CerebrasIPO:深度绑定OpenAI
2026-05-14 02:25:15 · chineseheadlinenews.com · 来源: 华尔街日报
Cerebras的故事突然变顺了。几年前,它还是一家用“整片晶圆做芯片”的激进AI硬件公司,技术足够大胆,但商业化一直不够确定;现在,快推理成为大模型厂商愿意付溢价的方向,OpenAI又签下750MW推理算力合作,Cerebras站到了IPO窗口前。

SemiAnalysis分析师Myron Xie在14日发布的一份研究报告把核心变化概括得很直接:“过了某个智能阈值之后,开发者更偏好更快的Token,而不是更聪明的Token。” 这句话解释了Cerebras估值逻辑的转向:它不一定要在所有AI算力场景里击败GPU,但只要“高交互速度”成为可收费产品,它的晶圆级架构就有了用武之地。
这也是Cerebras最迷人的地方。WSE-3把44GB SRAM、计算核心和片上互联塞进整片晶圆,带来21PB/s级别的内存带宽,推理速度可以达到传统HBM加速器难以触及的区间。但同一套架构也带来限制:SRAM容量不够大,片外I/O只有150GB/s,冷却、供电、封装都高度定制,服务超大模型和长上下文时会越来越吃力。
OpenAI是Cerebras的最大机会,也把风险集中到了一个客户身上。双方协议对应750MW推理算力,OpenAI还有额外1.25GW选项;Cerebras披露的剩余履约义务达到246亿美元。但这笔交易同时绑定了10亿美元工作资本贷款、接近免费行权的认股权证,以及高强度数据中心交付压力。IPO投资人真正要问的,不是“晶圆芯片酷不酷”,而是:快Token的溢价,能不能覆盖Cerebras的结构性成本和单一客户风险。
Cerebras押中的不是“总吞吐”,而是“交互速度”
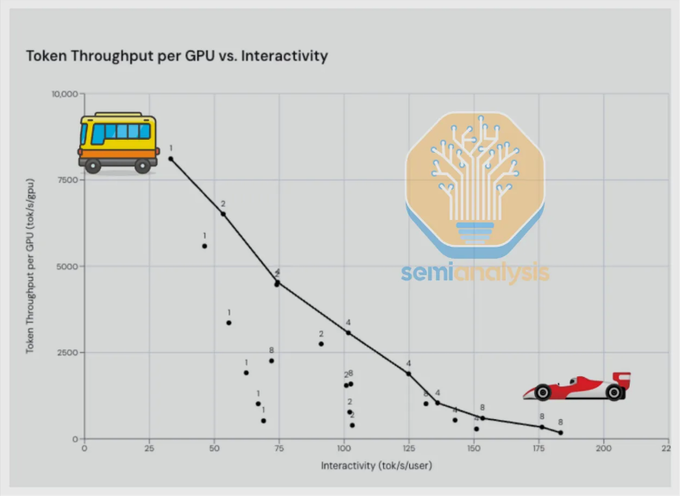
过去AI推理硬件的主线,是每张GPU、每个机柜能吐出多少Token。对云厂商和模型厂商来说,总吞吐意味着单位成本,意味着能服务更多用户。
但用户行为正在把另一条曲线推到前台:tokens/sec/user,也就是单个用户拿到输出的速度。
OpenAI、Anthropic都在把同一模型拆成不同服务档位:fast、priority、standard、batch。用户愿不愿意为更快响应付钱,已经不只是产品经理的猜测。Opus 4.6 fast曾以约6倍价格换取2.5倍交互速度,后来速度优势降到约1.75倍;即便如此,高速模式仍是开发者愿意付费的SKU。SemiAnalysis自身4月AI支出一度年化达到1000万美元,其中80%花在Opus 4.6 fast上。
这说明一个市场变化:当模型能力足够可用,等待时间就会变成生产力瓶颈。对写代码、调用工具、连续迭代的agentic workflow来说,慢几秒不是体验问题,而是工作流被打断。
Cerebras的优势正好在这里。它不是靠更多HBM堆容量,而是靠片上SRAM极高带宽,把低batch、小并发、高交互速度的decode场景做得非常快。换句话说,GPU像一辆能拉很多人的大巴,Cerebras更像为了少数乘客高速直达而设计的跑车。
WSE-3不是“大号GPU”,它是一整片晶圆
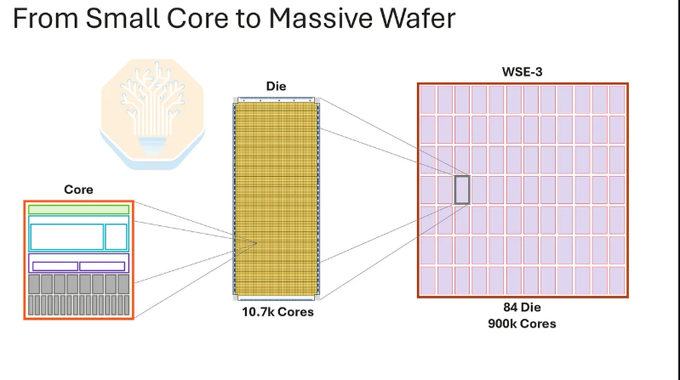
Cerebras的核心产品WSE,是把整片晶圆当成一颗芯片,而不是切割成几十、上百颗独立die。
