实测GPT5.5:最强模型不是嘴炮,是真能干活
2026-04-24 10:25:25 · chineseheadlinenews.com · 来源: 钛媒体APP
GPT-5.5,终于发布。
作为OpenAI当下最强的模型,这次更新的亮点是“为真实工作而设计”。
和过去的模型相比,GPT-5.5能更快理解使用者真正想做的事情,也能自己承担更多执行过程,可以在线检索信息、分析数据、生成文档和表格、操作软件,并在不同工具之间来回切换,直到把任务完成。
用户不再需要精细地拆解每一步,可以直接给它一个混乱、多步骤的问题,让它自己规划路径、调用工具、检查结果,在不确定中继续推进。
有网友直接评价,这是目前为止最接近AGI的模型。
目前,GPT-5.5已经在ChatGPT和Codex中向Plus、Pro、团队版和企业版用户逐步开放,GPT-5.5 Pro则面向Pro及以上用户。API版本尚未上线。

模型性能
先来看看模型在基准测试中的得分情况。
其中最值得关注的指标是GDPval,这个测试不是传统选择题,而是用44种真实职业任务来评估模型,比如分析数据、写报告、做判断。
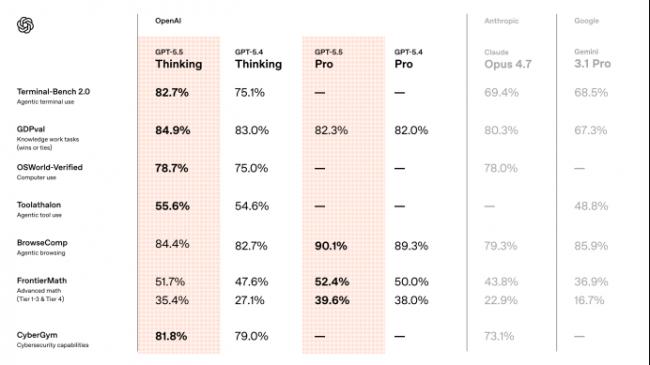
GPT-5.5的成绩是84.9%,相比GPT-5.4的83.0%,有一定的提升,也高于Claude Opus 4.7 的80.3%和Gemini 3.1 Pro的67.3%。
第二个关键测试是OSWorld,用来衡量模型在真实电脑环境中的操作能力。GPT-5.5 达到78.7%,高于GPT-5.4的75.0%,提升幅度不算夸张,但意义很大。
这项能力考验了一个更现实的问题:模型不仅能告诉你怎么做,还能不能直接替你去做,包括点击界面、切换工具、执行多步骤操作。
还有Tau2 Telecom,这是一个电信客服流程测试,GPT-5.5 在无需额外调优的情况下达到98.0%。这类任务更接近企业里的真实工作,需要在复杂、多步骤、有上下文依赖的流程中完成。
在更细分的能力上,GPT-5.5的编程能力继续提升,在Terminal-Bench 2.0上达到了82.7%,在SWE-Bench Pro上达到了58.6%。
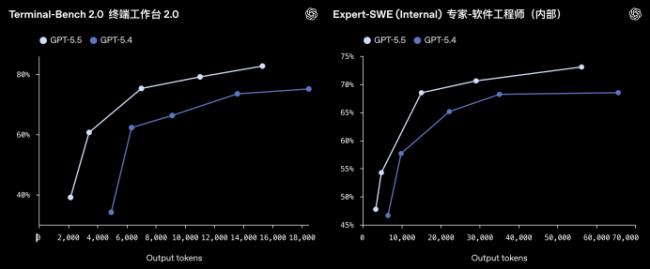
在其他知识工作基准测试中,GPT-5.5的表现也很出色:FinanceAgent得分60.0%,内部投资银行建模任务得分88.5%,OfficeQA Pro得分54.1%。说明它在结构化分析和数据处理上已经相当成熟。
科研方面虽然分数提升相对温和,但已经出现能够参与推理、验证甚至辅助发现新结果的案例,这一点更像能力边界的变化,而不是简单的性能增长。
把这些跑分放在一起看,会发现这次模型的评价标准正在发生变化:过去我们常用MMLU、GPQA这样的指标看模型的知识和推理能力,但现在更侧重于GDPval、OSWorld这类“任务级评估”。
相比起问模型知不知道某项知识,现在更看重它能不能完成一项完整工作。
这也对应了GPT-5.5本次的更新重点。模型开始能够自主地组织步骤:先获取信息,再做判断,必要时调用工具,最后把结果整理成可以直接使用的输出。
在编程上,它参与整个开发流程,而不只是生成代码;在知识工作中,它产出报告、模型和决策建议,而不只是提供答案;在操作层面,它甚至可以直接进入电脑环境,把这些步骤执行出来。
这一代模型更像一个可以协作的执行者,得分只是表面,更重要的是这些分数背后指向的一件事:GPT-5.5的定位,从“回答”转向了“执行”。
顺便一提,根据ARC Prize官方验证,GPT-5.5在ARC-AGI-2基准测试中取得最高85.0%的准确率,成为了新的SOTA模型。

