谁敢说谷歌掉队,它打了一场漂亮的翻身仗
2025-12-24 04:25:24 · chineseheadlinenews.com · 来源: 新浪网
在即将过去的 2025 年,谷歌在人工智能领域交出了一份颇具分量的成绩单。
曾因“发表了 Transformer 却痛失先机”而备受外界质疑,谷歌一度深陷“大模型掉队”的舆论漩涡。但这一年,谷歌用一系列里程碑式的发布打了一场漂亮的翻身仗。它向世界证明,AI 不再只是陪聊的机器人,而是变成了能写代码、能做科研、甚至攻克前沿科学难题的“合作伙伴”。
看看 Demis Hassabis 晒出的这张年度成绩单,Gemini 3、Genie 3、Veo 3、Nano Banana... 确实硕果累累。
同时,谷歌官方博客发布年终研究进展总结报告,详细盘点了谷歌 2025 年的研究突破,作者包括 Jeff Dean、Demis Hassabis、James Manyika。
博客地址:https://blog.google/technology/ai/2025-research-breakthroughs/#ai-models
在深入细节之前,我们先快速梳理谷歌本年度的几大“杀手锏”。
模型侧: Gemini 3 强势登顶,逻辑推理与数学能力刷新纪录,Flash 版本性价比超越前代 Pro。
硬件侧: 第七代 TPU Ironwood 算力暴涨,剑指英伟达;量子计算实现“量子回声”突破。
应用侧: AI 不再只是 Chatbot,通过 Antigravity 重塑编程,通过 Veo 3 和 Genie 3 彻底改变视频生成与世界模拟。
科学侧: AlphaFold 五周年里程碑与诺贝尔化学奖的双重加冕,奠定了 AI for Science 的领先地位。Gemini Deep Think 也在数学奥赛(IMO)与编程竞赛(ICPC)中双双达到金牌水平,标志着 AI 抽象推理能力的质变。
以下是我们基于官方博文整理的详细技术盘点:
AI 模型:谷歌训出了奥特曼理想中的 GPT-5
今年 3 月,Gemini 2.5 的发布为全年的技术路线奠定了基础。而 11 月正式面世的 Gemini 3,则被视为谷歌目前的巅峰之作。谷歌在模型推理、多模态理解以及运行效率等方面实现了多次实质性跨越。
作为谷歌目前性能最强的模型,Gemini 3 Pro 在逻辑推理领域表现尤为突出。它不仅迅速登顶 LMArena 排行榜,更在 Humanity’s Last Exam(旨在考察 AI 是否具备人类水平思考能力的严苛测试)中取得突破性成绩。在数学领域,它以 23.4% 的准确率刷新了 MathArena Apex 的纪录。