WSE-3采用台积电N5工艺,由12×7、共84个相同步进区域组成。每片晶圆上有约97万个核心,其中90万个启用。晶圆面积的一半给SRAM,另一半给计算核心。这个设计的关键,是计算和存储都留在同一片硅上,尽量避免数据离开芯片、离开封装。
参数很夸张:
??SRAM容量:44GB
??SRAM带宽:21PB/s
??对外I/O:150GB/s
??公开营销口径FP16算力:125PFLOPs
??按8:1非结构化稀疏折算后的dense FP16算力:约15.6PFLOPs
这组数字要分开看。21PB/s内存带宽是Cerebras最强的地方;15.6PFLOPs dense FP16算力也不低,但如果按单位硅面积衡量,并不像宣传口径那么惊人。125PFLOPs来自稀疏假设,材料里把这种算法调侃为“Feldman’s Formula”,对应的是把dense算力乘以8。
真正的分界线在内存类型。GPU、TPU、Trainium这类主流AI加速器把模型权重和KV Cache放在HBM里;Cerebras把它们尽量放进SRAM。SRAM快、延迟低,但单位bit成本高,容量密度低。
44GB SRAM放在单芯片世界里很大。可和HBM比,它又不大。单个HBM3E 12-Hi堆栈就有36GB;当前一颗高端GPU或TPU封装常见8堆栈,对应288GB,是WSE-3 SRAM容量的6.5倍。
这就是Cerebras的基本交换:用容量换速度。
晶圆赢在低算术强度decode,输在大模型和长上下文
Cerebras最适合的任务,是低算术强度、内存带宽受限的decode阶段。
大模型推理里,很多kernel并不是缺算力,而是缺内存带宽。GPU的Tensor Core可能很强,但如果权重和KV Cache喂不上来,算力就会饿着。Cerebras把大量SRAM铺在晶圆上,数据离计算单元更近,带宽足够高,batch=1这类低并发decode场景能跑出传统HBM系统很难达到的交互速度。
材料中的理论对比很清楚:如果看一个batch=1、算术强度约为2的decode kernel,NVIDIA GPU和Groq LPU理论上只能实现几十到数百TFLOPs量级;Cerebras WSE-3在理想条件下可以接近完整15.625PFLOPs dense FP16算力。
这就是“快Token”的硬件基础。
但只要模型变大、上下文变长,44GB SRAM就开始紧张。推理系统的内存要装三类东西:
??模型权重;
??并发请求所需KV Cache;
??长上下文带来的更大KV Cache。
agentic coding这类工作负载尤其麻烦。样本测算中,约43.2万条请求、约800亿Token显示,典型P50输入序列长度约为96.3k Token,而不是Cerebras产品假设中的64k;接近50%的请求超过128k,这已经达到Cerebras公开端点目前支持的最大上下文窗口。
这意味着,如果未来模型服务走向256k、1M上下文,Cerebras要么压缩KV Cache,要么上更多晶圆,要么牺牲交互速度和经济性。
冷却和BOM说明:这不是便宜算力
CS-3系统不是把一颗芯片插进服务器那么简单。
每台CS-3包括一个WSE-3 engine block、外围计算和I/O模块、两个机械泵、12个3.3kW电源模块,以及液冷系统。单片WSE-3本身功耗约25kW,放在46,225平方毫米晶圆上,平均热流密度约50W/cm?,还没算热点。
风冷却不现实。普通3D均热板如果放大到21.5厘米见方,会遇到毛细极限,工质回流跟不上。Cerebras只能做定制液冷结构:冷板、晶圆、柔性连接器、PCB组成四层“三明治”,散热歧管接在冷板背后。硅和PCB热膨胀系数不同,传统封装会裂,所以连接、预压、装配工具都要定制。
