经网络对 CT 图像中的肺部病变进行分割[22] ,[23]。但很少有关于使用跨模态图像融合深度学习方法进行病变检测的研究。
基于 PET/CT 融合图像的病变检测项目包括三个研究任务:区域特征匹配[24],跨模态图像融合[25 和目标病变区域检测[26]。Mattes 使用互信息作为相似性标准,提出了一种三维PET 向胸部CT 配准的区域特征匹配算法[27]。Maqsood 提出了一种基于双尺度图像分解和稀疏表示的跨模态图像融合方案[28]。Elakkiya 利用更快的基于区域的卷积神经网络(Faster Region-Based Convolutional Neural Network, FR-CNN)进行颈部斑点的检测[29]。目前还没有将上述三个研究任务,即区域特征匹配、跨模态图像融合、病变区域检测任务,结合起来的研究工作。
为了减轻临床医生的工作负担,基于跨模态深度学习方法,本项目的第一部分提出了一个统一的多模态图像融合和目标检测框架,用于宫颈癌的检测。
1.2. 研究方法
1.2.1. 研究设计和工作流程
本项目旨在检测 CT 和 PET 图像中宫颈癌的病变区域,工作流程如图 1-1 所示:扫描设备对每位患者进行PET 和CT 图像序列的采集;通过区域特征匹配和图像融合来合成清晰且信息丰富的跨模态图像融合结果;采用基于深度学习的目标检测方法在融合图像中对可疑宫颈癌的病变区域进行目标检测。在图 1-1 的最后一行中,矩形框出的黄色区域及图中右上角放大的区域中展示了检测出的宫颈癌病变区域。
图 1-1 工作流程
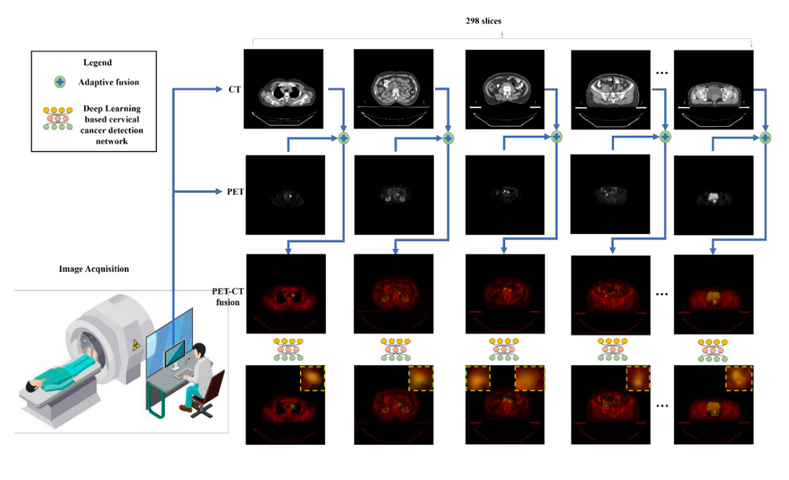
1.2.2. 跨模态图像融合
图 1-2 展示了跨模态图像融合算法的流程图。根据计算发现两种模态图像的比例和位置不同,如仅进行简单的融合会错误地将处于不同位置的组织影像重叠,从而使组织发生错位,定位不准,产生不可接受的误差。因此,第一部分提出了一种跨模态图像融合策略,其中的步骤包括对感兴趣区域(region of interest, ROI)的自适应定位和图像融合。
在PET 和CT 图像中,自适应ROI定位能够精准识别待分析处理的关键目标,即人体组织影像,然后计算不同模态图像下组织影像之间的比例和位移。依据上述计算结果通过缩放、填充和裁剪的方式来融合 PET 和CT 图像。
图 1-2 CT 和PET 跨模态图像融合算法的流程图
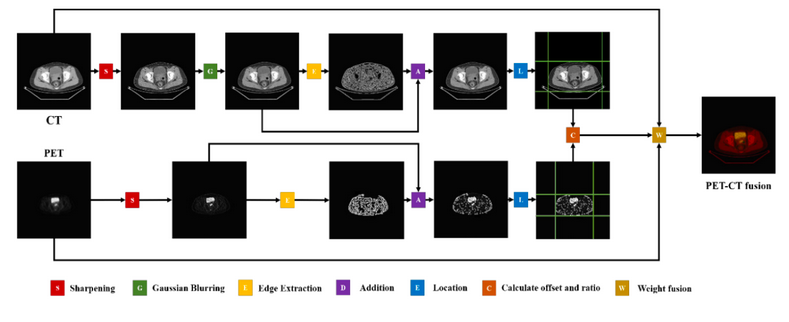
1.2.2.1. 自适应ROI 定位
鉴于数据集中 PET 图像与 CT 图像的黑色背景均为零像素值填充,ROI 内非零像素值较多,而 ROI 边缘的非零像素值较少,因此,选用线检测方法来标画两种模态图像中的 ROI,最终标划结果如图 1-2 中的绿色线框出的部分所示,这四条线是 ROI 在四个方向上的边界。在不同方向上计算比例尺。在将 PET 图像放大后,根据ROI实现CT 和PET 图像的像素级对齐。裁剪掉多余的区域,并用零像素值来补充空白区域。如图 1- 3(a)所示,线检测方法从中心点出发,向四个方向即上下左右对非零像素值进行遍历,并记录下行或列上的非零像素值的数量。如图1- 3(b)所示,红色箭头代表遍历的方向。在从 ROI 中心向边缘进行遍历时,沿遍历经线上的非零像素值数量逐渐减少,如果某一线上非零像素值的计数低于预设的阈值,那么意味着该线已经触及到 ROI 的边缘,如图 1- 3(c)所示。然而,如果直接对未经预处理的图像应用线检测方法,会因受模糊边缘及其噪声的影响,得到较差的对齐结果,难以设置阈值。因此,需对PET 和CT 图像单独执行图像增强预处理,以优化 ROI 标化结果,改善跨模态融合效果。
由于PET 和CT 图像具有不同的纹理特征,应用不同的预处理策略,分别对图像进行增强处理,以强化 ROI 的边缘特性,同时消除噪声产生的干扰,再在两种不同模态图像中进行 ROI 定位,如图1-2 所示。
图 1-3 ROI 检测示意图
CT 图像是用 X 射线对检查部位一定厚度的组织层进行扫描,由探测器接收透过该层面的 X 射线,经数字转换器及计算机处理后形成的解剖学图像。CT 图像通常比 PET 图像更清晰。为了提取 ROI,需利用图像增强技术对 CT 图像进行预处理:首先,通过图像锐化增强边缘特征和灰度跳变部分,使 CT 图像的边缘(即灰度值突变区域)信息更加突出;由于锐化可能导致一定的噪声,再使用高斯模糊滤波器(Gaussian blur)[30 进行图像平滑去噪,将噪声所在像素点处理为周围相邻像素值的加权平均近似值,消除影响成像质量的边缘毛躁;并执行Canny边缘检测(Canny edge detection )[31 来设定阈值并连接边缘,从而在图像中提取目标对象的边缘。尽管Canny边缘检测算法已包含高斯模糊的去噪操作,但实验证实两次高斯模糊后的边缘提取效果更优。在对图像进行锐化处理后,将提取的边缘图像与高斯模糊后的图像进行叠加。具体地,对两个图像中的每个像素直接进行像素值相加,最终得到边缘更清晰且减轻噪声影响的增强后 CT 模态图像。