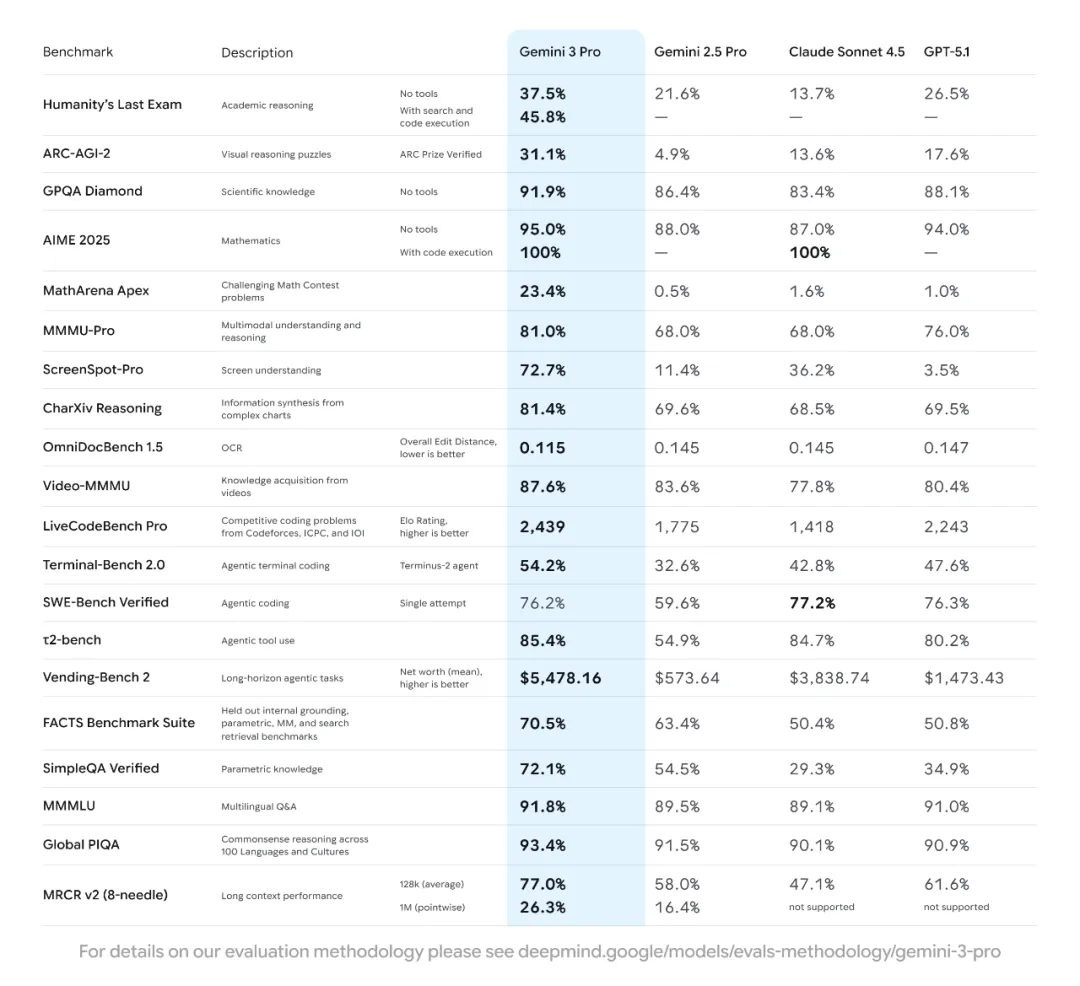
Gemini 3 在多项关键 AI 基准测试中处于最先进水平。
相关链接:https://blog.google/products/gemini/gemini-3/
紧随其后的 12 月,谷歌推出了针对开发者和企业级市场的 Gemini 3 Flash。这款模型延续了谷歌“后浪推前浪”的策略,即:下一代的 Flash 模型在性能上力求超越上一代的 Pro 模型。
数据显示,Gemini 3 Flash 的综合质量已经超越了今年 3 月发布的 Gemini 2.5 Pro,但其成本大幅降低,延迟表现也得到了显著优化。这种“高性价比”的策略,旨在让更复杂的推理任务能够以更快的速度和更低的门槛进入实际应用场景。
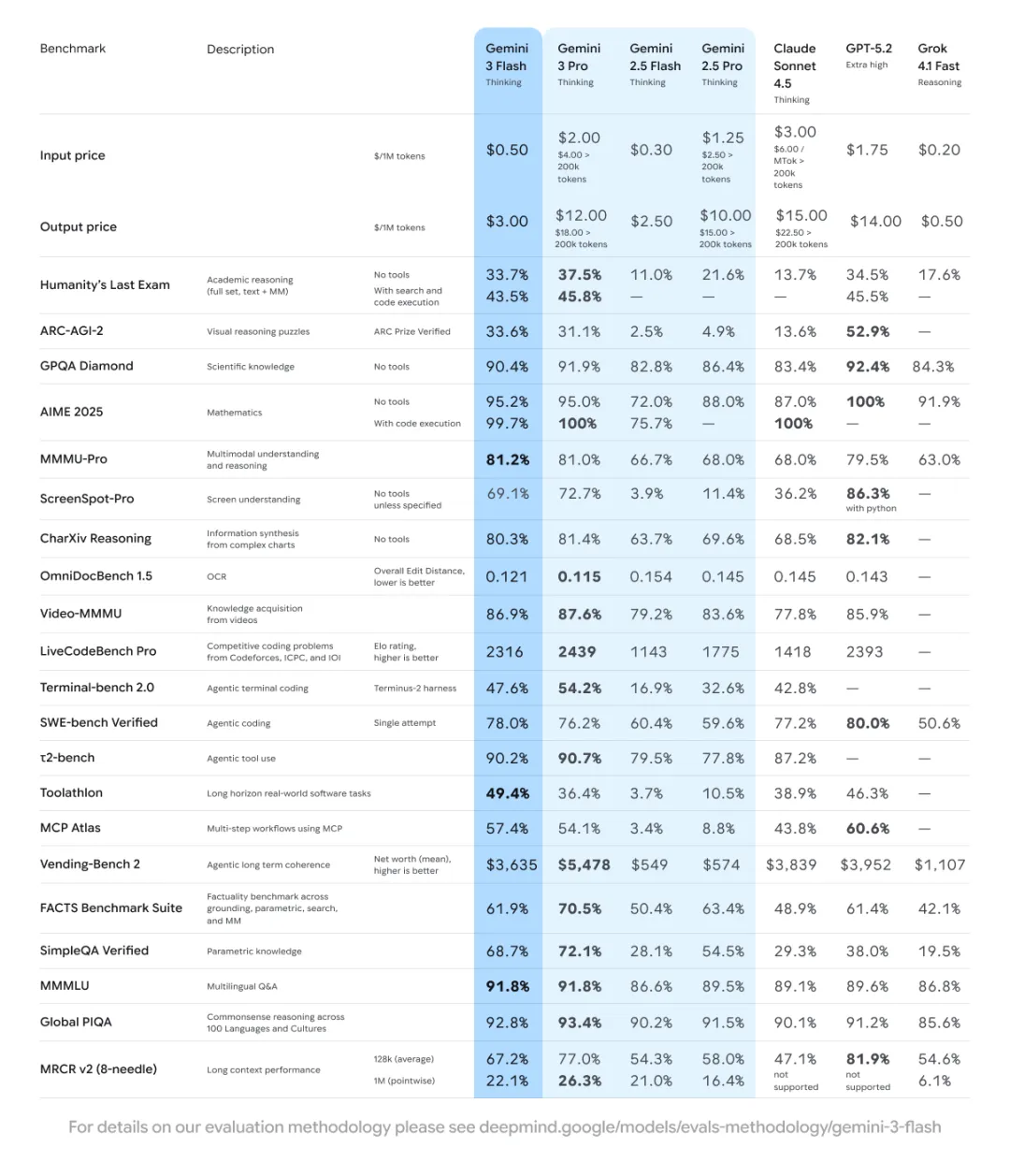
Gemini 3 Flash 价格及基准表。
相关链接:https://blog.google/products/gemini/gemini-3-flash/
除了闭源的 Gemini 系列,谷歌在开源领域也动作频频。Gemma 家族在今年实现了从纯文本到多模态的转型。
通过增加上下文窗口、扩展多语言支持以及优化在单张 GPU/TPU 上的运行效率,Gemma 3 现已成为开发者在本地部署高性能 AI 时的首选堡具之一。特别是 8 月发布的 Gemma 3 270M,以其极小的参数规模提供了超高效率,标志着谷歌在边缘侧 AI 领域的技术沉淀。
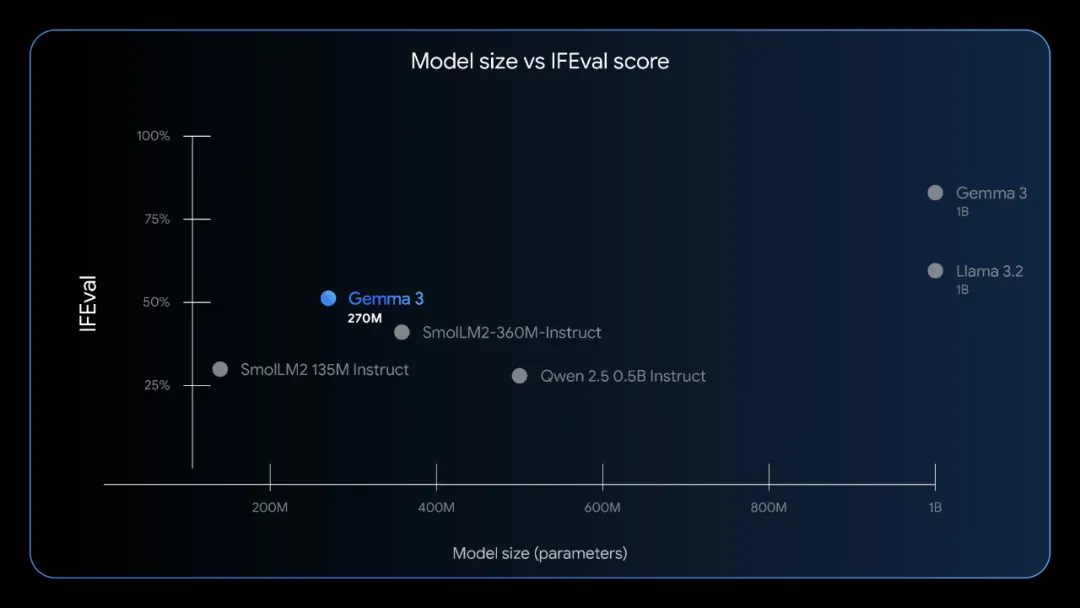
相关链接:https://developers.googleblog.com/en/introducing-gemma-3-270m/
产品重构:AI 不再是工具
而是你的“合作伙伴”
2025 年是 AI 从“单一工具”向“核心效能”跨越的一年。Google 通过在全线产品中注入强大的 Agentic 能力,推动 AI 从辅助角色转变为实用型基础设施,重新定义了人机协作的形态。
在软件开发领域,Google 不再局限于提供辅助编码工具,而是致力于构建能与开发者深度协作的智能体系统。11 月发布的 Gemini 3 展现了令人印象深刻的代码生成与逻辑理解能力。同期推出的 Google Antigravity 更是标志着 AI 辅助开发进入了一个新纪元 —— 它将开发流程从传统的“工具辅助”升级为“智能体协作”,极大地释放了开发者的创造力与生产力。

相关链接:https://antigravity.google/blog/introducing-google-antigravity
