国产GPU跑满血DeepSeek,可以100 tokens/s了
2025-07-26 08:25:55 · chineseheadlinenews.com · 来源: 量子位
放眼当下,到底哪个芯片跑满血DeepSeek是最快的?
答案很意外——不是你以为的英伟达,而是一家国产GPU。
因为现在它的速度,已经直接来到了100 tokens/s!

这个速度相比国外GPU的50 tokens/s和国内的15 tokens/s,已经称得上是快上了一个数量级。

若是将三者放在一起同时运行,效果会更加一目了然。
当中间的国产GPU以行云流水之势给出了完整准确答案之际,两边的“选手”则是还在深度思考过程中:
那么这个国产GPU到底是谁?
不卖关子,它就是摩尔线程。
但这时肯定有很多小伙伴会问了,从成立到现在不到5年时间,摩尔线程的何以取得如此速度。
在量子位了解完其在“算力之道”的全貌之后发现,答案,远比“做出一颗更快的芯片”要宏大和深刻。
已经造了个AI超级工厂
没错,这是因为摩尔线程在搞算力这件事儿上,已经给自家打造了一个AI超级工厂(AI Foundry)。
提到Foundry这个单词,很多人第一反应或许就是造芯片时的“晶圆厂”,它的价值取决于于生产芯片的良率、产能和工艺先进性。
但AI超级工厂,它并非指代一个物理上生产芯片的晶圆厂,而是一个类比的概念:这个AI工厂的进化,就像升级制程一样,绝不是改改某个单一技术就完事儿了,而是一个系统性、全方位的变革。
它要求整个技术栈“脱胎换骨”:从最底层的芯片架构必须革新、到集群的整体架构得巧妙设计,再到软件层面——算法怎么调更聪明,资源调度怎么跑更高效,每一个环节都至关重要。
正是这种从根儿上动起来的基础设施大改造,才能真正释放AI算力,实现大规模“生产”和“迭代”前沿AI大模型。

需要强调的一点是,要建成这样一座超级工厂,绝非暴力地将成千上万张显卡堆砌在一起这么简单。
它需要五大核心要素的紧密耦合与协同进化,缺一不可;
这个AI工厂的产能,用一套公式可概括为:
AI工厂生产效率 = 加速计算通用性 × 单芯片有效算力 × 单节点效率 × 集群效率 × 集群稳定性
摩尔线程正是围绕这五大要素,构建了技术护城河。
全功能GPU:超级工厂的基石
AI超级工厂的基石,指的是一颗具备强大通用性的“全功能GPU”。因为回顾算力的进化史,其实就是一部全功能GPU的发展史。

从最初只能加速3D图形的“显卡”(VGA Card),到开放编程接口、允许开发者创造无限可能的“现代图形处理器”,再到被广泛应用于超算、深度学习、区块链等领域的通用计算平台,GPU的每一次飞跃,都源于其通用性的拓展。
单一功能的加速器,如早期的3D加速卡或今天的某些专用AI芯片(ASIC),虽然在特定任务上效率极高,但其灵活性差、编程困难,无法适应AI模型日新月异、应用场景层出不穷的发展趋势。
一个AI模型可能既需要处理语言,也需要理解图像,甚至要进行物理世界的模拟。如果工厂的“机床”只能处理一种任务,那么它很快就会被淘汰。
因此,摩尔线程从创立之初就坚持打造真正的全功能GPU,既要“功能完备”,也要“精度完整”。

首先是“功能完备”,即芯片内部集成了四大核心引擎:
AI计算加速引擎:不仅能做推理,更能做训练,实现训推一体。
先进的3D图形渲染引擎:支持DX12等现代图形API,满足游戏、AIGC、数字孪生等视觉计算需求。
物理仿真与科学计算引擎:这是常被忽视却至关重要的一环。未来的Agentic AI、空间智能都需要与物理世界交互,强大的科学计算能力是连接数字世界与物理世界的桥梁。
超高清视频编解码引擎:AI的计算结果最终需要通过视觉和听觉呈现给人类,高清、低延迟的流媒体处理能力是人机交互体验的保证。