PET 图像是基于间接探测到的由正电子放射性核素发射的 γ 射线,经过计算机进行散射和随机信息的校正,形成的影像,能够显示体内代谢活动的信息。尽管PET 可以显示分子代谢水平,但由于成像原理的差异,PET 图像相较于 CT 图像显得模糊。对PET 的预处理方式与对CT 图像的类似,但省略了高斯模糊处理图像噪声的步骤,因为在锐化 PET 模态图像后产生的噪声较少,为防止有效特征信息的丢失,略过这一环节。
为了将两个模态的图像进行区域特征匹配,使用PET 和CT 图像中的矩形ROI框来计算缩放比例和位移参数,并通过缩放、填充和裁剪操作对PET 和CT 图像中的ROI 进行对齐。
1.2.2.2. 图像融合
CT 和 PET 图像的尺寸分别为 512×512 像素和 128×128 像素,ROI 特征区域位于图像的中心位置。通过缩放、零值填充和剪切,放大PET 图像的尺寸以与CT 图像的尺寸保持一致,并且将两个模态图像之间的 ROI 对齐,以便后续的融合处理。经处理的PET 和CT 图像转化为灰度形式,分别进行加权和图像叠加,将其置于不同通道中,作为网络的输入层。由于 PET 图像能展示体内分子层面的代谢水平,其对于肿瘤检测的敏感性高于CT 图像。因此,本研究的图像融合方法为PET 图像的ROI 分配了更多权重,以提高宫颈癌检测任务的表现。
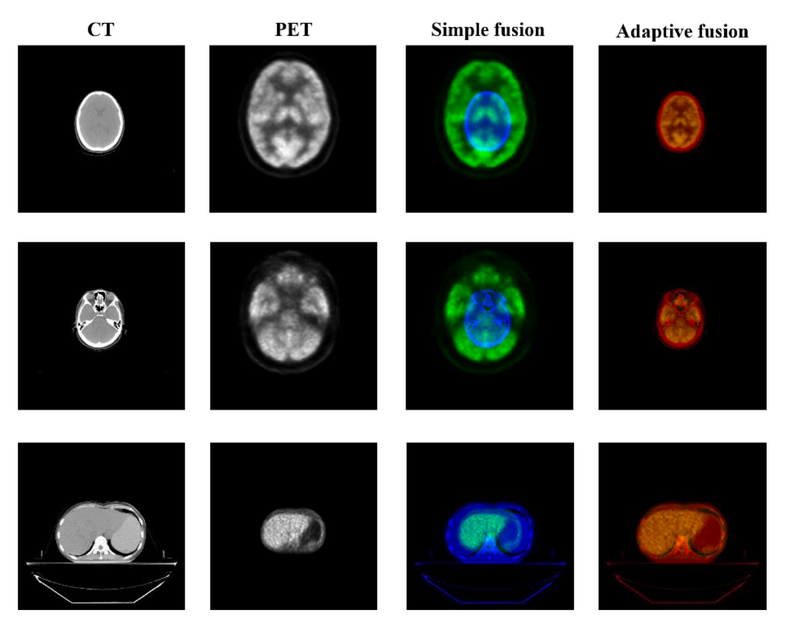
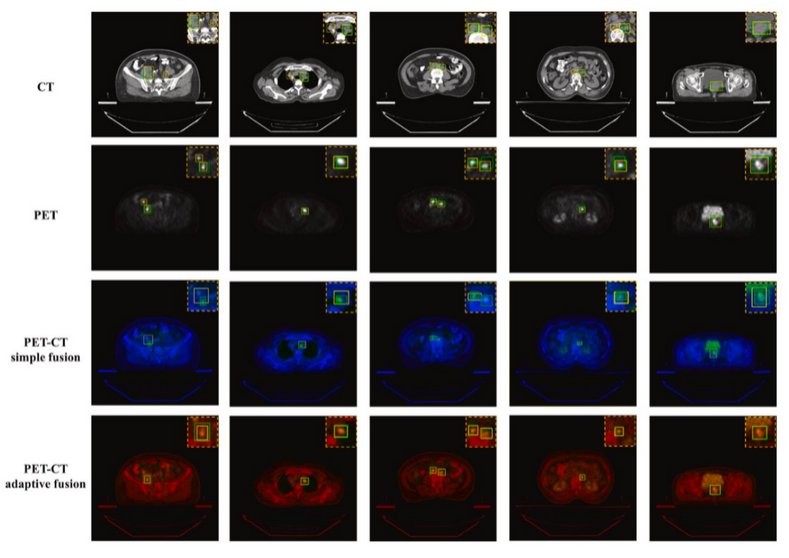
图 1-4 比较了本项目提出的自适应图像融合的结果和直接融合的结果,选取人体不同部位的 CT、PET 和 PET/CT 图像的融合结果进行展示。第一和第二列分别展示了未经处理的原始 CT 和 PET 图像。简单融合算法仅将两个图像的像素点相加,并未执行特征匹配过程,得到的融合图像无任何实用价值。由于通道拼接融合后的图像转变为高维多模态数据,而非三通道数字图像,因此图 1-4 并未展示通道拼接融合方法所得图像。而本项目提出的自适应图像融合方法实现了跨模态图像的精准融合,可用于进一步的观察和计算。
图 1-4 不同图像融合方式的可视化结果
1.2.3. 宫颈癌病变区域检测
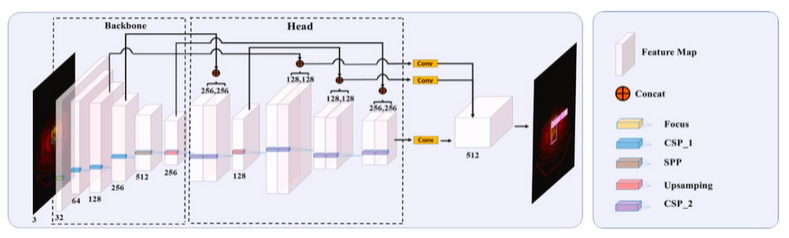
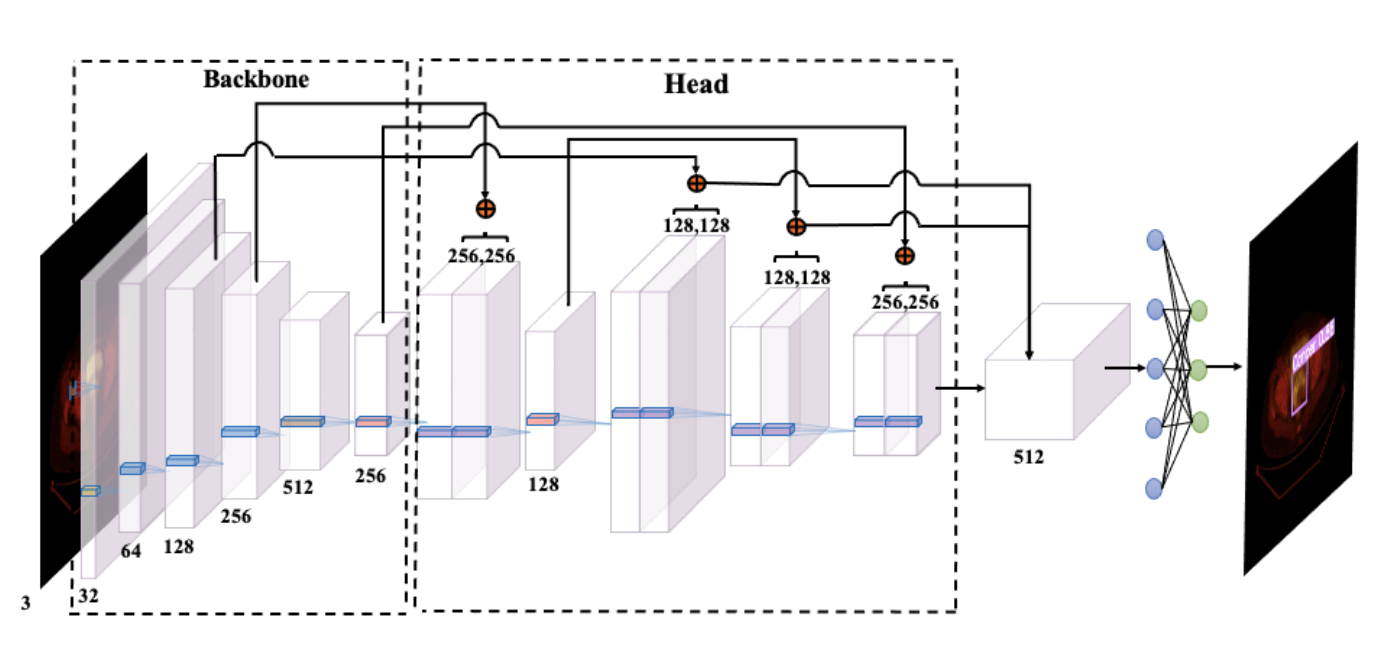
先由两位临床医生对跨模态融合图像中的病变区域进行人工标注,并训练YOLOv5 [32] 目标检测网络来识别融合图像中的病灶区域,如图 1-5 所示。模块骨架用于提取图像的深层特征,为减少通过切片操作进行采样过程中的信息损失,采用聚焦结构,并使用跨阶段局部网络(cross-stage partial network, CSPNet)[33] 来减少模型在推理中所需的计算量。头模块用于执行分类和回归任务,采用特征金字塔网络(feature pyramid network, FPN)和路径聚合网络(path aggregation network, PAN)[34]。
为了提高对极小目标区域的检测效果,输入层采用了mosaic数据增强(mosaic data augmentation)[35] 方法,将四个随机缩放、剪切和随机排列的图像拼接在一起。模块骨架包括 CSPNet 和空间金字塔池化(spatial pyramid pooling, SPP)[36] 操作。输入图像通过三个 CSP 操作和一个 SPP 操作,生成了一个四倍于原始大小的特征图。头模块有三个分支网络,分别接收来自不同层的融合特征、输出各层的边界框回归值和目标类别,最后由头模块合并分支网络的预测结果。
图 1-5 目标检测网络结构
1.3. 实验
1.3.1. 临床信息和影像数据集
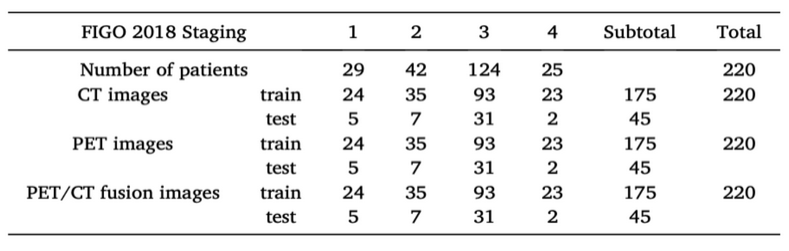
本项目选取符合以下条件的患者开展研究:1)于 2010 年 1 月至 2018 年 12月期间在国家癌症中心中国医学科学院肿瘤医院被诊断为原发性宫颈癌的患者 2)有FDG-PET/CT 图像;3)有电子病历记录。总共入组了 220 名患者,共计 72,602 张切片图像,平均每位患者有 330 张切片图像入组实验。其中,CT 切片图像的高度和宽度均为512 像素,而PET 切片图像的高度和宽度均为128 像素,每个模态的数据集都包含了6,378张切片图像,即平均每位患者有29张切片图像,用于训练和测试。在入组进行分析之前,所有患者数据都已去标识化。本研究已获得北京协和医学院国家癌症中心伦理委员会的批准。