这种进化同样清晰地体现在 Google 的核心产品矩阵中,贯穿了从硬件终端到信息检索的每一个环节:
3 月,Search 迎来了重要变革,通过扩展 AI Overviews 并引入全新的 AI Mode,重塑了用户获取与处理信息的方式。
8 月,备受瞩目的 Pixel 10 正式亮相。得益于一系列 AI 原生功能的深度整合,它被评价为 Google 迄今为止最智能、最实用的手机终端。
而在生产力与知识管理领域,年底的一系列更新将体验推向了新高度。随着 11 月 Gemini 3 的底层赋能,Gemini App 迎来了智商与能力的双重飞跃。与此同时,NotebookLM 也在同月重磅加入了 Deep Research 功能并支持了更多类型的数据源,使其从单纯的笔记工具进化为能够处理复杂信息流的专业级智能研究助手。

相关链接:https://blog.google/technology/google-labs/notebooklm-deep-research-file-types/
创意生成:终结“默片时代”
好莱坞要慌了
2025 年是生成式媒体发生变革的一年。Google 通过发布一系列突破性的模型和工具,涵盖视频、图像、音频及虚拟世界构建,赋予了创作者前所未有的能力。
在视频生成领域,5 月发布的 Veo 3 首次实现了原生音频生成,结合同期升级的 Music AI Sandbox,无论是脚步声、环境风声还是背景配乐,都能与画面动作完美同步,彻底终结了 AI 视频的“默片时代”。
10 月的更新则进一步推高了行业天花板。Veo 3.1 版本不仅大幅提升了光影变化与物体碰撞的物理一致性,还与全新创意工具 Flow 深度整合。更重要的是,它强化了“首尾帧控制”功能,允许创作者精准指定视频的起点与终点,由 AI 补全中间过程,极大地增强了叙事的可控性。

相关链接:https://developers.googleblog.com/introducing-veo-3-1-and-new-creative-capabilities-in-the-gemini-api/
在图像生成领域,随着 5 月 Imagen 4 的奠基,Nano Banana 在今年大放异彩,其在匿名测试时就因表现优异而备受关注。8 月,作为图像生成的重大升级,Nano Banana 以极高的指令遵循能力著称。它解决了“文字生成图片”中细节丢失的问题。
而 11 月发布的 Nano Banana Pro 则将体验推向了新高度。作为系列的旗舰版本,它首次引入了“深度思考”模式,在绘图前先进行逻辑推理。这使得它不仅能精准还原极其复杂的 Prompt 构图,更实现了高保真的文字渲染能力,无论是海报设计还是图表绘制都达到了专业级水准。