除了能力本身,这一代模型还有一个被反复强调的点:效率。
OpenAI给出的数据是,在实际服务中,GPT-5.5的速度与GPT-5.4基本持平,但在完成同样Codex任务时使用的token明显更少。这一点对API用户尤其重要,因为它直接决定了真实使用成本。
在定价上,GPT-5.5 API为每百万输入token 5美元、输出30美元,Pro版本更高。这个价格是GPT-5.4的两倍。
不过OpenAI的逻辑是:单价虽然提升,但由于任务完成效率更高,总成本未必上升。

另外,安全体系也在同步升级:GPT-5.5是目前防护最严格的一代模型,在发布前经历了完整的安全评估流程,包括内部与外部红队测试,以及针对网络安全、生物等高风险能力的专项验证,并结合了近200个真实使用场景进行调整。
模型表现
作为一个擅长复杂任务的模型,GPT-5.5的编码优势在Codex中表现尤为突出,可以完成从实现和重构到调试、测试和验证等工程工作。
根据官方文档,它在真实工程上表现很好:在大型任务中能够持续保持上下文(不会只盯着一小段代码);在问题不明确时,能够推理出故障原因;会用工具去验证自己的假设;能把修改真正“贯穿”到整个代码库,而不是只改一处。
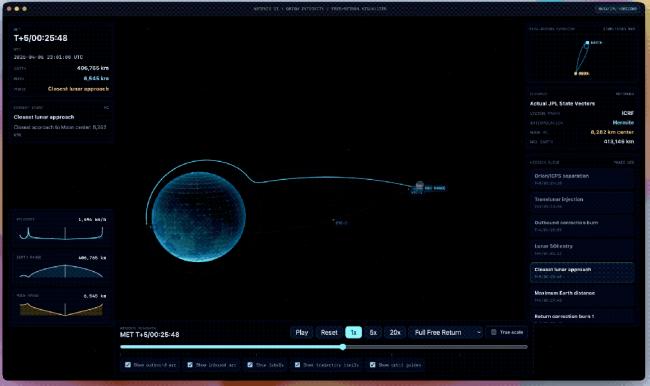
官方给出了一些比较复杂的示例,例如把一张天体图片重新做成一个新的Web应用。
技术上要求用WebGL做3D渲染、用Vite搭项目,内容上要尽量接入ArtemisII任务的真实数据,把轨道、飞行路径、天体位置这些信息真实地表现出来。
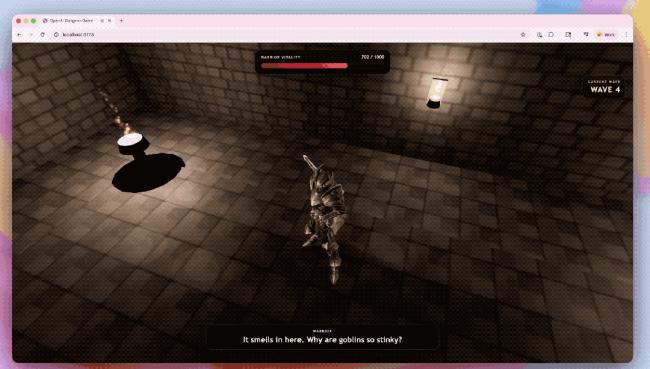
还有让GPT-5.5结合Codex生成的3D地牢竞技场原型。
模型不仅搭建了游戏架构,还写出了基于Three.js的前端实现,并覆盖了战斗系统、敌人机制和界面反馈等关键模块;环境贴图和角色对话也由GPT生成。只有角色模型和动画交给了第三方工具处理。
在编程能力之外,GPT-5.5的能力已经延伸到更广泛的知识工作,由于它更擅长理解真实意图,所以可以更自然地跑完整个知识工作的流程:从获取信息、抓住重点、调用工具、检查结果,到把原始材料整理成真正有用的输出。
在Codex里,GPT-5.5在生成文档、表格和演示文稿方面,比GPT-5.4更强。OpenAI 内部已经在真实工作中使用这些能力:目前,公司内部超过85%的员工每周都会使用 Codex,覆盖软件工程、财务、传播、市场、数据科学和产品等多个团队。
例如下列演示,就是使用GPT-5.5生成财务建模。
除了官方的复杂demo,为了看清模型在“单次生成”层面的表现,我们也做了一些更偏基础能力的测试。
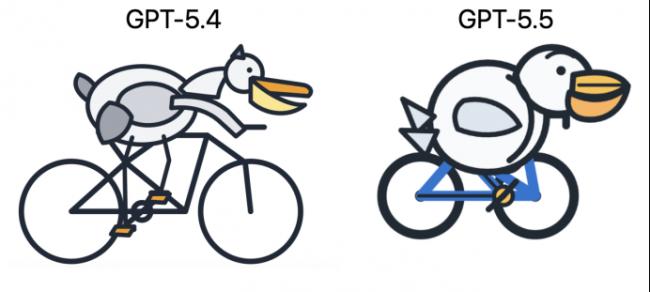
首先是每次都被拉出来的鹈鹕骑自行车,左边是GPT-5.4的表现,右边是GPT-5.5。
还有六边形小球滚动,可以看模型的物理理解。