该数据集包含220 个患者的全身 CT 和全身 PET 图像数据,因入组的每位患者均确诊为宫颈癌,数据集中各例数据均包含病变区域,如表 1-1 所示。鉴于所有患者的CT 和PET 均在同一时间且使用相同设备采集,因此 CT 和PET 展示的解剖信息与代谢信息来自同一时刻患者身体的同一区域,其特征具有一对一对应且可匹配的特性。根据肿瘤大小、浸润深度、盆腔临近组织侵犯程度、腹盆腔淋巴结转移的情况可将宫颈癌的进展程度进行分期,主要包括四期,每期中又进一步细分为更具体的期别。国际妇产科联盟(International Federation of Gynecology and Obstetrics,FIGO)于 2018 年 10 月更新了宫颈癌分期系统的最新版本[37]。本项目数据集囊括了 FIGO 分期全部四个期别的宫颈癌影像。为了保持训练和测试的公平性,纳入训练集和测试集的不同期别影像的分布,即不同 FIGO 分期的划分比例,需保持一致,否则可能会导致某些 FIGO 期别的数据集无法进行训练或测试。因此,在保证处于不同期别的患者数据的划分比例的基础上,采用五折交叉验证方法将220 名患者的数据进行五等分,每个部分大约包括了 45 例患者的数据,在每轮验证中随机选择一个部分作为测试集。所有模型都需要进行5 次训练和评估,以获取在测试集上表现出的性能的平均值和标准差。
表 1-1 数据集中的病例数及临床分期
1.3.2. 模型训练过程
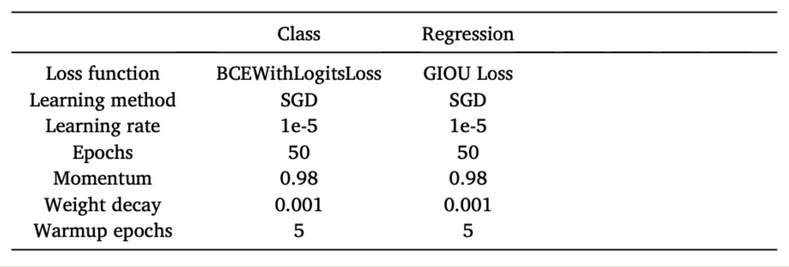
在按上述步骤准备好数据集后,首先将图像从 512×512 像素调整为 1024×1024像素,然后使用多种数据增强方法,包括 mosaic 增强[38]、HSV(Hue, Saturation, Value)颜色空间增强[39]、随机图像平移、随机图像缩放和随机图像翻转,增加输入数据集对噪声的鲁棒性。在每次卷积后和激活函数前进行批归一化(Batch Normalization, BN)[40] 。所有隐藏层都采用 Sigmoid 加权线性单元 (Sigmoid-Weighted Linear Units, SiLU)[41 作为激活函数。训练模型所用的学习率设置为 1e-5,并在起始训练时选择较小的学习率,然后在 5 个轮次(epoch)后使用预设的学习
率。每个模型使用PyTorch 框架在4 个Nvidia Tesla V100-SXM2 32G GPU 上进行50个轮次的训练。使用 0.98 的动量和 0.01 的权值衰减通过随机梯度下降法(Stochastic Gradient Descend, SGD)来优化各网络层的权重目标函数。在训练过程中,网络在验证集上达到最小的损失时,选择最佳参数。所有实验中的性能测量都是在采用最优参数设置的模型中对测试集进行测试得到的,详见表 1-2。
为了进一步证明本项目所提出的模型的普适性,选择了六个基于深度学习的目标检测模型作为基准,并测试了所有模型在输入不同的图像融合结果时的性能。每个模型的输入完全相同,而唯一的区别是神经网络中的超参数来自每个模型的官方设置,而这些超参数因模型而异。
表 1-2 网络训练的超参数
1.3.3. 评价指标
本项目使用“准确度精值50”(Accuracy Precision 50, AP50)来评估目标检测的性能。AP50 是当交并比(Intersection over Union, IOU)阈值为0.5 时的平均精度,如公式3所定义,其中P和R分别是精度(Precision)和召回率(Recall)的缩写。模型的预测结果会有不同的召回率和精度值,这取决于置信度阈值。将召回率作为横轴,精度作为纵轴,可以绘制 PR 曲线,而 AP 是该曲线下的面积。IOU 是将真实标注区域和模型预测区域的重叠部分除以两区域的集合部分(即真实区域和预测区域的并集)得到的结果,如公式4 所示。精度和召回率的计算方式分别在公式1 和2 中列出,其中真正例表示预测为正例的正样本,假正例和假负例代表的概念以此类推。精度表明在模型预测结果里,被判断为正例的样本中有多少实际是正例,而召回率表示实际为正例的样本中多少被预测为正例。表 1-3 记录了图像数据集交叉验证后各个目标检测模型的 AP50 的平均值和方差。

1.3.4. 目标检测模型的结果与分析
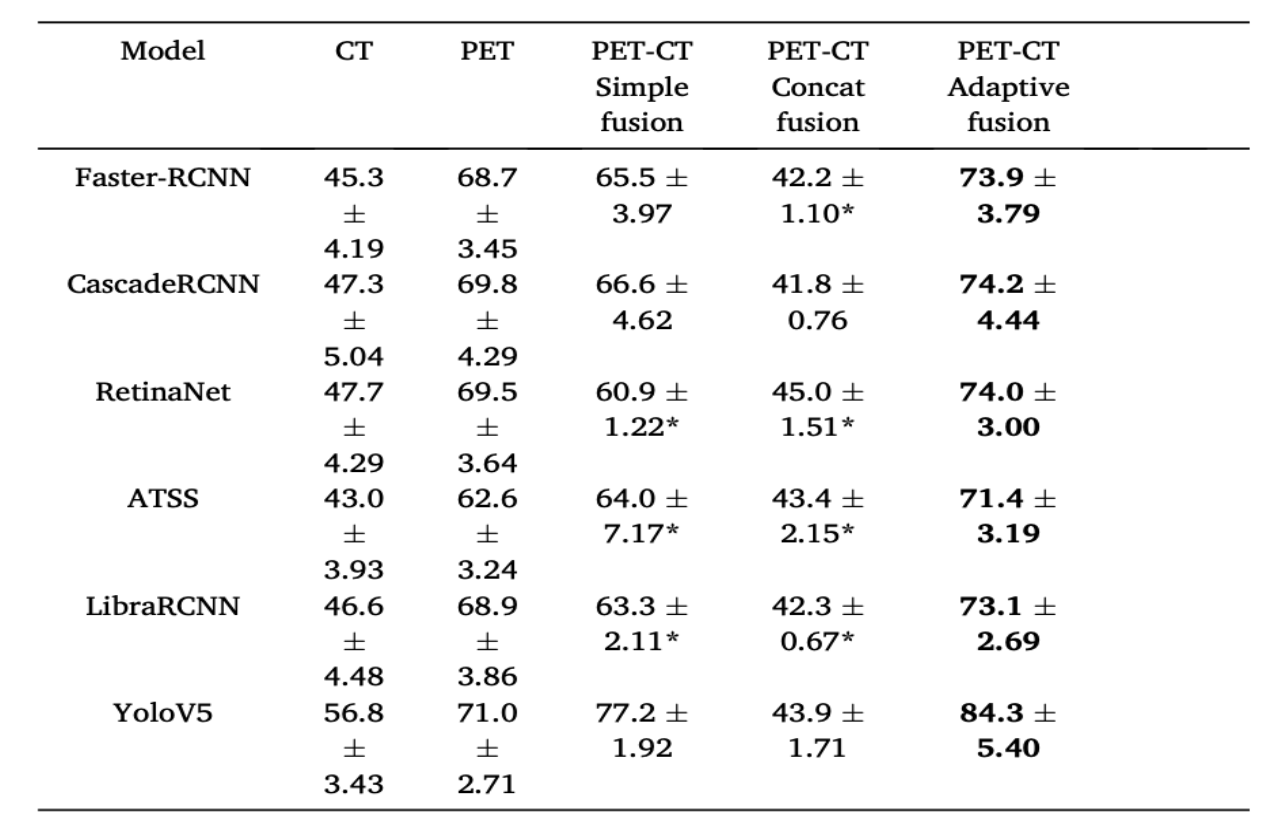
本项目采用不同的目标检测模型,包括单阶段目标检测模型(YOLOv5 [32]、RetinaNet[42]、ATSS [43 )和二阶段目标检测模型(Faster-RCNN [44、CascadeRCNN [45]、LibraRCNN[46]),在五折交叉验证下比较了使用 CT 图像、PET 图像、PET-CT 简单融合图像、PET-CT 通道拼接融合图像(concat fusion)和本项目所提出的 PET-CT自适应区域特征融合图像作为输入数据集时,每个模型的目标检测性能。其中,CT和PET是单模态图像,而PET-CT简单融合图像、PET-CT通道拼接图像和PET-CT 自适应区域特征融合图像是跨模态融合图像。简单融合是指将 PET 图像简单地缩放到与 CT 图像相同的大小后进行像素值的叠加,而通道拼接融合是直接将两种模态图像在通道上串联在一起作为网络的输入。
如表 1-3 所示,加粗的数字代表每行中最好的实验结果。与使用单一模态数据进行肿瘤检测模型分析(如只使用CT 或PET 图像)相比,本项目所提出的自适应跨模态图像融合方法在目标检测任务中展现出了更高的检测精度。由于自适应融合方法能够在跨模态融合之前将两种模态图像的信息进行预对齐,对 CT 图像和PET图像的结构特征进行一一配准,因此,与简单融合方法和通道拼接融合方法相比,自适应融合方法的性能最佳。上述针对不同模态图像及使用不同跨模态融合方法作为输入得到的测试性能结果在使用不同的目标检测模型的情况下保持一致,这表明本项目所提出的跨模态自适应融合方法有良好的通用性,可以泛化应用到各种目标检测模型的预处理中。