其次,“全计算精度”覆盖。从FP32、FP16到业界前沿的FP8,乃至更低精度的INT8/INT4,完整的精度支持让开发者可以根据不同任务的需求,在性能和精度之间找到最佳平衡点。

特别是在大模型训练中,混合精度训练已是标配,而摩尔线程是国内极少数能够提供FP8训练能力的平台。“全功能”和“全精度”能力,确保了摩尔线程的GPU这座“机床”能够承接各类AI模型生产订单。
MUSA统一系统架构:超级工厂的“总设计师”
如果说全功能GPU是工厂的机床,那么MUSA就是整个工厂的“总设计师”。一个卓越的顶层架构,能够决定一家公司未来十年甚至更长时间的技术路线和发展潜力。
MUSA的核心理念是“一个架构,万千应用”(One Architecture for Many Applications)。它采用创新的多引擎、可伸缩、可配置的统一系统架构,将GPU内部的计算、通信、内存、调度等功能进行顶层设计和统一管理。
先来看可伸缩,顾名思义,MUSA架构是可以根据不同客户、不同市场的需求,快速裁剪出优化的芯片配置,大幅降低了新品芯片的开发成本。
其次,资源全局共享,简单说,就是把所有硬件资源——像计算核心、内存、通信这些——都打通,变成一个大资源池,然后用智能调度灵活分配。
这招儿直接解决了大问题:以前那种单引擎GPU,多个任务一起跑的时候特别容易卡。现在好了,所有资源大家共享,按需取用!