数据中心侧也被改变。GB200 NVL72参考设计的设施侧流量约1.5 LPM/kW,而WSE-3在25kW下约100 LPM,相当于4 LPM/kW,接近3倍。这要求更大的泵、更粗的管、更大的CDU和更高流量的快接头。CS-4若能把机架级流量拉回1.5—1.7 LPM/kW,才更接近标准化基础设施。
成本同样不轻。CS-3加KVSS CPU节点的BOM估算,在去年四季度内存涨价前约35万美元/机架;计入最新内存价格后约45万美元/机架。KVSS是双路AMD CPU节点,配6TB DDR5 RDIMM,用于KV Cache offload。
有意思的是,最贵的不只是台积电N5晶圆。单片N5晶圆名义成本约2万美元,但Cerebras还要为每批晶圆做额外上层金属mask,用来绕过缺陷tile;Vicor定制供电模块也很贵,材料中估计其价值量接近台积电内容;冷却、封装、组装大量自研,外围还有12个100GbE Xilinx FPGA承担类似NIC的角色,把Cerebras自有I/O转换成以太网。
所以Cerebras并不是“便宜芯片替代GPU”。它是在一个特定推理速度区间,用复杂系统换极致交互速度。
SRAM扩展停滞,是Cerebras绕不过去的节点问题
Cerebras最依赖SRAM,但SRAM scaling正在失速。
三代WSE的SRAM容量变化很能说明问题:
??WSE-1,台积电16nm,18GB SRAM;
??WSE-2,7nm,40GB SRAM,代际提升2.2倍;
??WSE-3,5nm,44GB SRAM,只提升约10%。
同样从7nm走到5nm,逻辑晶体管数量增长约50%,但SRAM容量几乎没怎么动。往后更难。N3E相对N5在SRAM上基本没有缩小,N2及以后也继续受限。
对Cerebras来说,这比对GPU厂商更致命。GPU可以继续叠HBM、扩封装、靠互联池化内存;Groq这类SRAM机器也可以用hybrid bonding在Z方向堆更多SRAM tile。Cerebras是整片晶圆,平面面积已经用满。如果增加SRAM面积,就要牺牲计算面积。
CS-4的路线也暴露了这一点:仍使用N5基础的WSE-3,但提高功耗、提升时钟和计算持续能力,SRAM容量不变。
可选方向是晶圆对晶圆混合键合,把DRAM晶圆或更多存储叠到WSE上。Cerebras确实在探索这种路径。但晶圆级整体芯片的热机械问题、bond wave问题,都比常规hybrid bonding更难。它过去解决过很多不寻常问题,但下一步仍然是硬仗。
最大硬伤是I/O:晶圆很大,出口却很窄
WSE-3片外带宽只有150GB/s,也就是1.2Tb/s。相对它的计算规模和片上带宽,这个出口太小。
这个问题不是工程师没意识到I/O重要,而是晶圆级架构自身的几何约束。
WSE由84个相同步进区域组成,每个reticle曝光图案必须一致,逻辑、SRAM、布线位置都一样,才能让跨划片道互联在晶圆上连续延伸。也就是说,不能只在边缘reticle放SerDes PHY,而中间reticle全做计算。每个reticle都必须长一样。
如果要增加边缘I/O,就要在每个reticle里都放PHY。问题是,中间那些PHY没有办法连接外部世界,只会变成浪费的硅面积。更糟的是,高速SerDes PHY面积大、模拟电路不喜欢贴近数字逻辑,还要guard region;放进晶圆内部,会在2D mesh里打洞,增加绕线和延迟,削弱晶圆级互联本来要解决的问题。
