刘知远语出惊人:明年,“AI造AI”
2025-12-30 02:25:23 · chineseheadlinenews.com · 来源: 腾讯科技
过去半个世纪,全球科技产业的资本开支与创新节奏,都和一个规律紧密相连,那就是摩尔定律——芯片性能每18个月翻一番。
在摩尔定律之外,还有一个“安迪-比尔定律”,它讲的是,摩尔定律所主导的硬件性能提升的红利,会迅速被软件复杂度的增加所抵消。安迪指的是英特尔前CEO安迪·格鲁夫,而比尔,指的是微软创始人比尔·盖茨。
这种“硬件供给、软件消耗”的螺旋上升,驱动了PC与互联网时代的产业进化。

清华大学计算机系副教授刘知远及其联合创立的面壁智能团队,也是其中的典型代表。他们发布的MiniCPM("小爸炮")系列模型,仅用约1/10的参数规模,即可承载对标云端大模型的智能水平,成为端侧高效AI的案例。
2025年11月,刘知远团队的研究登上全球顶级学术期刊《自然·机器智能》(Nature Machine Intelligence)封面,正式提出大模型的“密度法则”(Densing Law)。

腾讯科技:我们今天的主题是您和团队最新发表在《自然·机器智能》上的关于大模型“能力密度”(Densing Law)的论文。您能介绍一下这项研究的背景吗?

图:Densing Law论文登上Nature Machine Intelligence封面
腾讯科技:这项研究是否因为中国的国情,使我们更重视大模型的效率问题?它在国内外是独一无二的吗?

腾讯科技:在“密度法则”中,一个关键概念是量化“智能”,但这本身是一个难题。在研究开始前,您为什么觉得这件事是行得通的?

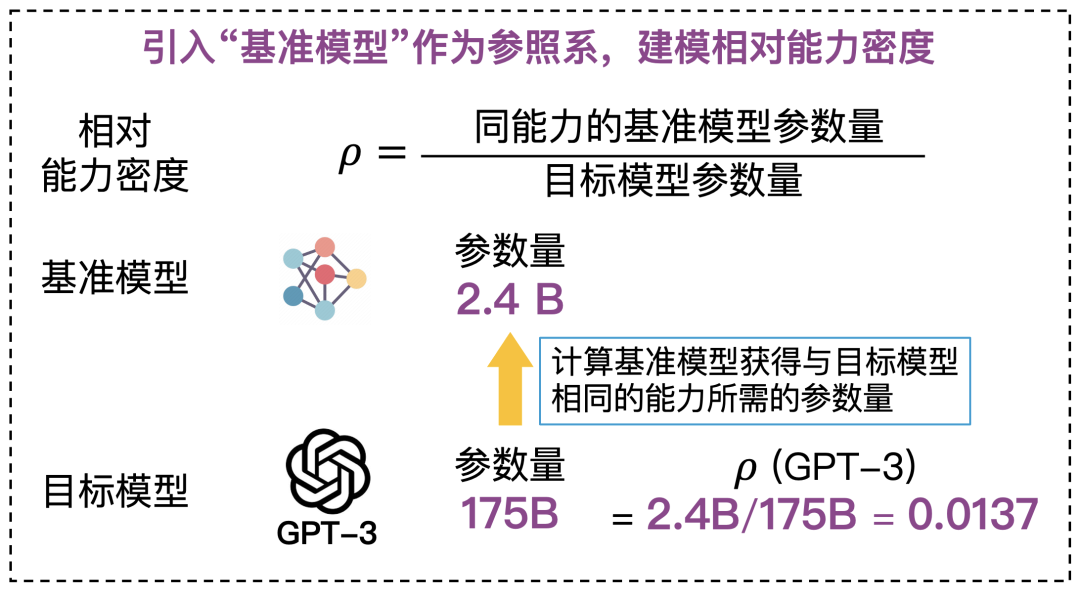
腾讯科技:您在2024年WAIC期间曾提到模型的“密度法则”周期是8个月,但最终论文的结果是3.5个月。为什么进化的速度比您预期的快这么多?