再例如,统一编程接口与指令集,开发者只需学习一套API和编程模型,就能驱动MUSA架构下所有的硬件引擎,极大地降低了开发门槛,提升了开发效率。
除此之外,MUSA架构内部包含了多个摩尔线程自研的核心技术。
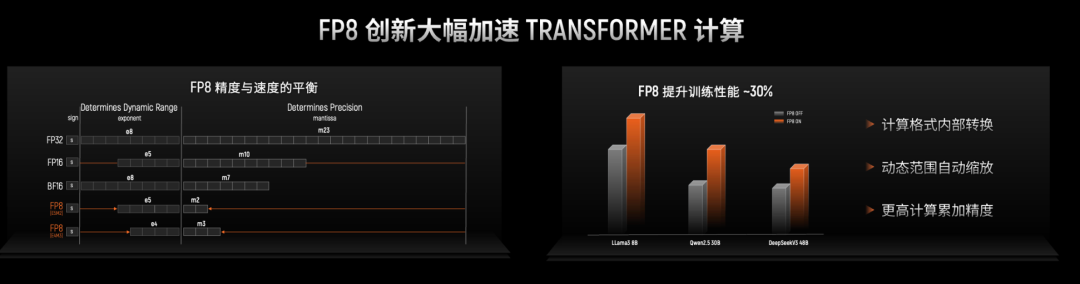
例如,专门为FP8设计的“Transformer引擎”,使其FP8的训练性能相比没有该引擎的方案能提升30%;独创的ACE异步通信引擎,可以让计算和通信并行不悖,解决了传统架构中通信会占用计算资源的痛点,减少了15%的计算资源损耗,将GPU的算力释放;自研的MTLink2.0互联协议,实现了GPU之间高效、低延迟的通信,提供了高出国内行业平均水平60%的带宽,为大规模集群部署奠定了坚实基础。
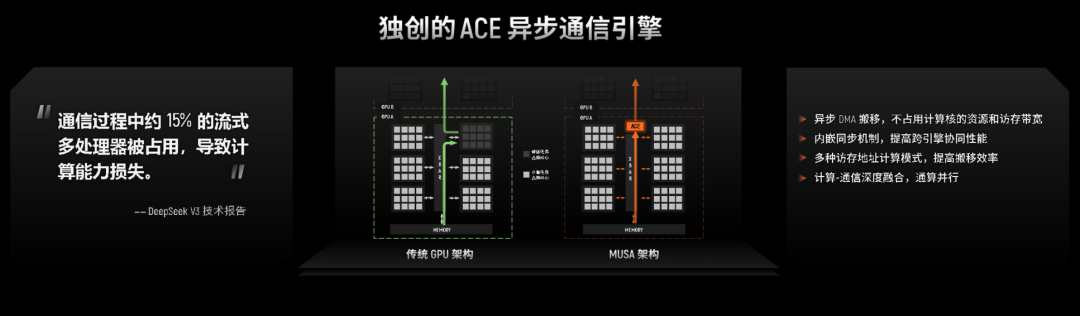
MUSA架构的先进性,确保了摩尔线程的每一颗芯片都不是孤立的算力单元,而是一个高度协同、管理高效的“作战小组”,有效提升每颗芯片有效算力,为整个AI超级工厂提供了坚实的、可扩展的算力底座。
MUSA全栈系统软件:超级工厂的“操作系统”与“工具箱”
再好的硬件,若是没有高效的软件,同样也无法发挥其全部潜力。因此,摩尔线程打造了与MUSA硬件架构深度耦合的全栈软件系统,它在AI超级工厂中扮演着“操作系统”和“开发者工具箱”的角色。
这个软件栈可以说是覆盖了从底层驱动到上层应用框架的方方面面:
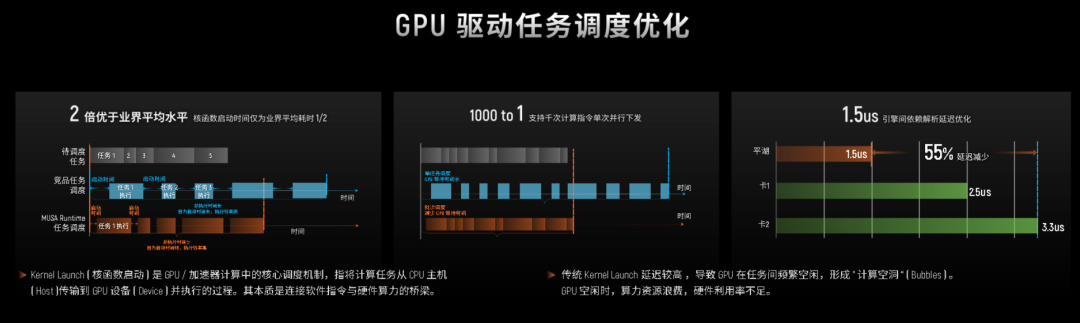
- 高效驱动:摩尔线程的驱动经过深度优化,核函数启动时间缩短50%,任务派发延迟极低,可以一次性并发处理上千个任务,领先业界水平。
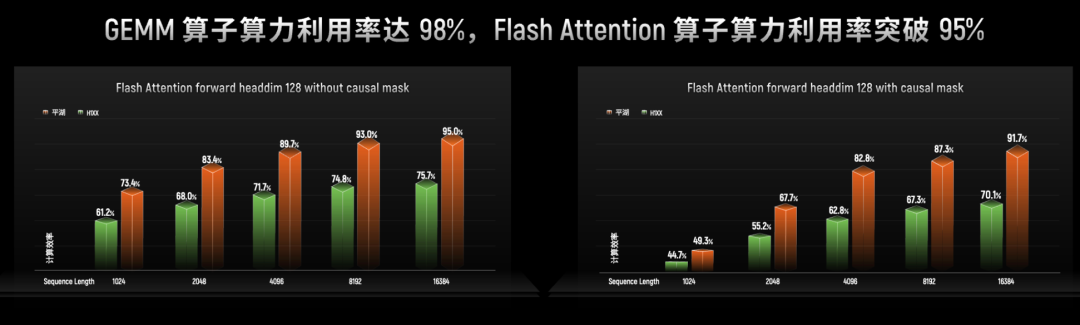
- 核心算子库:对标国际大厂的cuDNN,摩尔线程的muDNN在算子层面进行了大量优化,GEMM算子算力利用率达98%,Flash Attention 算子算力利用率突破95%。