材料里给了一个直观数字:WSE当前片外带宽约0.17GB/s/mm边缘密度,NVIDIA片外I/O密度约为其130倍。
Cerebras的解法是光互联晶圆:通过混合键合把光子互联晶圆叠到WSE上,让数据沿Z轴进出,而不是从晶圆边缘挤出去。合作方是Ranovus。
这条路很漂亮,也很难。光学器件对温度敏感,不能太热也不能太冷;它还要贴着一片高功耗晶圆。光纤耦合在普通CPO里都还没完全工程化到轻松量产,更不用说放大到整片晶圆。
大模型会迫使Cerebras用流水线,而这违背了“快”的初衷
如果模型装不进一片WSE,就只能跨多片晶圆切分。
但低I/O带宽排除了很多常见并行方式。高带宽collective通信不现实,大张量频繁进出晶圆也不现实。剩下最可行的是pipeline parallelism:按层把模型切到多片WSE上,每片晶圆保留对应层权重,只在阶段之间传激活值。
Cerebras服务Llama 3 70B时,就是把模型切到4片WSE-3上,只在晶圆之间传激活,通信量能压在1.2Tb/s I/O能力范围内。
但流水线会带来三个问题。
第一,pipeline bubble。4个阶段至少需要约4个in-flight microbatch保持忙碌;16个阶段就需要约16个。阶段越多,调度越难。
第二,每个in-flight microbatch都有自己的KV Cache,而KV Cache也要和权重一起挤在44GB SRAM里。哪怕新模型用更强KV压缩,KV在片上片下搬运仍会以毫秒级增加TTFT和TPOT压力。
第三,晶圆数量增加,激活在晶圆间传输的固定延迟也线性增加。模型越大,越偏离Cerebras最理想的形态:小batch、低延迟、单片或少数晶圆高速decode。
公开产品线也透露了边界。Cerebras Inference Cloud目前最大生产模型是GPT-OSS,120B总参数;更大的preview模型GLM 4.7也到355B为止。Llama 70B和405B曾经受欢迎,后来被下线,可能与服务经济性有关。DeepSeek V3和Kimi K2这两个2025年热门开源前沿模型,也没有出现在Cerebras公共云上。
不过这不是绝对死局。DeepSeek V4 Pro这类模型如果采用更强KV Cache压缩,在足够并发下,1T+模型也可能重新变得可服务。问题在于,能不能同时保住Cerebras最值钱的东西:速度。
OpenAI把Cerebras拉进主牌桌,也把风险集中到自己身上
OpenAI在Cerebras未来里不是普通客户。
2025年12月,双方签署Master Relationship Agreement。OpenAI承诺购买750MW AI推理算力,2026—2028年分批部署,每批期限3—4年,可延长到5年。OpenAI还有选择权,可额外购买1.25GW,把总量提高到2GW。
S-1披露,截至2025年12月31日,Cerebras剩余履约义务为246亿美元。更重要的是,数据中心租金、电力、租赁改良、安全等pass-through成本由OpenAI报销,并按总额确认为收入。
OpenAI还提供10亿美元工作资本贷款,年利率6%。如果Cerebras通过交付算力或硬件偿还,对应利息可豁免。偿还从初始250MW最后一批交付后开始,三年等额摊还。如果MRA因OpenAI重大未补救违约以外原因终止,Cerebras可能要立即偿还全部未偿本金和应计利息。OpenAI还可以指示托管银行停止按Cerebras指令使用资金,转为直接控制资金处置。