“柏林”一词融入了城市街区的建筑设计中,横跨多栋建筑。
相关链接:https://blog.google/technology/ai/nano-banana-pro/
此外,Google Labs 在今年也涌现出众多突破性实验:从将设计瞬间转化为代码的 Stitch,到开发者的异步协作伙伴 Jules,再到 3D 视频通信平台 Google Beam,AI 正在从单纯的媒体生成工具,进化为重塑工作流的生产力核心。
从蛋白质到奥数金牌
AI 当起“全能科研队友”
2025 年,谷歌在生命科学、医疗健康及数学逻辑等领域取得了里程碑式突破,不仅深化了人类对生物遗传的理解,更在顶级智力竞赛中证明了 AI 具备与人类顶尖水平相当的抽象推理能力。
首先来看生命科学领域。上个月,AlphaFold 迎来五周年纪念。在解决蛋白质结构预测难题五年后,该系统已为超过 2 亿个蛋白质预测了结构,并助力全球 300 多万名研究人员加速科研。这一成就通过开放数据库彻底改变了结构生物学,并因其对生命科学的深远贡献荣获了 2024 年诺贝尔化学奖。
此外,谷歌还发布了基因组理解模型 AlphaGenome,这是一个能够同时处理多达 1 兆碱基对的高分辨率 DNA 序列模型。它通过统一分析多种生物调控模式,帮助科学家解读 DNA 中曾经难以捉摸的非编码区域,为探寻遗传病因和开发新型疗法提供了全方位的生物集成开发环境。
再来看医疗健康领域。谷歌研究院推出的 DeepSomatic 利用卷积神经网络,在肿瘤序列中以极高精度识别癌症相关的遗传变异。该工具能够处理来自主流测序平台的数据,帮助临床医生更准确地锁定驱动癌症的特定变异,从而实现真正的精准医疗和个性化治疗。
而在科学发现方面,谷歌发布了一款基于大模型的编程智能体 ——AlphaEvolve,专门用于寻找和验证理论计算机科学中的复杂组合结构。它在验证过程上实现了 1 万倍的加速,成功协助科研人员收紧了优化问题的界限,标志着 AI 正从数据处理者转型为深度参与数学发现的科研合作者。
此外,谷歌还推出了基于 Gemini 2.0 构建的多智能体协作系统 ——AI co-scientist,旨在模仿科学研究的逻辑流程。它能独立生成研究假设、设计实验方案并撰写研究提案,在生物医学等领域展现了显著缩短发现周期的潜力,成为了科学家的虚拟实验室助手。
在代码、数学逻辑方面,谷歌也站稳了第一梯队。进阶版 Gemini 2.5 Deep Think 在 2025 年国际大学生程序设计竞赛(ICPC)总决赛中达到金牌水平,在 12 道题目中解出了 10 道。第 66 届国际数学奥林匹克(IMO)中,Gemini Deep Think 凭借 35 分的高分(总分 42 分)达到金牌表现,完美解决了 6 道难题中的 5 道。