- 通信效能跃升:MCCL训练通信库实现RDMA网络97%带宽利用率;基于异步通信引擎优化计算通信并行,集群性能提升10%。
- 生态兼容与Triton支持:通过MUSIFY等工具,实现了对PyTorch、TensorFlow等主流AI框架的无缝支持。尤其值得一提的是,基于Triton-MUSA编译器 + MUSA Graph 实现DeepSeek R1推理加速1.5倍,全面兼容Triton等主流框架。
- 完善的开发者套件:提供了一整套涵盖性能分析(Profiler)、调试、调优、一键部署等功能的工具链,如同一个“百宝箱”,让开发者能够洞察硬件运行的每一个细节,榨干硬件的每一分性能。
这套全栈系统软件,确保了开发者不仅能“用起来”,更能“用得好”,将MUSA硬件架构的强大能力顺畅地传递到上层应用,是连接硬件与算法的关键枢纽。并且通过MUSA全栈系统软件的优化,摩尔线程实现了“单节点计算效率”全面提升。
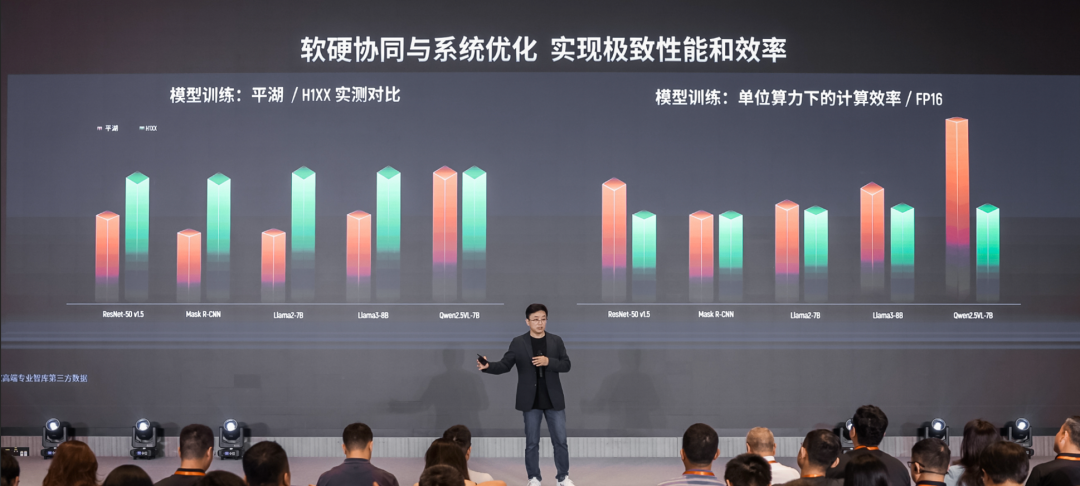
KUAE计算集群:超级工厂的“生产车间”
单卡、单节点的性能再强,也无法完成动辄千亿、万亿参数大模型的训练。AI超级工厂必须以大规模集群的形式存在。为此,摩尔线程构建了夸娥(KUAE)大规模智能计算集群。
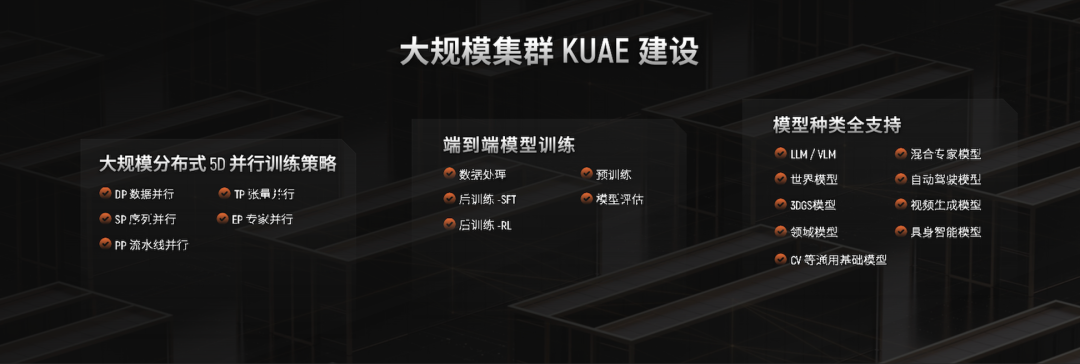
夸娥计算集群远非简单的服务器堆叠,它是一个软硬一体化的系统工程,相当于AI大模型的“生产车间”:
- 软硬一体化设计:从服务器节点、交换机到机柜,再到上层的集群管理软件、任务调度系统,全部进行了协同设计和优化。
- 创新5D并行训练:摩尔线程整合数据并行(DP)、流水线并行(PP)、张量并行(TP)等所有主流的并行训练策略,全面支持Transformer等主流架构,并能根据模型特点自动搜索和推荐最优的并行方案。
- 端到端训练优化:覆盖了从数据预处理、模型预训练、强化学习、微调到验证评估的全流程,提供一站式服务。
