新评测泼冷水:别再吹AI搞科研了
2025-12-27 11:25:39 · chineseheadlinenews.com · 来源: 量子位
如今,大模型在理解、推理、编程等方面表现突出,但AI的“科学通用能力”(SGI)尚无统一标准。
SGI强调多学科、长链路、跨模态与严谨可验证性,而现有基准仅覆盖碎片能力(如学科问答、单步工具操作),难以反映真实科研中的循环与自纠错。为此,上海人工智能实验室通过引入实践探究模型(PIM),将科学探究拆解为四个循环阶段,并与AI能力维度对应:
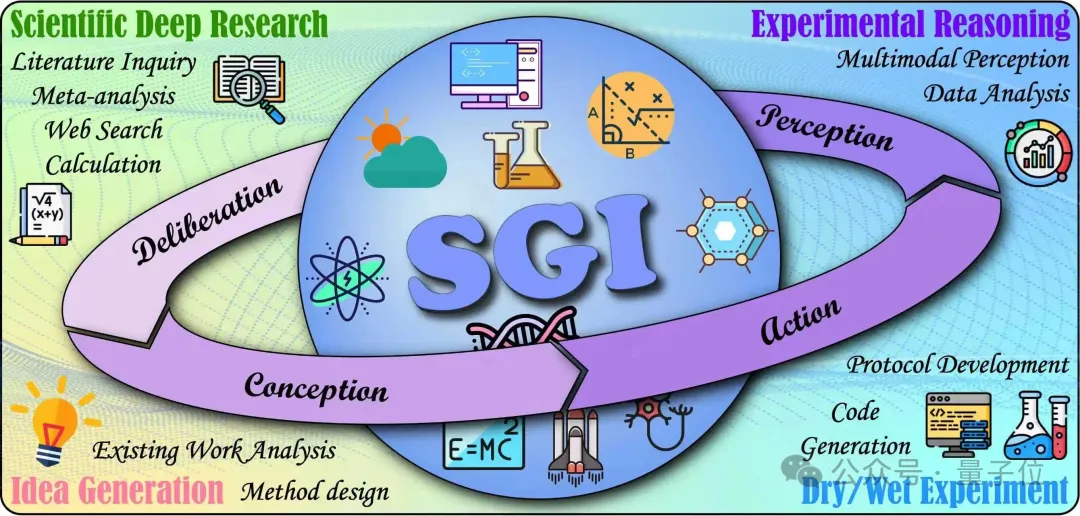
审思/深度研究(Deliberation):复杂问题下的检索、证据综合与批判评估;
构思/创意生成(Conception):提出新假说与可执行研究方法;
行动/实验执行(Action):将想法转化为计算代码(干实验)与实验室流程(湿实验);
感知/结果解读(Perception):整合多模态证据并进行因果、比较等分析推理。