表 1-3 五折交叉验证目标检测实验的结果(“*” 表示交叉验证中的某一折在训练过程中出现梯度爆炸,数值为目标检测模型的 AP50 的均值和方差)
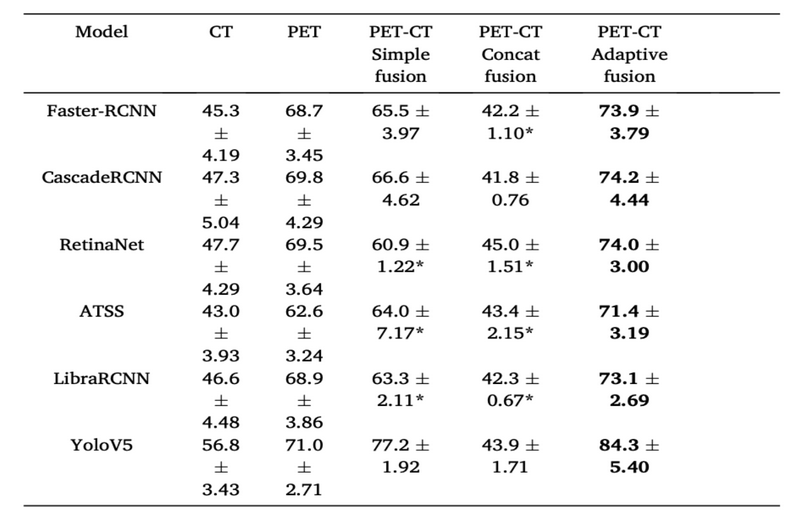
图 1-6 将不同模态图像下目标宫颈癌病变区域的检测结果和实际标注的癌灶区域进行了可视化。其中绿色框是由医生标注的真实病变区域,黄色框是目标检测模型的预测结果。分析图像模态信息可知,CT 图像既包含了人体正常结构的信息,也包含病灶的解剖信息,前者可能会干扰宫颈癌病变区域特征的识别和检测。因此,在单一 CT 模态下会有一些漏检。与 CT 模态的预测框相比,PET 模态下的预测框与标注框的 IOU 更高,或许是由于 PET 影像有更多能表现宫颈癌区域特征的信息。在 PET-CT 区域特征跨模态融合图像中检测效果最佳,因为 PET-CT 融合图像融合了两种模态的不同特征,从而大大提高检测的准确性。
图 1-6 跨模态融合图像的目标检测结果
1.4. 讨论
本项目旨在评估深度学习算法是否可以跨模态融合 FDG-PET 和 CT 图像,并在融合图像中实现宫颈癌病灶区域的自动检测。我们提出了一个基于跨模态融合图像的检测框架,包括区域特征匹配、图像融合和目标检测等步骤。融合 CT 和PET 图像可以最大程度地提取镑个模态中包含的信息,因此 PET-CT 跨模态融合图像含有丰富的解剖和功能信息。目标检测实验证明,本项目提出的跨模态融合方法得到的融合图像显著提高了目标检测的准确性,相比单模态和其他融合方法得到的多模态图像,目标检测平均精确度分别提高了 6.06%和8.9%。
表 1-3 展示了基于不同的图像融合方法形成的多模态图像,不同检测模型在五折交叉验证下的结果。因在解剖和功能影像中均有异常表现的区域更可能是癌变,我们推测,图像信息对齐有利于对宫颈癌病灶的目标区域检测。图 1-6 展示了在不同目标检测模型和不同输入图像数据模态下目标检测效果的可视化图像。基于本项目提出的跨模态融合方法生成的图像进行的目标检测的检测结果更为准确,并消除了一些假阳性结果。根据医生的日常诊断习惯,生成了以红色和黄色为主色的融合图像。
利用 FDG-PET/CT 对宫颈癌进行及时、准确的分期能够影响患者的临床治疗决策,进而延缓疾病进展,并减少肿瘤治疗相关的整体财务负担[47] 。对 FDG-PET/CT 图像的解释在很大程度上依赖临床上获得的背景信息,并需要综合临床分析来确定是否发生癌症的浸润和转移[48]。在某些情况下,核医学科阅片医生可以迅速识别局部扩展和淋巴栓塞。而多数情况下,核医学科医生分析一位患者的FDG-PET/CT 影像学检查结果平均需要三个小时。比起占用医生昂贵且稀缺的时间,利用计算机进行此项工作既能节约成本,预计耗时又短,且可以全天候运行。本项目的目标是通过人工智能方法实现PET 和CT 图像的自动融合,并利用目标检测技术识别宫颈癌的浸润和转移,作为辅助工具加速 FDG-PET/CT 的阅片过程,从而使临床医生能够在最短的时间内按照 FIGO 指南对宫颈癌进行分期。
这项研究仍存在一些局限性。虽然本项目对基于 PET-CT 自适应融合图像的目标检测方法与其他最先进的基于深度学习的目标检测方法进行了比较,但将该方法拓展应用到其他病种的影像学分析的可行性仍需评估。此外,我们提出的跨模态融合框架在图像融合时并未考虑每种模态图像的权重分布。未来可以设计一种特殊的损失函数来调整 ROI 内每个像素的权重分布,以提高目标检测结果的准确性。
1.5. 结论
本项目提出了一种基于跨模态图像融合的多模态图像进行病变区域检测的深度学习框架,用于宫颈癌的检测。为了应对医学影像中单一模态图像在肿瘤检测方面的性能不足,提出了一种基于区域特征匹配的自适应跨模态图像融合策略,将融合后的多模态医学图像输入深度学习目标检测模型完成宫颈癌病变区域检测任务,并讨论了深度学习模型在每种模态图像输入间的性能差异。大量的实验证明,与使用单一模态的影像及基于简单融合方法或通道拼接融合方法的多模态影像相比,自适应融合后的多模态医学图像更有助于宫颈癌病变区域的检测。
本项目所提出的技术可实现 PET 和CT 图像的自动融合,并对宫颈癌病变区域进行检测,从而辅助医生的诊断过程,具备实际应用价值。后续将基于第一部分的目标检测模型基础,利用特征转换的方法,将图像数据转换为结构数据,将跨模态融合方法应用于分类问题。
2. 基于特征转换的跨模态数据融合的乳腺癌骨转移的诊断
2.1. 前言
骨骼是第三常见的恶性肿瘤转移部位,其发生率仅次于肺转移和肝转移,近 70%的骨转移瘤的原发部位为乳腺和前列腺[49] ,[50] 。骨转移造成的骨相关事件非常多样,从完全无症状到严重疼痛、关节活动度降低、病理性骨折、脊髓压迫、骨髓衰竭和高钙血症。高钙血症又可导致便秘、尿量过多、口渴和疲劳,或因血钙急剧升高导致心律失常和急性肾功能衰竭[51 。骨转移是乳腺癌最常见的转移方式,也是患者预后的分水岭,其诊断后的中位生存期约为 40 个月[52] ,[53] 。因此,及时发现骨转移病灶对于诊断、治疗方案的选择和乳腺癌患者的管理至关重要。目前,病灶穿刺活检是诊断骨转移的金标准,但鉴于穿刺活检有创、存在较高风险、且假阴性率高,临床常用影像学检查部分替代穿刺活检判断是否发生骨转移。