算力宇宙:量子回声算法登 Nature
新一代 TPU 叫板英伟达
前段时间,谷歌创始人谢尔盖?布林在参加母校的一次活动时表示,这些年,谷歌有很多失误,比如没有第一时间重视 Transformer。但他们也做对了很多事情,比如对“计算”的投入。
首先,在量子计算方面,他们的重大突破 ——Quantum Echoes(量子回声)算法在 10 月份登上了“Nature”。它在量子处理器上实现了首次可验证的量子优越性,能以比最快超级计算机快 13,000 倍的速度解决特定问题,为药物研发、材料科学等领域的实际应用打开了新窗口。
相关链接:https://quantumai.google/static/site-assets/downloads/quantum-computation-molecular-geometry-via-nuclear-spin-echoes.pdf
这一进展得益于谷歌在量子计算方向的多年投入。今年,谷歌量子硬件首席科学家 Michel Devoret 和前量子人工智能硬件负责人 John Martinis 还因在量子计算方面的奠基性工作与加州大学伯克利分校教授 John Clarke 共同获得了诺贝尔物理学奖。至此,谷歌的诺奖得主已经增加到五位,在科技界非常罕见。
除了量子计算,谷歌今年在 TPU 方向的进展同样令人瞩目。今年 4 月,第七代 TPU——Ironwood 正式发布。它专为“推理时代”设计,每块芯片内存带宽提升至 7.2 TB/s,单芯片显存容量达到 192GB。当每个 pod 扩展至 9216 块芯片时,它可提供 42.5 exaflops 的 AI 算力,远超目前全球最快的超级计算机 El Capitan 的 1.7 exaflops。每块 Ironwood 芯片的峰值计算能力可达 4614 TFLOPs。
谷歌透露,这款芯片的部分架构由其自家的 AI 模型 AlphaChip 辅助优化,大幅缩短了研发周期并优化了布局。
和英伟达 GPU 相比,这款新的 TPU 拥有极致的能效比,在电力供应受限的数据中心里,谷歌能用同样的电量跑出更多的 AI 算力。此外,谷歌不把 TPU 看作单一芯片,而是一个名为 Pod 的整体,在超大规模集群(万卡级别)的布线复杂度和电力损耗上,TPU 更有优势。(关于 GPU 和 TPU 的更多对比参见《谷歌 TPU 杀疯了,产能暴涨 120%、性能 4 倍吊打,英伟达还坐得稳吗?》)
目前,谷歌已计划到 2027 年实现年产 500 万颗 TPU 的目标。目前,像 Anthropic 这样的 AI 巨头已经预订了超过 100 万颗 TPU 算力,这显示出谷歌正通过“自研芯片 + 云服务”的闭环,在 AI 硬件市场有力地挑战英伟达的统治地位。