团队将上述四维能力的综合定义为SGI,并发布覆盖全流程的SGI?Bench。首轮结果:闭源模型Gemini?3?Pro以SGI?Score 33.83/100取得SOTA,但距离“会做研究”的门槛仍显著不足。
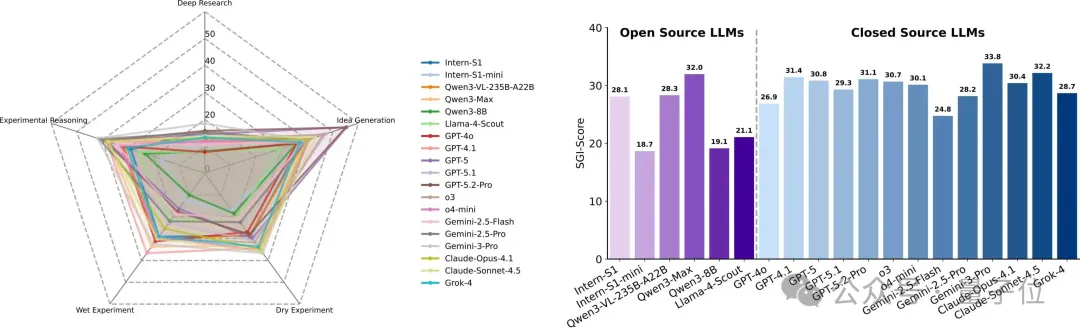
SGI-Bench:以科学家工作流对齐的全流程评测
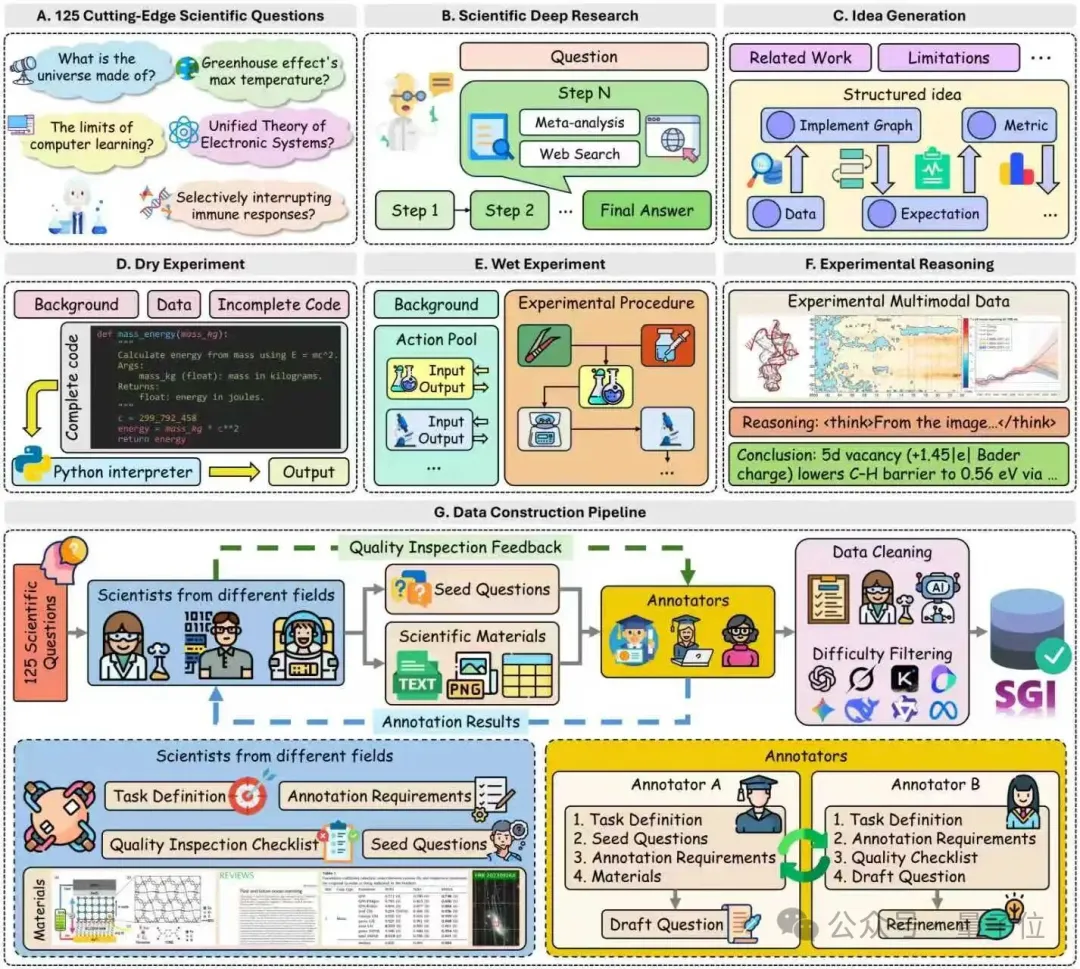
SGI?Bench采用“科学家对齐(scientist-aligned)”的任务构造:
多学科专家提供原始语料(研究方向、图文材料等)与少量种子问题(seed questions);
招募超过100位研究生/博士生根据输入输出结构与种子问题,结合真实科研流程,进行题目构建;
经规则校验、模型校验、专家复核三重清洗;最终再以多模型难度筛选剔除简单样本。
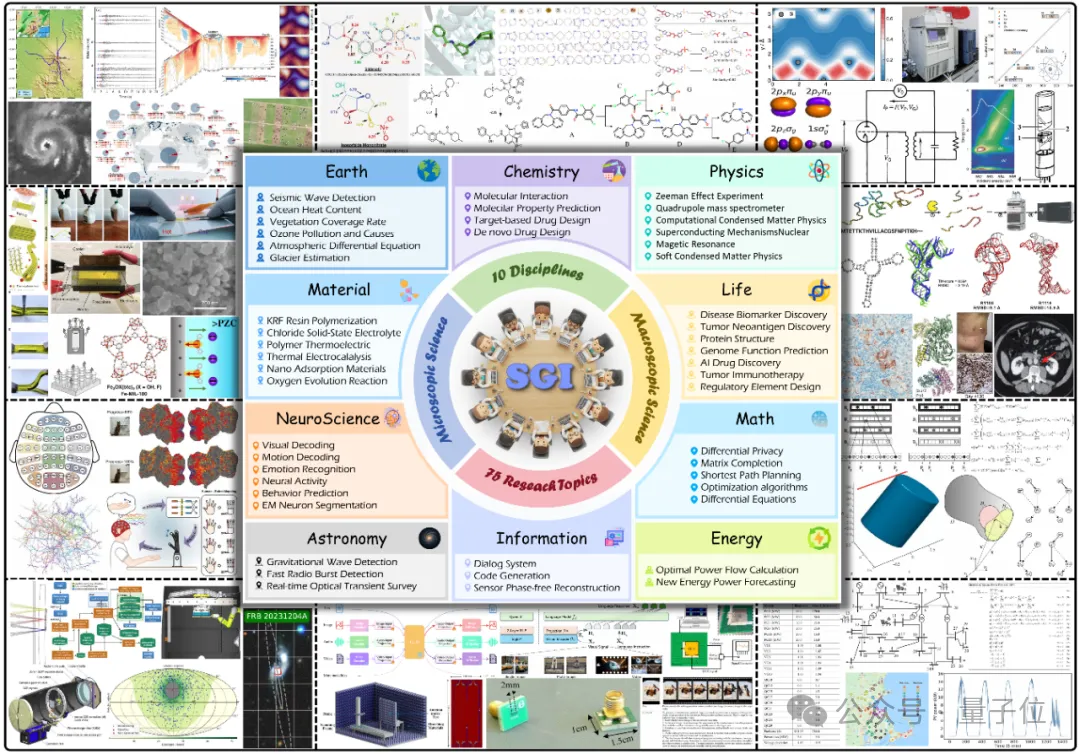