- 性能仿真工具(Simumax):自主研发的Simumax工具面向超大规模集群自动搜索最优并行策略,精准模拟FP8混合精度训练与算子融合,为DeepSeek等模型缩短训练周期提供科学依据。
- 高效Checkpoint:针对大模型稳定性难题,创新CheckPoint加速方案利用RDMA技术,将百GB级备份恢复时间从数分钟压缩至1秒,提升GPU有效算力利用率。
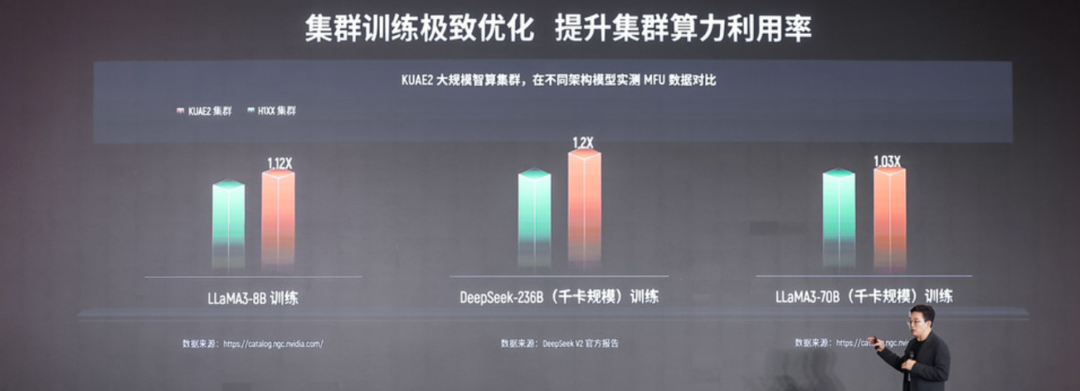
通过夸娥计算集群,摩尔线程将单点的GPU性能优势,成功扩展到了千卡、万卡乃至更大规模的集群层面,构建起了一个真正具备强大“生产力”的AI超级工厂。并且通过实测,KUAE 2大规模智算集群,在不同架构模型的MFU,已经达到了行业领先水平。
零中断容错技术:超级工厂的“安全生产协议”
对于一个需要7x24小时不间断运行的AI超级工厂来说,稳定性压倒一切。一次意外的宕机,可能意味着数百万美元的损失和数周工作的付诸东流。因此,摩尔线程开发了独有的“零中断容错技术”,这是保障工厂稳定运行的“安全生产协议”。
传统的容错机制,在硬件(如GPU卡)发生故障时,需要暂停整个训练任务,人工替换硬件,再从最近的Checkpoint恢复,整个过程耗时耗力。而摩尔线程的零中断技术则完全不同:
- 零中断容错技术:当某个节点变慢或出现故障时,仅隔离受影响节点组,其余节点继续训练,备机无缝接入,全程无中断。这一方案使KUAE集群有效训练时间占比超99%,大幅降低恢复开销。
- 多维度训练洞察:通过多维度的数据监控和AI预测模型,系统能够提前感知到哪些节点可能会成为“慢节点”,并进行预警或隔离,实现动态监测与智能诊断,异常处理效率提升50%;
- 集群自检及调度优化:在训练任务开始前,系统会自动对整个集群进行“体检”,确保所有软硬件都处于最佳状态,如同飞机起飞前的安全检查,训练成功率提高10%,为大规模AI训练提供稳定保障。