Gemini Robotics
把“大模型 + 机器人”做到极致
在这波具身智能发展浪潮中,谷歌一直起到技术引领作用,通过一系列研究把“大模型 + 机器人”这件事做成了体系化、可迭代、且不断刷新行业上限。
前两年,他们通过 RT-1 和 RT-2 (Robotic Transformer) 率先证明了:大语言模型(LLM)的 Transformer 架构可以直接用于输出机器人动作。
2025 年,他们进一步将 VLA 模型推向极致。3 月份,他们推出了 Gemini Robotics,通过将视觉、语言和动作三种模态与物理控制系统深度融合,首次实现了“感知 - 决策 - 动作”的全闭环操作,能够直接根据视觉输入和语言指令生成相应的机械臂轨迹,无需像传统机器人那样进行繁琐的分步规划。
9 月份,Gemini Robotics 1.5 问世,初步具备了以类似人类思考方式进行规划行动的能力。它通过两个模型的合作来达成此目标:ER 模型负责高层推理和决策,生成详细的行动方案;VLA 模型负责感知和具体执行,并在执行过程中进行细粒度的自我推理校正。这种架构旨在结合两者优势,使机器人既能深思熟虑又能动作精准。

此外,他们还成功把大模型“塞进”边缘设备并开放生态。2025 年 6 月发布的 Gemini Robotics On-Device,首次让低延迟的 VLA 模型完全离线运行在机械臂和人形机器人上。他们还配套放出了 Gemini Robotics SDK,开发者 50~100 次演示就能微调出可迁移的新技能。
Genie 3 引爆世界模型
哈萨比斯寄予厚望
提到世界模型,谷歌的 Genie 3 是今年的绝对亮点,被视为世界模型的新高峰(参见《震撼,世界模型第一次超真实地模拟了真实世界:谷歌 Genie 3 昨晚抢了 OpenAI 风头》。
这不只是因为 Genie 3 画面更逼真,而是它第一次把实时交互、长期一致性和语言可控性合成在同一个生成式系统中:它以每秒 24 帧、720p 的边生成边交互方式,让用户无需任何预制 3D 资产就能像玩游戏一样实时探索,而且它具备长达几分钟的空间记忆,使世界在转身离开后依然保持稳定连续。

正因如此,Genie 3 不再只是“可看的视频模型”,而有望成为一个能支撑智能体长期试错与规划的训练环境、一个把内容创作从搭场景降维到写一句话的生产工具,以及一个可低成本复现极端情境的科学模拟沙盒,为通往通用智能提供了一条可交互、可长期演化的模拟路径。
最近,哈萨比斯在采访中说,除了 AI 之外,世界模型和模拟可能是他最长久的热情所在。他认为,语言模型已经意外地学会了大量关于世界的知识,但真正的世界理解 —— 尤其是空间动态、物理因果和需要亲身体验的感知能力 —— 很难仅靠语言获得,必须通过世界模型与模拟来补足。