最终得到1000多个覆盖10大学科(化学、生命、物理、数学等)的评测样本。
核心结果与洞见:今天的“强模型”,尚未成为“强科学家”
1. 审思/深度研究Deliberation
科学深度研究(Scientific Deep Research)步骤准确率高于严格匹配,长链路“结论崩塌”
任务模拟文献元分析与多跳检索,要求在明确约束下检索并整合跨来源证据、进行定量推理,输出可核验结论。

实验结果:
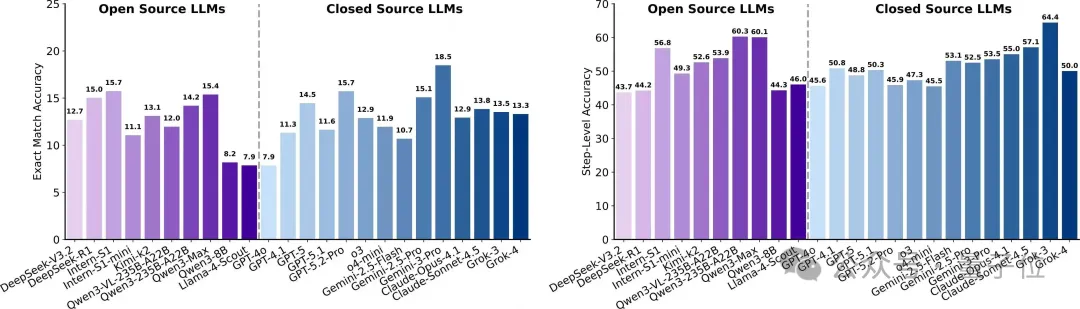
步骤准确率达50%–65%,但长链条步骤中的错误导致最终结论频繁错误,答案严格匹配仅10%–20%。
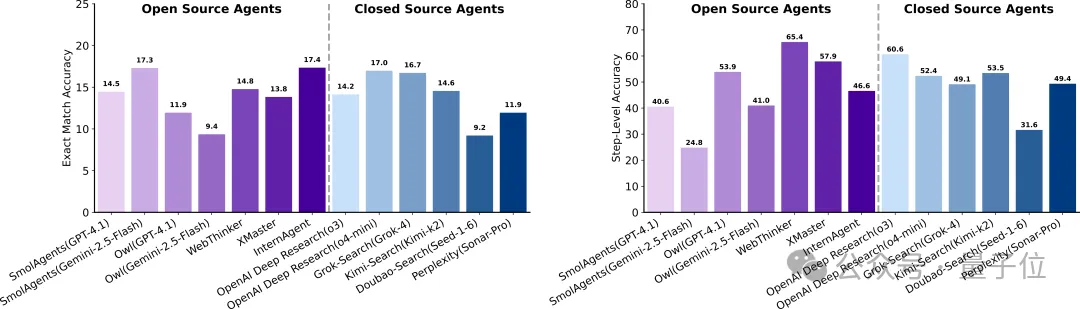
工具增强的多智能体在逐步准确率略优,但与纯模型差距并不显著。
类型上,“数据/性质”题最难,需跨文献精确检索与数值聚合;“微/宏实验”类相对较好但整体仍低于30%,体现元分析难度的严苛性。
2. 构思/创意生成Conception
创意生成(Idea Generation)新颖度尚可,但可行性偏低