在审美上,我们用一句话让GPT-5.5设计了一个高端品牌网站,效果如下。
prompt:Design a premium brand website with a strong identity, focusing on typography, spacing, and a cohesive visual style. Avoid generic layouts.Use Chinese.Can run entirely in a single HTML file.

接下来让它自由发挥,创造一个Unity风格的复杂SVG动画。
prompt:Create a complex svg animation that an engineer with a background in unity would appreciate.Can run entirely in a single HTML file.
编程能力之外,像在社媒上很火的洗车问题,我知道肯定也会有人想问。

这类问题一般难以回答的原因是,模型并不会默认车一定要开过去才能洗(可能有上门洗车的服务)。不过既然需要“理解用户真实意图”,我想这并不是什么答错的理由。
模型定位
如果把GPT-5.5放在过去这一年的演进脉络里看,它并非单纯地围绕模型能力做提升,而是在逐渐改变模型的使用方式。
这条线其实可以从GPT-4o开始算起。当时最大的变化是把文本、图像和语音放进同一个模型里处理,多个能力被放在同一个系统中完成,模型的内部开始变得统一。
GPT-5把这种“统一”延伸到了使用层。模型不再只是等待用户提问,然后给出一次性尽可能完整的回答,它多了一层判断:这个问题需要多快的响应、多深的推理,要不要调用工具。
后面的几个5系版本,基本都在把这件事做细。
在GPT-5.3这一阶段,编码能力和工具调用被明显强化,模型开始更稳定地完成多步骤代码生成、调试和执行流程。它不只是写代码,还会自己一步步改、修错误,最后给出一个能用的结果。与此同时,它用工具的方式也变得更自然,不再是生成一堆看不懂的调用代码,而是直接把该调用的工具给用上。
到了GPT-5.4,重点已经转向computer use和工作流能力,模型可以在不同应用之间来回切换,比如查资料、整理信息、再生成结果,一步步把事情做完。同时,响应速度、token利用率和长任务中的稳定性也在持续优化:它的反应更快了,回答更干脆,不再动不动就写一大段推理过程,在连续做一件事的时候,也更少出现前后说不一致的情况。
这些调整放在一起,能看出一种变化:模型开始更像一个在后台持续运转的系统,而不是一次性的问答工具。
用户与模型之间的关系也在发生变化,从一问一答,变成把一件事情交给它,然后看它一步步往下做。
顺着这条路径看,GPT-5.5的位置就比较清楚了。它不只有性能上的提升,还在继续把模型往任务执行的方向推进。
OpenAI将这一次的升级称为“very strong model”、“为真实工作而设计的一类新智能”,强调模型在持续运行时的效率和稳定性,比如在更长时间内完成一整套流程,用更少的计算支撑更多步骤。
很多人会同时感觉它更快了,也更“短”了,本质上是模型开始主动控制自己的计算方式,把更多资源留给真正需要展开的部分:单次回答不再一味追求展开,而是更贴近任务本身的需求。
对于需要连续操作的场景来说,这种变化非常有价值。同样一件事可以用更少的token完成,不仅是体验上的提升,也直接影响到最终的成本。
当模型开始承接完整流程,评价标准也会随之改变。比起单次回答的好坏,更重要的是它能否稳定高效地把一件事做完。
毕竟,更适合真实工作场景的模型,才是好用的模型。