世界模型本质上是一种“直觉物理学”,能理解事物如何运作、移动与相互作用,而生成逼真的世界正是这种理解的证明。像 Genie、Veo 这样的交互式视频与世界模型,是迈向通用智能、机器人和现实中通用助手的关键一步,最终也可能回到他最初热爱的游戏与模拟,创造真正意义上的“终极游戏”。
挑战天气、疾病、教育
谷歌要改造世界
技术终究是为人服务的,在这方面,谷歌也披露了一些进展。
气候方面,他们的洪水预警系统已经覆盖 150 个国家、20 多亿人口了。他们新出的天气预报模型 WeatherNext 2,速度是以前的 8 倍,最精细能做到按小时预测。

项目链接:https://deepmind.google/science/weathernext/
医疗方面,他们在通用模型的基础上打造了一些垂类模型,比如基于 Gemma 开源模型系列的、用于单细胞分析的 270 亿参数基础模型 Cell2Sentence-Scale 27B(C2S-Scale),该模型可以帮助发现新的潜在癌症治疗途径。

项目链接:https://blog.google/technology/ai/google-gemma-ai-cancer-therapy-discovery/
教育方面,谷歌也尝试了一些创新,包括:
在 Gemini AI 里推出了“Guided Learning”功能,它不像普通 AI 只给出答案,而是通过提问、步骤讲解、图片、视频和测验等方式,帮助用户深入理解知识。
基于 Gemini 打造了一系列经过微调、融入学习科学原理的生成式 AI 模型 ——LearnLM。它在设计时参考了教育研究(如认知负荷管理、个性化反馈等),目的是让 AI 更像导师而不是只给答案。
把强大的 Gemini 翻译能力带到了谷歌翻译和 Search 的翻译功能中,让文本翻译更自然、更能理解语境(比如习语、俚语等),提高准确性,同时推出了基于 Gemini 的实时语音对话翻译(Live translate),可通过耳机听见更加自然流畅的即时翻译。
结语
纵观 2025 年,谷歌展现出的并非单一技术的突进,而是一种强大的“系统性工程能力”。在算力层有 TPU 集群与量子回声算法,在模型层有 Gemini 的逻辑进化,在应用层有诺奖级的科研产出。
这一年,谷歌显然走出了“创新者的窘境”,不再纠结于先发优势的丧失,而是利用其庞大的全栈生态完成了补课与追赶。在 AI 竞争从“在大模型上跑分”转向“在产业链中落地”的下半场,这种从底层芯片到上层应用没有任何短板的布局,或许才是科技巨头最核心的竞争力。