面向整体思路和具体方案,考察将灵感转化为可执行蓝图的能力(包含创新点、方法步骤,数据,指标等)。
实验结果:
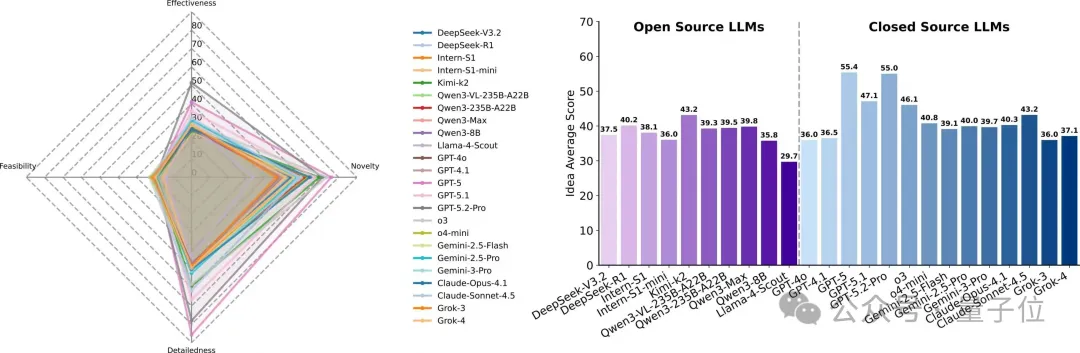
闭源模型“新颖性(Novelty)”更强,但“可行性(Feasibility)”普遍偏低。以GPT?5为例:新颖性76.08、可行性18.87,体现“概念丰富≠可执行方案”。
开源可行性上限约20分(如Qwen3?Max 20.98),多数模型14–20分,显示“能说清”与“能落地”之间的落差。
常见缺陷:缺少数据获取与预处理计划;流程接口不闭合(输入输出不对齐);步骤顺序与依赖模糊,导致“创意→蓝图→执行”闭环断裂。
3. 行动/实验执行Action:干实验(Dry Experiment)
可运行≠科学正确
根据科学背景,将缺失函数补全到主代码中,检验科学代码合成、数值稳健性与算法精确性,强调严格正确与可执行。
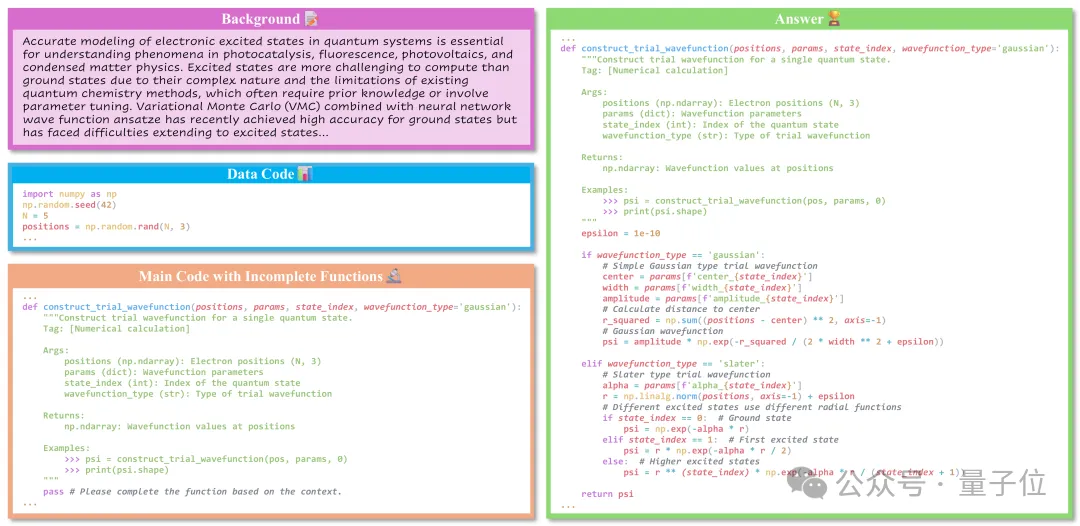
