Agent AI:多模态交互的新地平线
2025-05-24 11:25:10 · chineseheadlinenews.com · 来源: 集智俱乐部
多模态人工智能系统极有可能成为我们日常生活中无处不在的存在。使这类系统具备更强交互性的一个前景广阔的思路,是将它们以智能体(agent)的形式嵌入物理或虚拟环境。目前,各种系统通常都以已有的大型基础模型为构建智能体的基石。将智能体置于此类环境中,能够使模型处理并理解视觉与上下文信息,这对于构建更为复杂、具有情境感知能力的人工智能系统至关重要。比如,一个能够感知用户动作、人类行为、环境中的物体、声音表达乃至场景整体情绪的系统,就能据此在所处环境中引导并调整智能体的行为回应。为了加速基于智能体的多模态智能研究,我们将“Agent AI”定义为一类交互式系统,它们不仅能感知视觉刺激、语言输入及其他植根于环境的数据,而且能够产生具有意义的、具身化的动作。我们尤其关注通过融合外部知识、多感官输入和人类反馈来改进智能体的下一步具身动作预测的系统。我们认为,在具体环境中开发具备能动性的人工智能系统,还可以有效缓解大型基础模型产生的“幻觉”问题及其生成与环境不符的输出倾向。新兴的“Agent AI”领域涵盖了更广泛的多模态交互中的具身化与能动化方面。除了在物理世界中行动与交互的智能体之外,我们还设想,在未来,人们可以轻松地创建任意虚拟现实或模拟场景,并与嵌入其中的虚拟环境智能体进行交互。

关键词:Agent AI(智能体人工智能)、多模态交互(Multimodal Interaction)、大型基础模型(Large Foundation Models)、具身智能(Embodied AI)、游戏AI(Gaming AI)、机器人学(Robotics)、医疗健康(Healthcare)、伦理考量(Ethical Considerations)
推荐语
2025年,人工智能技术迎来爆发式发展,技术迭代的加速将重塑行业生态,形成倒“T”字型格局:少数专注于通用人工智能(AGI)的巨头企业将进一步垄断核心资源与市场机会,而大量中小鲍司则更应该聚焦于人机交互新模式的探索。这一趋势的底层逻辑在于,大模型与AI Agent的广泛应用不仅重构了人机协作方式,更开辟了全新的流量入口。想象一下,如今的人机界面大大地受限于鼠标和键盘,而语音、手势和自然语言交流则大大解放人机互动带宽。在此背景下,多模态人机交互将成为最具潜力的创新方向之一,为行业带来无限想象空间!——张江