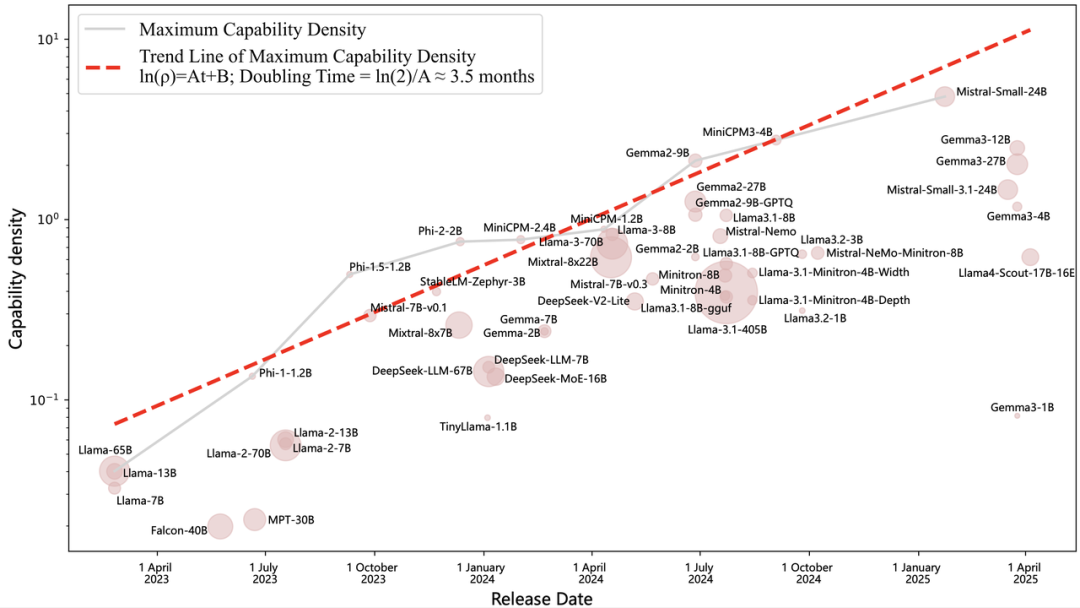
腾讯科技:刚才提到投入,大模型有暴力美学的 Scaling Law,您觉得 Densing Law 和 Scaling Law 是统一的还是矛盾的?

腾讯科技:“规模法则”似乎正面临数据、算力和能源的天花板。密度法则何时会遇到瓶颈?

腾讯科技:2025年有哪些让您觉得惊艳的技术突破,能让 Densing Law 更加陡峭?

腾讯科技:您觉得密度法则能推广到多模态模型或世界模型吗?

腾讯科技:您如何看待谷歌最新发布的Gemini 3?它是否可被称为里程碑式的突破?