股权绑定也很深。Cerebras向OpenAI发行33,445,026股Class N无投票权普通股认股权证,行权价0.00001美元,几乎等同免费。其中一部分因10亿美元贷款已立即归属,另一部分和400亿美元市值或付款门槛挂钩,剩余部分和算力交付、额外2GW扩张选项相关。完全稀释后,OpenAI最多可持有Cerebras约12%股份,不包括后续新发行。
按ASC 505-50,给客户的权益激励会在商业协议期内作为contra-revenue确认。以S-1中82.02美元/股估值粗算,全部认股权证理论上对应约27.4亿美元contra-revenue,约为OpenAI预期收入的10%。
这是一笔能改变命运的订单,也是一个把公司命运押到单一对手方上的结构。
GPT-5.3-Codex-Spark证明了速度价值,但也暴露模型尺寸问题
OpenAI发布GPT-5.3-Codex-Spark后,Cerebras的叙事更完整了。这个模型使用gpt-oss-120B架构,由真正的GPT-5.3-Codex蒸馏而来,在Cerebras上最高可跑到2000 tok/sec/user。
关键在“120B”。它不是完整GPT-5.3-Codex,而是小得多的蒸馏模型。材料中明确写到,它比完整模型小10倍以上。
这对Cerebras既是好消息,也是限制。
好消息是,120B级别模型如果能力足够强,再叠加极快输出速度,确实可能成为高价值产品。开发者已经证明过,愿意为了更快Token放弃部分前沿智能。
限制在于,OpenAI如果要在Cerebras上跑1T参数以上、1M上下文窗口、面向真实agentic workload的大模型,就要接受明显成本取舍,并且实际交互速度可能低于1000 tok/sec。能不能卖出足够高的Token溢价,是商业模型成立的关键。
材料给出的路径假设很激进:小模型能力继续提升,约一年内120B形态可能接近GPT-5.5级别智能。如果这成立,Cerebras就不需要承载最前沿、最大参数模型,也能卖出高价快Token。OpenAI锁定的750MW只是第一步,真正的上行空间来自是否行使额外1.25GW选项,甚至继续扩大采购。
但这个上行条件很窄:Cerebras必须证明,能在自己硬件适合的模型尺寸里,持续装下足够聪明、足够赚钱的模型。
IPO的核心问题:快Token溢价能不能长期覆盖硬件取舍
Cerebras不是另一个GPU故事。它不是在训练、大模型通用推理、长上下文吞吐上全面替代NVIDIA,而是在一个更窄但可能很赚钱的区间里押重注:高交互速度、低batch、用户愿意付溢价的推理。
晶圆级架构给了它极强的带宽和极快decode,也让它背上了SRAM容量、片外I/O、冷却、BOM、数据中心适配这些硬约束。OpenAI订单解决了需求问题,却没有消除交付风险和客户集中度。
所以Cerebras的IPO定价,不该只看246亿美元backlog,也不该只看2000 tok/sec/user这种漂亮速度。更重要的是三个问题:
??OpenAI需要的快Token,长期是不是120B—355B这类模型就够;
??用户愿意为速度付出的溢价,能不能覆盖Cerebras更复杂的系统成本;
??750MW到2028年能否按节奏落地,且不被冷却、电力、供应链和数据中心能力拖住。
如果答案偏向“是”,Cerebras会成为快推理时代最有辨识度的AI硬件公司之一。如果答案偏向“否”,整片晶圆带来的速度优势,可能会被大模型和长上下文的内存需求一点点吃掉。