Batson的研究表明,乳腺的静脉回流不仅汇入腔静脉,还汇入自骨盆沿椎旁走行到硬膜外的椎静脉丛[54] 。通过椎静脉丛向骨骼的血液回流部分解释了乳腺癌易向中轴骨和肢带骨转移的原因。因潜在骨转移灶的位置分布较广,影像学筛查需要覆盖更大的区域,常要求全身显像。常用的骨转移影像诊断方法包括全身骨显像(whole-body bone scintigraphy, WBS)、计算机断层扫描(computed tomography, CT)、磁共振成像(magnetic resonance imaging, MRI)和正电子发射断层显像(positron emission tomography, PET)[55]。CT 可以清晰地显示骨破坏,硬化沉积,和转移瘤引起软组织肿胀;MRI 具有优异的骨和软组织对比分辨率;因 [18F] 氟化钠会特异性地被骨组织吸收、代谢, PET 可以定位全身各处骨代谢活跃的区域。然而,单一模态影像常不足以检测骨转移,且用传统方法综合单一患者的 CT、MRI、PET 数据筛查骨转移病灶需要对上千幅影像进行解读,这一极为耗时的过程可能影响临床医生对乳腺癌骨转移的诊断,造成误诊、漏诊。而骨转移的漏诊会误导一系列临床决策,导致灾难性后果。
作为一种客观评估体系,人工智能辅助骨转移自动诊断系统通过减少观察者间和观察者内的变异性,提高了诊断的一致性和可重复性,降低了假阴性率。在减轻临床医生的工作负担的同时,提高诊断的准确性。目前已经有很多在单一模态图像中(CT、MRI 或 PET)基于深度学习技术进行骨转移病变检测的工作: Noguchi 等人开发了一种基于深度学习的算法,实现了在所有 CT 扫描区域中对骨转移病灶的自动检测 [56];Fan 等人用 AdaBoost 算法和 Chan-Vese 算法在 MRI 图像上对肺癌的脊柱转移病灶进行了自动检测和分割肺[57];Moreau等人比较了不同深度学习算法在 PET/CT 图像上分割正常骨组织和乳腺癌骨转移区域的性能[58] 。但很少有使用跨模态数据融合的深度学习方法,判断是否存在骨转移灶的相关研究。
旨在减轻临床医生的工作负担,本章提出了基于特征转换的跨模态数据融合方法,用于分析 CT、MRI 和 PET 图像,以判断其中是否存在乳腺癌骨转移病灶。
基于特征转换的 CT、MRI 和 PET 跨模态图像数据融合,进行骨转移病变分类(即存在骨转移病灶和不存在骨转移病灶两类)项目包括三个研究任务:目标病变区域检测,特征构造及转换和分类任务。具体地,采用目标检测模型对不同模态的医学图像序列数据进行单独的骨转移瘤目标检测,再对这些检测结果进行特征提取。所提取的特征包括不同模态下检测结果置信度的区间占比、检测框的面积大小、检测框在图像中的空间位置分布等。这些特征被整理成结构化数据格式,完成了从非结构化影像数据到结构化数据特征的特征转换和融合过程。最后,将转换后的特征输入分类模型进行分类任务。实验比较了基于特征转换的跨模态数据融合方法在乳腺癌骨转移肿瘤分类任务的性能,与仅使用单模态数据执行分类任务的性能。同时,还将本项目提出的基于特征转换的融合策略与其他融合方法进行了对比。
2.2. 研究方法
2.2.1. 研究设计和工作流程
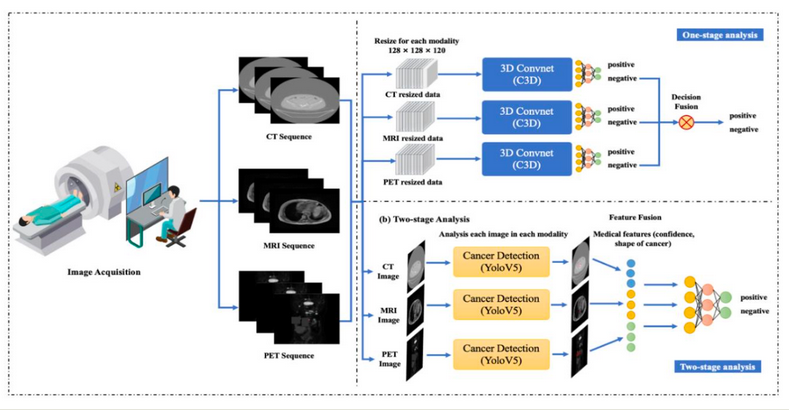
本项目旨在判断 CT、MRI、PET 图像序列中是否存在乳腺癌骨转移病灶。工作流程如图 2-1 所示:扫描设备对每位患者进行 CT、MRI 或 PET 图像序列的采集;使用目标检测模型分别在不同模态图像中对可疑乳腺癌骨转移灶进行目标检测;对检测结果进行特征提取、构造和融合,得到具有可解释性的结构化医疗数据;用分类模型对结构化数据进行分类任务,得出预测结果,从而判断乳腺癌骨转移是否发生。
图 2-1 工作流程
2.2.2. 骨转移目标区域检测
先由两位临床医生对多模态数据集图像中的骨转移病灶进行人工标注,并对患者进行分类(标签分为乳腺癌骨转移和非乳腺癌骨转移),并训练 YOLOv5 目标检测网络,以识别各个单一模态图像中的乳腺癌骨转移病灶。
2.2.3. 基于特征转换的跨模态数据融合
在本项目的数据集中,各种模态序列影像的扫描范围均涵盖了患者的全身。某患者的影像序列(不论是单模态图像还是多模态图像)中检测到含有骨转移病灶的切片图像数量越多,则意味着该患者发生乳腺癌骨转移的概率越大。根据这一基本推理,采用后融合方法,将一个影像序列中含有肿瘤切片图像的比例(百分比)作为结构化的数据特征,作为后续分类任务的依据。
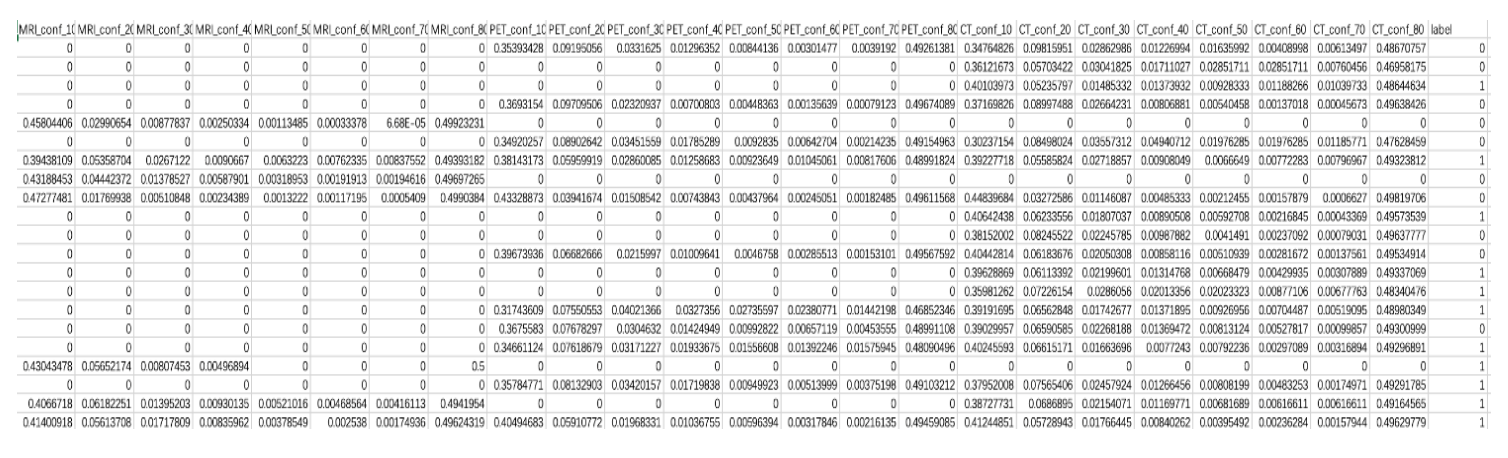