总结来看,上述的五大要素,即全功能GPU、MUSA架构、全栈软件、KUAE集群、零中断容错技术,共同构成了摩尔线程的AI超级工厂。

它是一个有机的整体,从芯片设计的最底层到集群管理的最上层,环环相扣,协同进化。正是这个完整的、端到端的体系,才造就了文章开头的性能表现。
那么接下来的一个问题是:为什么要造AI超级工厂?
这个问题的答案,或许植根于摩尔线程对计算革命过去、现在与未来的深刻洞察。
十年前,以人脸识别、自动驾驶为代表的“感知AI”大爆发,催生了第一批AI巨头。而从2022年ChatGPT横空出世至今,我们正处在“生成式AI”的指数级爆发期。
大模型的“智商”迭代速度令人咋舌,从去年还在人类平均水平的四五十分,到如今顶尖模型已经飙升至七八十分,直逼人类顶尖水准。
模型的迭代速度,也从过去的数月一更,压缩到如今的数周甚至每周一更。这场竞赛的背后,驱动力只有一个——算力。
正如马斯克能够凭借其20万张H100,让Grok模型在短时间内登顶排行榜,这残酷地揭示了一个事实:Scaling Law是AI发展的铁律。
谁拥有更大、更强的算力基础设施,谁就能更快地迭代模型,抢占技术和市场的制高点。
而展望未来五年,Agentic AI(智能体AI)和空间智能将成为新的爆发点。AI将不再仅仅是聊天的工具,而是成为可以自主完成复杂任务的“数字员工”,并与物理世界深度融合。
这一切,都意味着对算力的需求将再次呈几何级数增长。在这样的大背景下,仅仅满足于当下的计算能力是远远不够的,必须为未来更加庞大的计算需求做好准备。
面对永无止境的算力需求,仅仅追求“快”是片面的。未来的计算,更需要的是全方位的“稳”——稳定、可靠、高效、通用。
这正是建设AI超级工厂的根本原因。

训练一个万亿参数的大模型,好比建造一座港珠澳大桥,是一项极其复杂的系统工程。它对基础设施的要求,堪比建造一座芯片晶圆厂。
你不能指望靠“人海战术”,找十亿个儿童去抬起一栋大楼;同样,你也不能简单地将一万张低效的显卡堆在一起,就期望能训练出高质量的大模型。
这个过程充满了挑战,例如在成本方面,一次大规模训练动辄耗费数月和数百万美元,任何中断或失败都是巨大的损失。
再如面对复杂的系统,上千个节点、上万颗芯片如何高效通信、同步?软件和硬件如何完美适配?又该如何快速定位和解决问题?
还有在实际应用过程中,往往任务又是多样性的:今天训练语言模型,明天可能就要处理多模态数据,后天又要进行科学计算……
这些挑战,都无法通过购买单一的“最快芯片”来解决。它需要一个从底层硬件到上层软件,再到集群管理和运维服务的端到端解决方案。
这恰恰是摩尔线程“AI超级工厂”的核心价值所在——它提供的不是孤立的算力,而是一种确定性的、高效率的、高成功率的AI模型生产能力。
总而言之,摩尔线程选择了一条最艰难,但可能也是最正确的道路。他们没有满足于在某个单点上追赶或超越,而是立足于未来,从根本上思考如何为这个时代提供最先进的“生产力工具”。
这,就是摩尔线程给出的答案,一个不止于快,更关乎未来的答案。