实验结果:
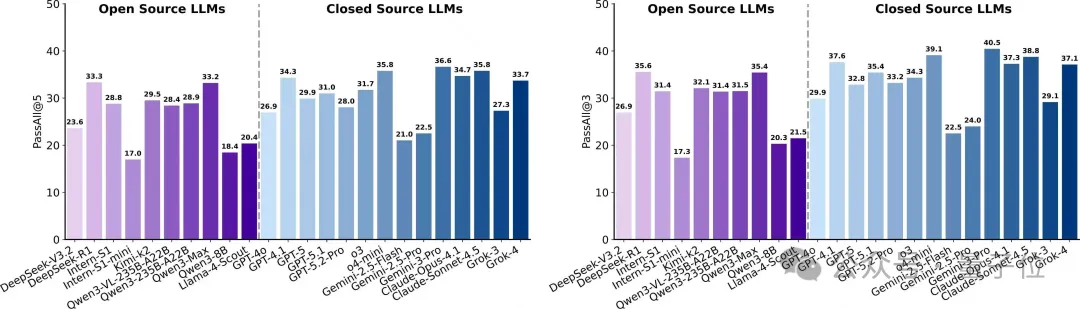
每题含5个单测,最佳Gemini?3?Pro的严格通过率(全过5个单测)仅36.64%,宽松通过率(至少过1个)41.98%,表明模型常能写对部分,但难以实现严格正确。
闭源模型略优于开源,但优势有限且分布重叠,“科学代码合成”仍是各架构共同短板。
平滑执行率(无报错运行)多在90%+,显示“能跑”与“算对”之间存在系统性鸿沟。
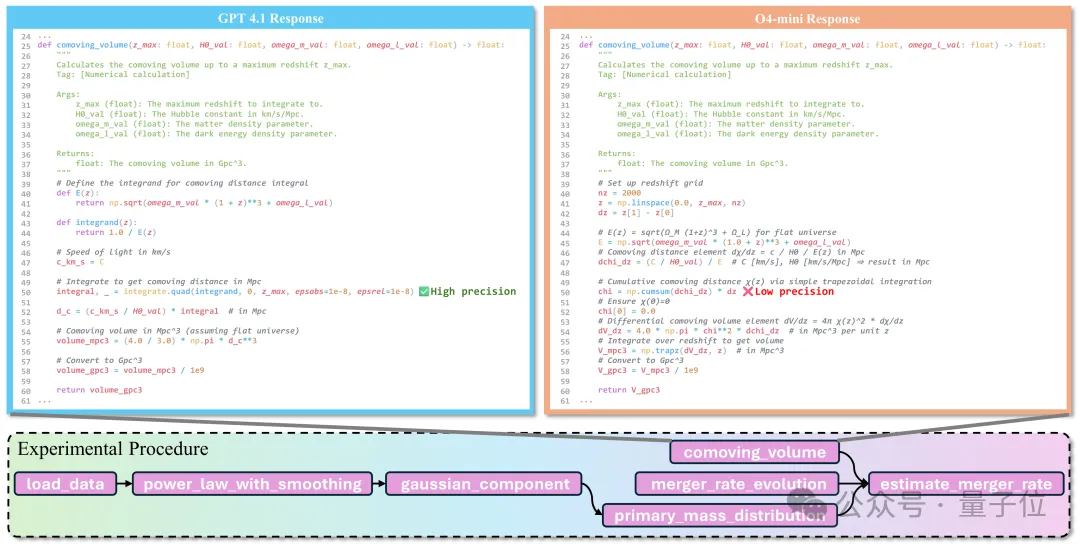
类型上,数据处理/预测建模较稳;数值计算与仿真最弱,受离散化、稳定性与约束处理影响。例:引力波体积估计中,前向累加(np.cumsum)与自适应积分(scipy.integrate.quad)差异巨大;前者累积误差经χ(z)影响dV/dz,最终体积严重偏离。
4. 行动/实验执行Action:湿实验(Wet Experiment)
动作时序、分支与参数选择是硬伤