具体操作如下:在每个模态的图像中完成骨转移区域的目标检测任务训练后,统计每个图像序列中检测到转移瘤目标区域的检测框数量。按照检测框的置信度划分为 8 个区间:10%~20%、20%~30%、30%~40%、40%~50%、50%~60%、60%~70%、70%~80%和大于 80%。在每个区间内,分别统计各模态图像序列中转移瘤检测框数量,再除以该序列中切片图像的总数,得到每个置信度区间内每种模态图像序列中含有转移瘤检测框的百分比。接着将三种模态图像提取出的统计特征拼接,组成结构化数据,实现跨模态数据融合。若患者缺失某种模态数据,相应的统计特征(百分比)将被置为零。特征转换后的结构化数据如图 2-2 所示,每种模态数据包括 8 个特征,即不同的置信区间,最后一列为标签值,其中“0”表示负例,“1”表示正例。
图 2-2 特征转换后的结构化数据
2.2.4. 乳腺癌骨转移的分类模型
利用构建好的结构化医疗特征进行乳腺癌骨转移分类任务,融合跨模态图像数据特征判断是否发生乳腺癌骨转移。本项目采用分类模型主要以模式识别基础模型为主,包括SVM[59]、AdaBoost[60]、RandomForest[61]、LightGBM[62]、GBDT[63]。SVM 是一种基于核函数的监督学习模型,用于解决分类问题,通过寻找最优超平面在特征空间中将样本分为不同类别,决策函数映射输入特征到输出标签,核函数将特征映射到新空间,损失函数度量决策函数性能,最大化超平面与样本间距离实现分类,可使用不同核函数处理高维特征。Adaboost 是一种迭代算法,于1995 年由 Freund Y 等人提出,能够将多个弱分类器结合成一个强分类器,通过选择初始训练集、训练弱分类器、加权重新分配样本和重复训练直到训练完成所有弱学习器,最后通过加权平均或投票得出最终决策。由 Breiman L 等人于 2001 年提出得 RandomForest 是一种基于决策树的机器学习算法,可用于分类和回归任务。通过构建多个决策树并对它们的预测结果进行平均或投票来得出最终预测结果,训练过程中随机选择特征,以避免过拟合并减少计算量。机器学习模型 LightGBM是一种基于决策树的梯度提升机算法,由Ke G 等人在2017 年提出,适用于结构化数据的分类任务。具有高效、内存友好、支持并行处理和多 CPU 等特点,能快速处理大量特征,通过基于直方图的决策树算法减少训练时间和内存使用量。通过损失函数的泰勒展开式来近似表示残差来计算损失函数。由 Friedman J H 等人于2001 年提出的 GBDT 是一种迭代的决策树算法,通过构建多个决策树来拟合目标函数,每一步都在上一步的基础上构建新的决策树,以不断减小误差,流程包括选取子集、训练弱学习器、梯度下降法最小化误差,最终将弱学习器加入总体模型,重复以上步骤直至达到最优解。
2.2.4.1. 基于C3D 的跨模态数据融合分类模型
本项目采用C3D[64 分类模型作为对照模型,基于3D 卷积神经网络的深度学习方法,使用跨模态数据融合中的前融合策略。如图 2-1 所示,该融合策略从每个模态的图像序列中筛选出一部分,合并一个完整的多模态图像序列,并在通道上进行级联,进行跨模态数据融合。融合后的数据作为 3D 卷积神经网络的输入,经过多个 3D 卷积层提取特征,最终在全连接层中执行分类任务,以判断影像中是否存在乳腺癌骨转移病灶。
2.3. 实验
2.3.1. 临床信息和影像数据集
本项目选取符合以下条件的患者开展研究:1)于 2000 年 01 月至 2020 年 12月期间在北京协和医院或国家癌症中心中国医学科学院肿瘤医院被诊断为原发性乳腺癌的患者 2)有全身 CT 或 PET 或 MRI 其中任一模态的全身影像数据;3)有电子病历记录。入组患者中有145名被确诊为乳腺癌骨转移,作为正例样本,有88名患者未发生乳腺癌骨转移,作为负例样本。每例样本数据包含一至三种不同模态的图像序列,其图像尺寸和切片图像数量各异。乳腺癌骨转移的多模态医学图像数据集对患者的全身进行采样,由于患者的 CT、MRI 或 PET 是不同时间、在不同设备上采集的,不同模态间的特征并非一一匹配。其中,CT 模态共有3051 张切片,MRI 模态共有 3543 张切片,而 PET 模态共有 1818 张切片。在入组进行分析之前,所有患者数据都已去标识化。本研究已通过北京协和医院伦理委员会批准。
该数据集可以用于执行目标检测任务和分类任务。
骨转移目标检测任务仅分析数据集中的正例样本,进行五折交叉验证:将 145例患者的数据按模态分为三组(CT组、MRI组、PET组),在每个组内对数据进行五等分,在每轮验证中选取一部分作为测试集。为获得测试性能的平均值,所有模型都需进行5 次训练和评估。
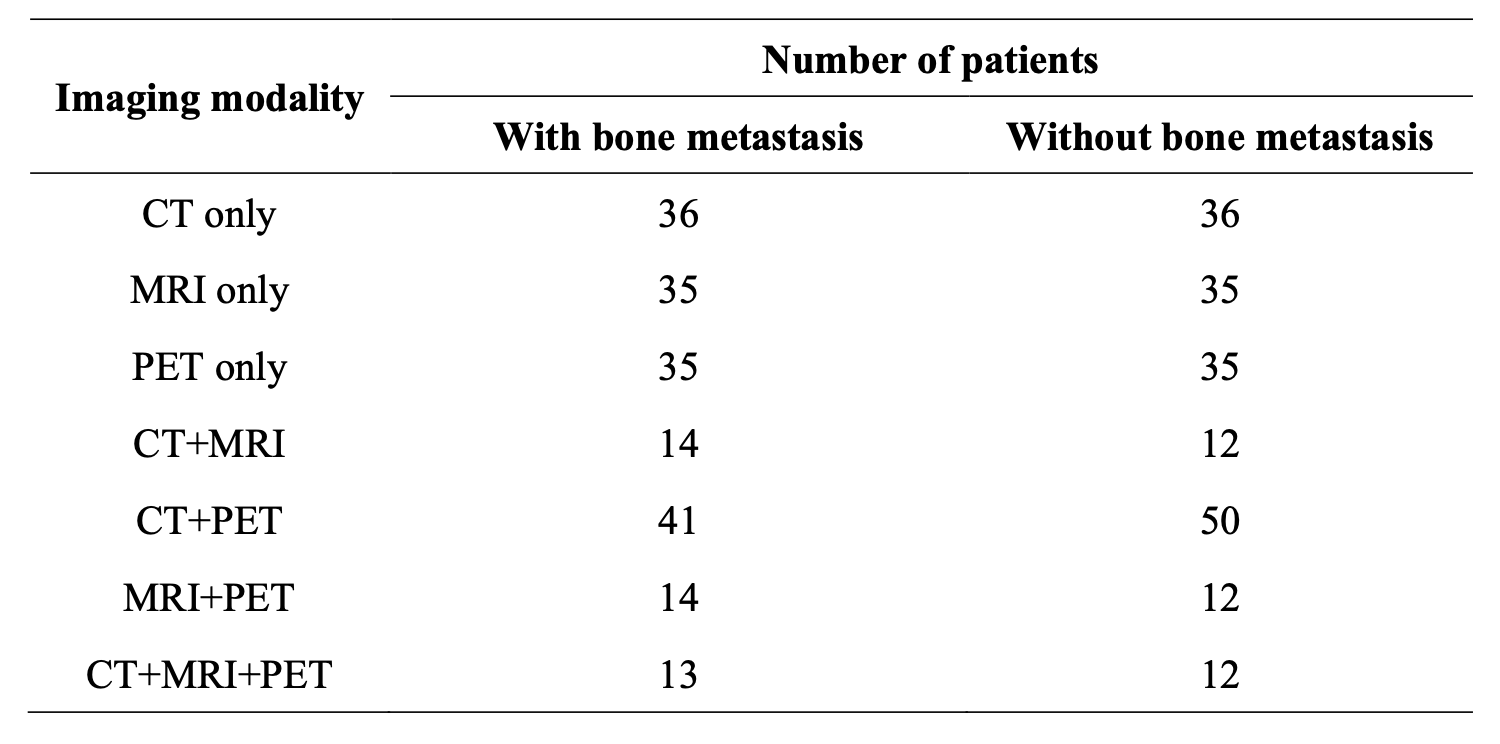
在利用结构化数据执行分类任务时,需要平衡正负样本数量,因此要扩充数据集。将具有多种模态的样本拆分为包含较少模态的样本,如将“CT+MRI+PET”类型拆分为“CT+MRI”或“CT+PET”等。如表 2-1 所示,扩充后共有 380 例样本数据,包括188 个正样本和 192 个负样本。下一步,合并五折交叉验证的目标检测结果,此后,进行特征构建和转换,从而获得适合跨模态数据融合和分类任务的结构化数据;对于负样本数据,也需要在合并骨转移目标检测模型的推理结果后,对数据进行结构化处理。