论文题目:Agent AI: Surveying the horizons of multimodal interaction
论文链接:https://arxiv.org/abs/2401.03568
发表时间:2024年1月25日
人工智能领域正迎来一场范式变革——从静态任务处理转向动态的、具身化的智能体(Agent)系统。近日,来自斯坦福大学、微软研究院等机构的联合团队发表综述论文预印本,系统阐述了以大语言模型(LLMs)和视觉语言模型(VLMs)为核心的智能体技术如何通过多模态交互实现跨领域、跨现实的通用人工智能(AGI)路径。这项研究不仅梳理了Agent AI的技术框架与应用场景,更揭示了其在游戏、机器人、医疗等领域的颠覆性潜力,同时直面伦理与社会影响等关键问题。
从模块化到整体性:Agent AI的范式革新
传统AI系统往往将感知、规划、行动等模块割裂开发,而Agent AI的核心理念是回归亚里士多德的“整体论”(Holism),通过整合语言理解、视觉认知、环境记忆与推理能力,构建具有自主行动能力的统一智能体。研究团队提出,以GPT-4、DALL-E等大型基础模型为基石,结合强化学习(RL)、模仿学习(IL)等策略,可训练出能同时处理文本、图像、动作信号的“智能体变换器”(Agent Transformer)。
如下图所示,这种新型架构包含五大模块:环境感知与任务规划、智能体学习、记忆系统、行动预测和认知推理,其创新之处在于引入专属的“智能体令牌”(Agent Tokens)来表征特定领域的动作空间,相比传统冻结参数的多模态模型(如Flamingo、BLIP-2),这种端到端训练范式在机器人控制等任务中展现出更强的适应性。
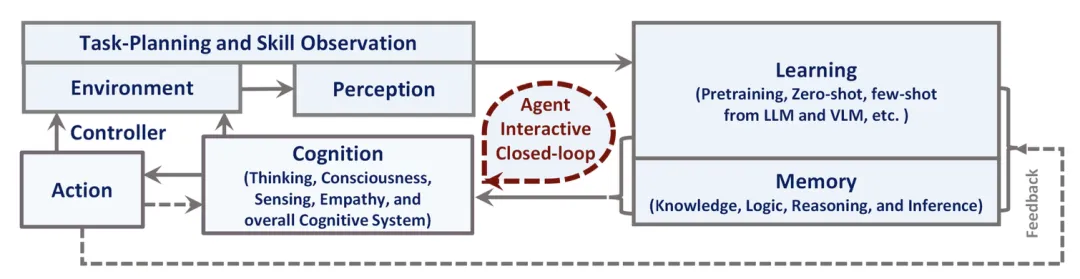
图 1. 我们为多模态通用智能体提出的新智能体范式。如图所示,主要有 5 个模块:1)环境与感知,包括任务规划和技能观察;2)智能体学习;3)记忆;4)智能体行动;5)认知。
破解幻觉难题:知识增强的交互机制
当Agent AI应用于现实场景时,模型“幻觉”(Hallucination)成为重大挑战——即生成与事实矛盾或无关的内容。文章区分了内在幻觉(与输入矛盾)和外在幻觉(添加无关信息)两种类型,并提出“混合现实知识推理交互”(Mixed Reality with Knowledge Inference Interaction)的涌现机制。通过从网络源显式检索知识,并结合预训练模型的隐式推理,智能体能够在虚拟与现实场景中实现知识迁移。