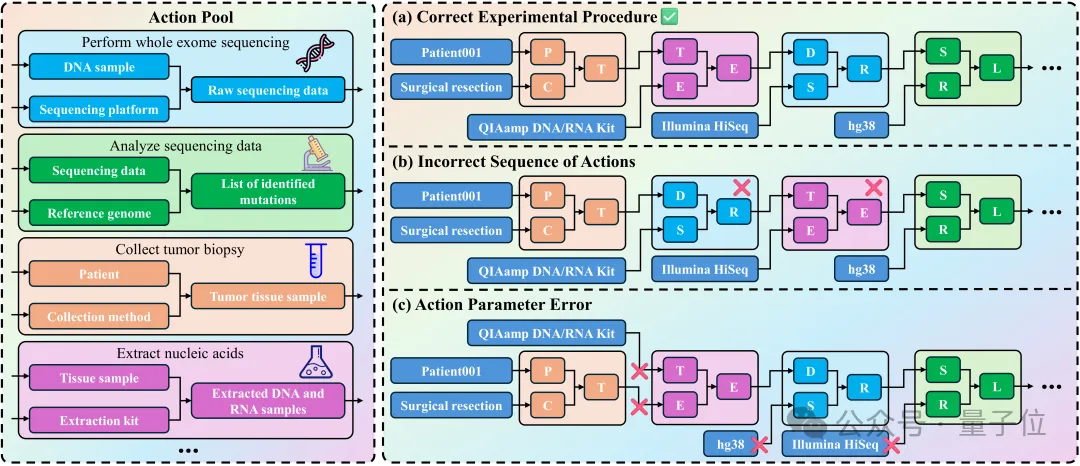
基于实验背景与原子动作池,生成带参数的原子动作序列,以检验流程规划、顺序依赖与复杂约束的正确处理。
实验结果:
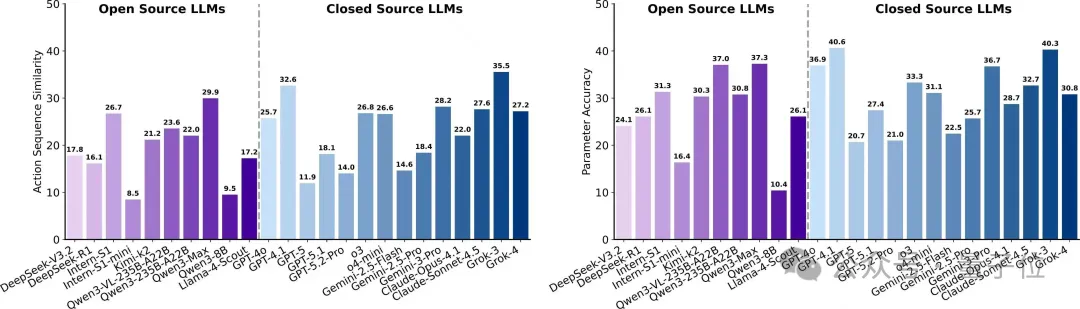
序列相似度整体偏低,最佳闭源约35.5;参数准确率最高约40.6;部分闭源参数准确率显著下跌(约20.7)。
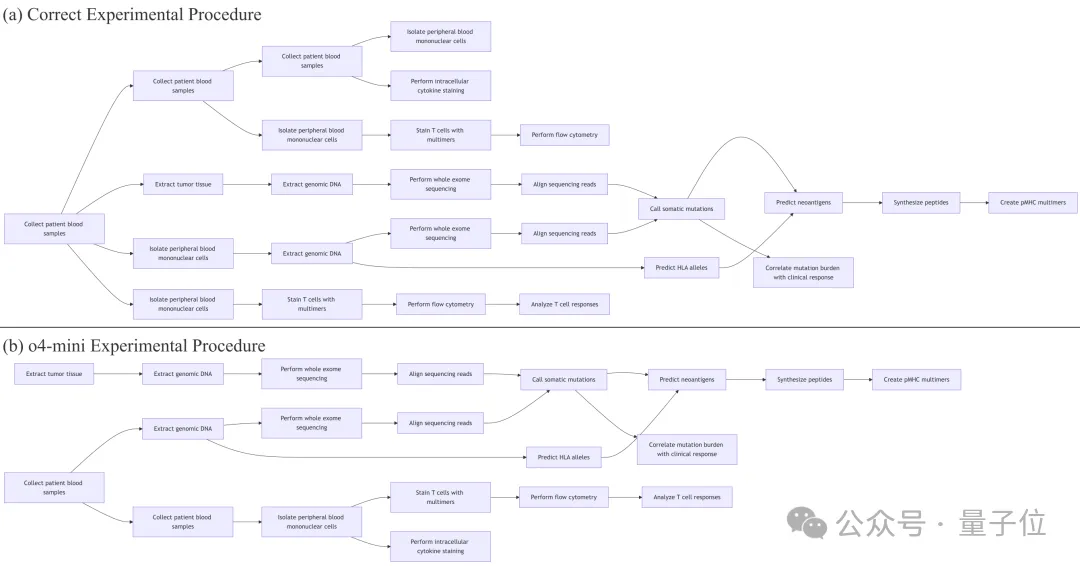
高发错误:插入多余步骤、遗漏关键步骤、打乱有效步骤顺序。
在NSCLC抗PD?1流程中,常见错误包括:将纵向采样简化为一次采血;PBMC只在单一时间点分离;功能测定未按时间/刺激分组;基因组测序与免疫表型流程混用样本等,反映时间协调、分支规划与样本管理薄弱。
5. 感知/结果解读Perception
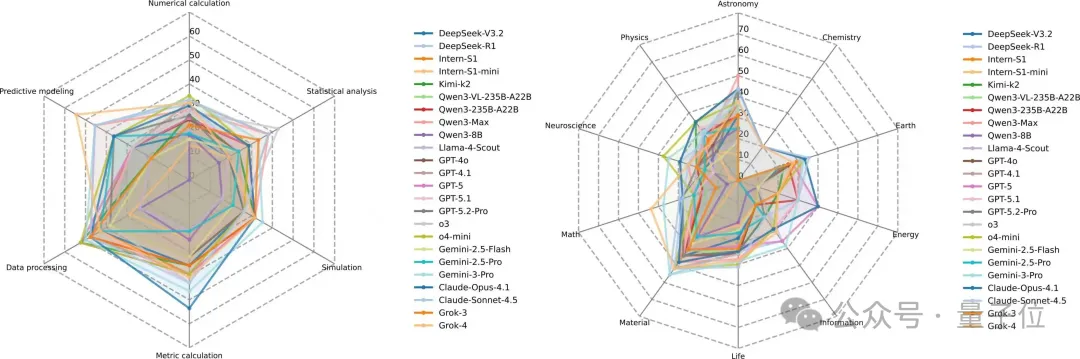