为证实在乳腺癌骨转移判断的分类任务中,基于特征转换的跨模态融合数据性能优于单一模态数据,需要进行多模态融合数据与单模态数据的对照实验。如表 2-1 所示,单模态数据包括仅有 CT、仅有 MRI 和仅有 PET 三种类型的数据集合,总计 212 个样本,而多模态数据涵盖了CT+MRI、CT+PET、MRI+PET 和CT+MRI+PET 四种类型,共计 168 个样本。分别对单模态数据和多模态数据进行独立划分,将每种模态数据进行五等份,进行五折交叉验证。在每轮验证中,选择一部分作为测试集。利用 SVM、AdaBoost、RandomForest、LightGBM、GBDT以及 C3D 模型进行实验,每个模型都需进行 5 轮训练和评估,以获得测试集上性能的平均值。
为适应 C3D 模型对图像统一尺寸的要求,针对不同患者切片数量、大小的差异,进行预处理。在每种模态图像序列中等间隔抽取 60 张图像切片,并进行缩放,使其组合为 180 张 128×128 像素的切片。对于缺失的模态数据,用 60 张零像素值的黑色图像切片进行填充。从 180 张切片中随机选取一个起始位置,连续抽取 120张切片作为模型的最终输入,确保输入尺寸为 128×128×120 像素。
表 2-1 扩充后的分类数据集
2.3.2. 模型训练过程
在按上述步骤准备好数据集后,进行目标检测任务训练时,将每个模态的图像大小统一到1024×1024像素,然后使用多种数据增强方法,增加输入数据集对噪声的鲁棒性。
目标检测模型采用 YOLOv5 模型模型并使用 PyTorch 深度学习框架在 2 个Nvidia Tesla V100-SXM2 32G GPU 上进行 70 个轮次的训练。初始学习率为 0.00001,使用 0.98 的动量和 0.01 的权值衰减通过 SGD 来优化各网络层的权重目标函数。在训练过程中,网络在验证集上达到最小的损失时,选择最佳参数。
进行分类任务时,采用 LightGBM、GBDT、AdaBoost、RandomForest 以及SVM,上述模型均为机器学习模型,其超参数对模型预测结果影响较大,在分类任务中,采用SVM、AdaBoost、RandomForest、LightGBM以及GBDT等机器学习模型。因其超参数会对预测结果产生较大影响,在训练过程中,使用网格搜索策略为这些模型寻找最佳参数。网格搜索策略在一定范围的超参数空间内寻找最佳的超参数组合,通过枚举各种可能的组合并评估模型预测结果,最终选择表现最优的超参数组合。要搜索的超参数包括学习率、树的最大深度、叶子节点数量、随机抽样比例、权重的L1正则化项和权重的L2正则化项等。实验结果将基于最优超参数设定下的预测模型。模型训练的网络结构图如图 2-3 所示。
用于对照的 C3D 模型使用 PyTorch 深度学习框架在 1 个 NVIDIA Tesla V100-SXM2 32GB GPU 上训练 100 个轮次,初始学习率为 0.00001,使用动量为 0.9,权值衰减为0.0005 的 SGD 梯度下降优化器对各网络层权重的目标函数进行优化。
图 2-3 网络结构图
2.3.3. 评价指标
本项目中的骨转移目标检测任务采用 AP50 作为评价指标,其介绍详见上一章节。
而在分类任务中,采用准确率(Accuracy, Acc)、敏感性(Sensitivity, Sen)、特异性(Specificity, Spe)、AUC(Area Under Curve, AUC)作为评价指标,并采用ROC 曲线和PR 曲线对模型进行评估。准确率是指对于给定的测试集,分类模型正确分类的样本数占总样本数的比例,如公式 5 所示,其中真正例(True Positive, TP)表示预测为正例且标签值为正例,假正例(False Positive, FP)表示预测为正例但标签值为负例,和假负例(False Negative, FN)和真负例(True Negative, TN)代表的概念以此类推。如公式 64 和公式 7 所示,敏感性和特异性的定义分别为:预
测正确的正例占所有正例的比例,以及预测正确的负例占所有负例的比例。ROC曲线是一种评估二分类模型的方法,其横轴为假阳性率(False Positive Rate,FPR),其计算方式与上一章的召回率(Recall)相同,纵轴为真阳性率(True Positive Rate,TPR),TPR 和 FPR 的计算方式详见公式 8 和公式 9。ROC 曲线展示了在不同阈值下,TPR 与 FPR 的变化关系。因为左上角点对应的假阳性率为 0,真阳性率为 1,表明模型将所有正例样本分类正确,且未将任何负例样本误判为正例。若 ROC 曲线靠近左上角,提示模型性能较好。AUC代表ROC曲线下的面积,即从(0,0)到(1,1)进行积分测量ROC曲线下二维区域的面积。AUC综合考虑所有可能的分类阈值,提供了一个全面的性能度量。AUC 值表示随机从正负样本中各抽取一个,分类器正确预测正例得分高于负例的概率。AUC 值越接近 1,说明模型性能越优秀。PR曲线的绘制方法详见上一章, PR曲线在不同分类阈值下展示了分类器在精度(Precision, P)和召回率(Recall, R)方面的整体表现。

2.3.4. 单模态骨转移灶检测模型及基于特征转换的跨模态分类模型的结果与分析