腾讯科技: 现在还没有出现能替代智能手机的端侧 AI 设备,是不是因为 Densing Law 还没进化到位?
刘知远: 端侧设备的发展受限于多个因素。
第一,还没有形成好的端侧应用场景。现在的手机助手虽然用户多,但并未与硬件紧密结合。
第二,端侧技术生态尚未形成。AGI 发展还没收敛,模型能力还在持续提升,且在产品设计上还没法完全规避错误。就像早期的搜索引擎也是经过产品打磨才普及一样,AGI 结合智能终端也需要一个过程。一旦产品形态成熟,智能终端的广泛应用就会成为可能。
腾讯科技: 您提到 MiniCPM 4 可以看作一种“模型制程”,这个怎么理解?
刘知远: 我更愿意把这一代模型比作芯片制程。通过技术创新,我们形成了一套新的模型制程,无论构建什么尺寸的模型,其密度都更高。例如 MiniCPM 4 在处理长序列时速度提升了 5 倍,意味着可以用更少的计算量承载更强的能力。
但目前的挑战在于,硬件支持还不够好。我们正在努力做软硬协同优化,希望在消费级硬件上真正跑出理想状态。
腾讯科技: 这需要和高通、联发科等硬件厂商协同创新吗?
刘知远: 我们跟硬件厂商交流密切。但硬件厂商受摩尔定律 18 个月周期的影响,架构调整更审慎。而模型每 3 个月就进化一次。所以短期内是软件适配硬件,长期看硬件会针对稳定的新技术做优化。现在端侧芯片厂商已经在认真解决大模型运行的瓶颈,比如访存问题。
腾讯科技: 之前大家尝试过剪枝、量化等方法来做小模型,这和原生训练的高密度模型相比如何?
刘知远: 我们做过大量实验,剪枝、蒸馏、量化都会降低模型密度。量化通过后训练可以恢复一部分效果,是目前端侧比较落地的做法。但蒸馏现在已经融合进数据合成体系,不再是简单的“大蒸小”。剪枝目前还没找到保持密度的好方法。
就像你不能通过剪裁把 14nm 芯片变成 7nm 芯片一样,要把密度做高,必须从头构建一套复杂的原生技术体系,包括架构设计、数据治理、学习方法和软硬协同。这本身就是技术护城河。
腾讯科技:“密度法则”对产业界意味着什么?对于创业公司来说,机会在哪里?
刘知远:3.5个月的迭代周期意味着,任何一个投入巨资训练的大模型,如果不能在3到6个月内通过商业化收回成本,这种模式就很难持续。因为很快就会有技术更新的团队用更低的成本实现同样的能力。因此,云端API服务的竞争会极其惨烈,最终可能只会剩下几家拥有海量用户和强大技术迭代能力的头部厂商。
对于创业公司而言,机会可能在于“端侧智能”。端侧场景的约束条件非常明确(如功耗、算力、响应时间),这使得技术优势,即谁能把模型密度做得更高,成为唯一的竞争点,大厂的“钞能力”(如不计成本的投入)在这里难以发挥。虽然手机厂商也在高度关注,但它们的决策会更审慎。我们认为,端侧智能会先从智能座舱等对功耗不那么敏感的场景开始,而最终,AGI时代一定会有属于它自己的智能终端形态,这是我们希望探索的星辰大海。
腾讯科技: 面对算力军备竞赛和快速折旧,您怎么看泡沫论?
刘知远: 快速发展肯定伴随局部泡沫,但整体上我们正进入智能革命时代。
如果以 18 个月为周期,信息革命走了 50 个周期;如果 AI 也走 50 个周期,按现在的速度,大概到 2030-2035 年就能实现全球普惠的 AGI。
未来互联网的主体不再只是人,还有无数智能体。虽然训练模型的厂商会收敛,但推理算力需求会爆炸式增长。
腾讯科技: 李飞飞(美国国家工程院院士)说 AI 是文明级技术,您对这场帮命乐观吗?
刘知远: 我相当乐观。
腾讯科技:如果AI变得无比强大,未来人类会不会无事可做?
刘知远:我不这样认为。未来一定是人机协同,人是把关人。
人类知识大爆炸导致我们只能成为细分专家,阻碍了跨领域创新。人工智能可以帮助我们成为知识的主人而不是奴隶,去探索宇宙、生命等更多未解之谜。
腾讯科技: 您2026年最期待的创新是什么?
刘知远: 我最期待“用 AI 制造 AI”。
明年一个重要节点是自主学习(Self-play)。目前的强化学习还依赖人类给标准答案,未来模型如果能自主判断探索结果的价值,就实现了自主学习。
在此基础上,结合密度法则的提升,我们有可能为每个人构建专属的、持续学习的个人大模型。
未来的生产标志就是“用 AI 制造 AI”。不再依赖有限的人力,而是由 AI 来赋能 AI 的研发和制造。这将是一个指数级加速的过程。