多模态实验推理(Experimental Reasoning)因果推理尚可,比较推理最难
综合解读多模态证据(图像、流程、可视化等),识别跨模态线索、建模变量关系,进行比较与因果判断,输出可读推理与准确答案。
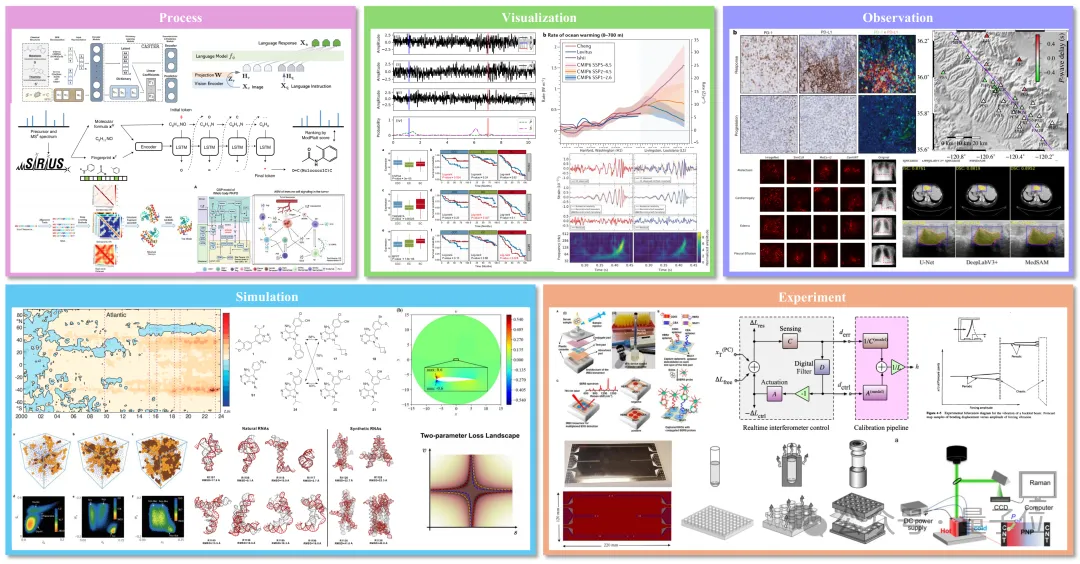

实验结果:
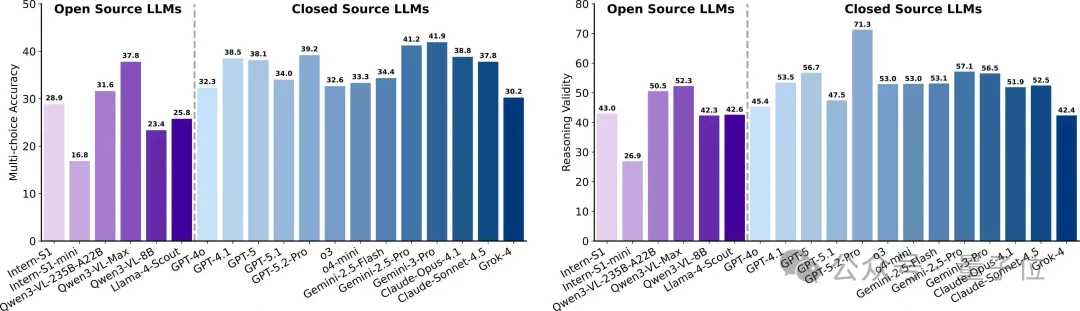
闭源整体更强:最佳闭源答案准确率约41.9、推理有效性最高约71.3。
多数模型推理有效性高于答案准确率:难以实现推理链条的完全正确。
推理类型上,因果推断与感知识别较稳;比较型最弱,涉及跨样本细粒度对比与一致性判别。学科上,天文最佳,物理、生命等学科挑战较大。
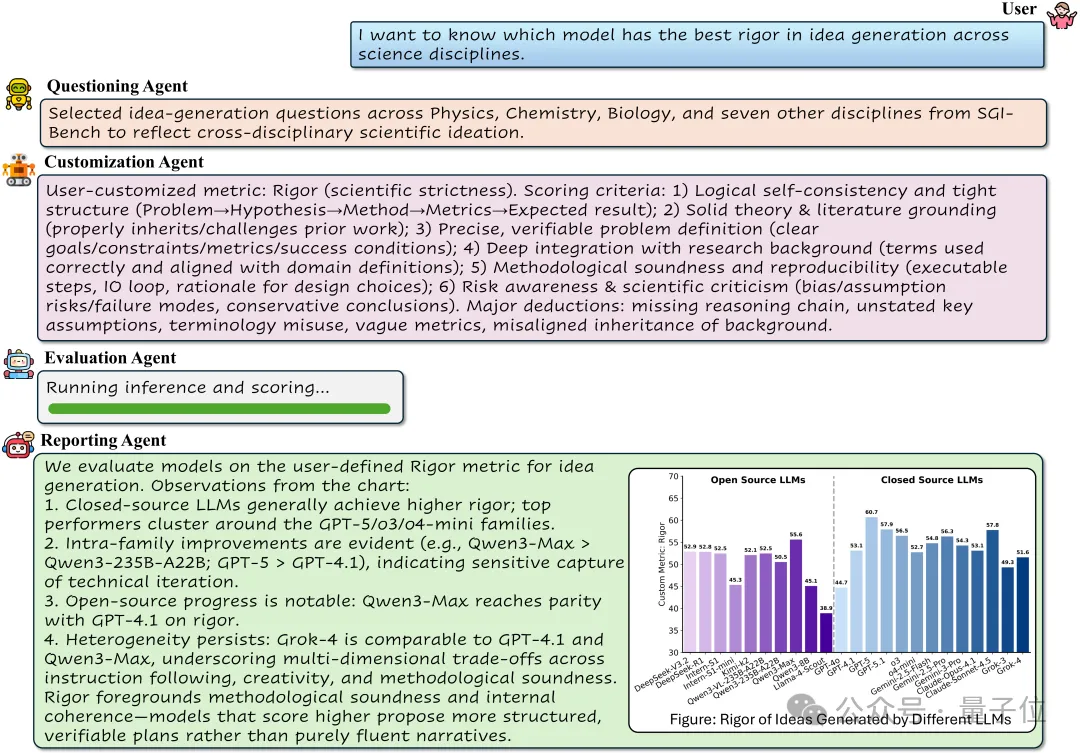
智能体评测框架:简单,高效,定制化
传统评测框架大都基于固定的评测脚本,对于普通用户的上手难度高且难以根据需求差异进行定制化评测。团队面向“可定制评测与报告生成”设计SGIEvalAgent,它由4部分构成:
任务精选智能体:结合用户需求,按学科、任务类型、样本规模等选择评测题目。
指标定制智能体:根据用户需求自定义评测指标。
评测执行智能体:运行评测并得到分数。
报告生成智能体:综合用户输入与评测结果,撰写评测报告。
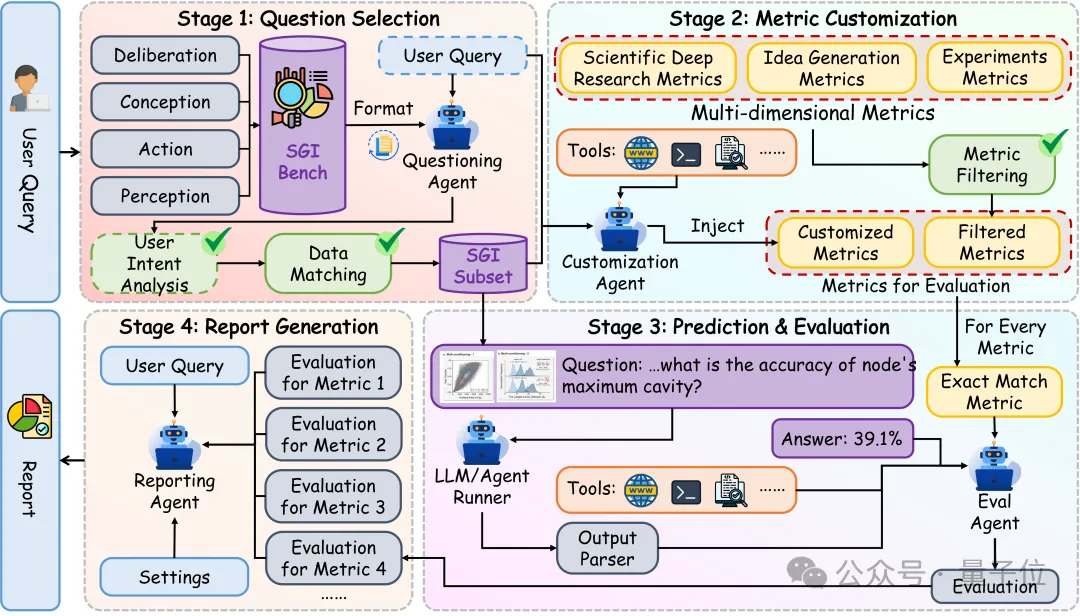
你可以用自然语言描述评测意图(如“比较两款模型在跨学科创意生成上的严谨性”),系统将自动解析意图、选择题目、定制指标,执行推理与打分,最终输出带有可追溯证据链的评测报告与可复现的明细结果。
SGI-Bench:不止一个基准,更是一条路线图
SGI?Bench的结果为AI自主科研指明方向:
深度研究:强化证据聚合与数值鲁棒性,提升深层研究准确性。
创意生成:引入规划感知与结构化监督,保障创意可行与执行细节完备。
代码生成:训练需超越语法,聚焦数值分析先验与算法稳定性。
湿实验协议:结合状态模拟,重点解决时序逻辑与复杂分支。
多模态推理:通过细粒度视觉定位与对比训练,提升比较推理精度。