本项目对乳腺癌骨转移多模态医学图像数据集(包括 CT、MRI、PET)进行了单模态肿瘤检测实验和基于特征转换的跨模态病例分类实验。其中,单模态肿瘤检测实验是多模态肿瘤分类实验的前置步骤。
采用单阶段目标检测模型 YOLOv5,在五折交叉验证下比较了使用单模态 CT图像、PET图像、MRI图像作为输入数据集时,模型的目标检测性能。并在将目标检测结果进行特征转换后,采用不同的分类模型,包括后融合分类模型(LightGBM、GBDT、AdaBoost、RandomForest、SVM) 和 前 融 合 分 类 模 型(C3D),在五折交叉验证下比较了使用单模态数据和跨模态融合数据作为输入时,每个模型的分类性能。
表 2-2 展示了在不同单一模态数据上,五折交叉验证得到的骨转移病灶检测结果,评估指标为 AP50。实验结果表明,PET 模态的检测精度较高,而 CT 模态的检测精度最低。输入数据量较少、检测目标面积小、转移瘤的特征难以与正常骨组织区分是提高检测精度的难点。图 2-4 不同单一模态图像下目标骨转移病变区域的检测结果和实际标注的癌灶区域进行了可视化。绿色框由医生标注,目标检测模型标注的预测框为黄色。
结论
本项目提出了一种基于特征转换的跨模态数据融合方法进行分类任务的深度学习框架,用于判断是否发生乳腺癌骨转移。首先独立对不同模态的医学图像数据进行肿瘤检测,根据目标检测结果进行特征构造,并将其组织成结构化数据的形式,完成从非结构化数据特征到结构化数据特征的转换与融合。最终,将结构化数据特征输入分类器,进行骨转移的分类任务,并对照 C3D 前融合模型,讨论了基于特征转换方法进行跨模态数据后融合的优势。大量的实验证明,使用基于特征转换的跨模态融合数据进行分类任务的性能优于基于单模态数据的分类性能;使用本项目提出的后融合策略执行分类任务较使用前融合策略的分类模型(C3D)的性能更好。
本项目所提出的技术可综合 CT、MRI 和 PET 模态数据的特征,对乳腺癌患者是否发生骨转移进行判断,辅助临床医生进行乳腺癌骨转移病灶的筛查,具备实际应用价值,也为在医学图像分析任务中更有效地应用跨模态融合方法,提供了关键的理论支持。
全文小结
目前,医学影像学的解读大量依赖临床医生个人的主观诊断经验,人工阅片易漏诊小目标,难以推广及表述,具有一定的局限性。与此相比,人工智能技术可以通过深度神经网络对大量积累的影像数据和诊断数据进行分析,学习并提取数据中对病理诊断有用的特征,从而在数据支持下做出更客观的判断。按成像方式不同,医学影像数据可分为多种模态,如B超、CT、MRI、PET。为了最大限度模拟临床医生结合不同模态影像检查结果形成诊断的过程,设计人工智能模型时,应将各种影像学模态的特征进行有效的融合,即本项目中应用的跨模态深度学习方法,充分利用不同模态图像的独特优势训练深度神经网络,从而提高模型性能。本项目以宫颈癌和乳腺癌骨转移为例,验证了跨模态深度学习方法在病变区域定位和辅助诊断方面的性能。
在第一部分中,我们回顾性纳入了220例有FDG-PET/CT数据的宫颈癌患者,共计 72,602 张切片图像。通过图像增强、边缘检测,实现 PET 和 CT 图像的 ROI自适应定位,再通过缩放、零值填充和剪切的方式,将两种模态图像的 ROI 对齐。经过加权和图像叠加,进行图像融合,将融合后的图像作为目标检测网络的输入层,进行宫颈癌病变区域检测。实验证明,相比使用单一 CT 图像、单一 PET 图像、PET-CT 简单融合图像、PET-CT 通道拼接融合图像作为网络输入,PET-CT 自适应区域特征融合图像显著提高了宫颈癌病变区域检测的准确性,目标检测的平均精确度(AP50)分别提高了 6.06%和 8.9%,且消除了一些假阳性结果,展现出可观的临床应用价值。
在第二部分中,我们回顾性纳入了 233 例乳腺癌患者,每例样本数据包含 CT、MRI、或 PET 一至三种模态的全身影像数据,共有 3051 张 CT 切片,3543 张 MRI切片,1818 张 PET 切片。首先训练 YOLOv5 目标检测网络,对每种单一模态图像中的骨转移病灶进行目标检测。统计每个影像序列中含有检出骨转移病灶的个数和置信度,将每个置信区间内含有目标检测框的百分比作为结构化医疗特征数据。采用级联方式融合三种模态的结构化特征,得到具有可解释性的结构化医疗数据,再用分类模型进行分类,预测是否发生骨转移。实验证明,相较于单模态数据,跨模态融合数据显著提高了乳腺癌骨转移诊断任务的性能,平均准确率和 AUC 分别提高了 7.9%和 8.5%,观察 ROC 曲线和 PR 曲线的形状和面积也有相同的实验结论。在不同的分类模型(SVM、AdaBoost、RandomForest、LightGBM、GBDT)中,使用基于特征转换的跨模态数据,相比单模态数据,对于骨转移病例的分类性能更为优越。而相较于基于 C3D 的前融合分类模型,基于特征转换的后融合策略在分类任务方面的性能更优。
综上所述,本文基于人工智能深度学习算法,针对不同模态医学图像的特征差异与互补性,进行多模态医学影像数据的跨模态融合,提高了模型的肿瘤检测和分类性能,检测模型和分类模型可以辅助影像学阅片过程,具有显著的临床实际应用价值。