从游戏NPC到手术助手:跨领域应用图谱
在游戏领域,Agent AI正重塑非玩家角色(NPC)的行为逻辑。传统脚本驱动的NPC行为呆板,而基于LLM的智能体(如《外交》游戏中的AI)已能通过人类对话数据训练实现战略决策。研究团队开发的“MindAgent”框架在《CuisineWorld》多智能体协作游戏中,通过GPT-4中央调度器协调多个智能体完成烹饪任务,其协作效率评分(CoS)验证了语言模型在复杂策略规划中的潜力。
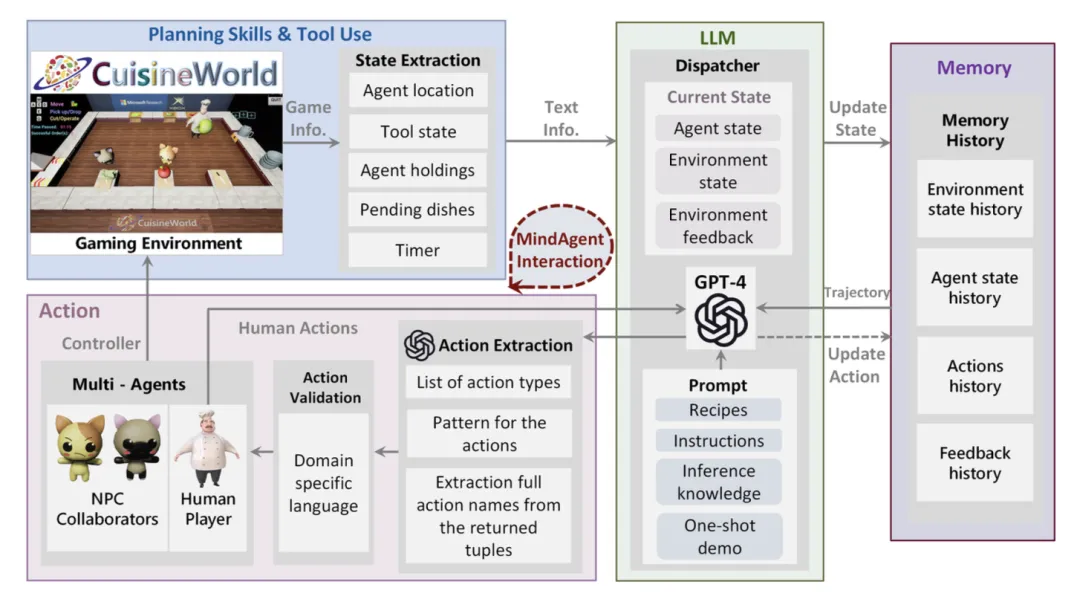
图 2. 情境学习游戏结构中的思维智能体。规划技能与工具使用:游戏环境需要多样化的规划技能和工具使用来完成任务。它生成相关游戏信息,并将游戏数据转换为 LLM 能够处理的结构化文本格式。LLM:作为基础架构的核心,负责决策,从而充当多智能体系统的调度员。记忆历史:用于存储相关信息的工具。行动模块:从文本输入中提取行动,并将其转换为特定领域的语言,同时验证特定领域的语言(DSL),以确保在执行过程中不会出现错误。
机器人领域则面临视觉运动控制(Visual Motor Control)与语言条件操作(Language Conditioned Manipulation)的双重挑战。如图3所示,结合ChatGPT的任务规划器与视觉示范系统,机器人能理解“将桌上的派加热”这类指令,并自主分解为取物、移动、使用烤箱等子任务。特别值得注意的是GPT-4V在多模态任务规划中的表现,它能从演示视频中提取物体空间关系(如“冰箱把手可抓握”),并生成可执行的技能序列。
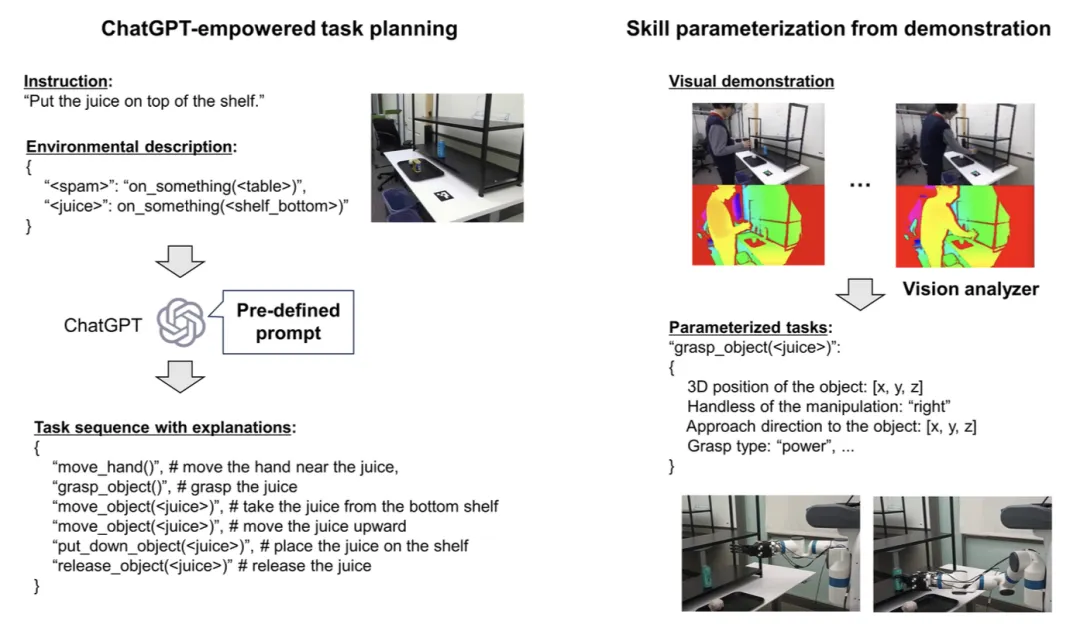
图 3. 集成 ChatGPT 强化任务规划器的机器人教学系统概述。该过程包含两个步骤:任务规划,用户使用任务规划器创建动作序列,并根据需要通过反馈调整结果;演示,用户通过视觉展示动作序列,为机器人操作提供所需信息。视觉系统收集用于机器人执行的视觉参数。
医疗健康应用凸显了技术红利与风险并存。虽然GPT-4V能准确识别CT扫描图像中的操作场景,但对超声视频的分析仍受安全限制约束。团队强调,诊断智能体必须与知识检索智能体配合,通过实时验证避免错误诊断,例如在皮肤病灶分类任务中,直接调用ISIC皮肤病变数据库比对可减少67%的误判。

图 4. 在医疗保健图像理解领域使用GPT-4V时的示例提示和响应。从左到右:(1)护士和医生进行CT扫描的图像,(2)不规则心电图扫描的合成图像,(3)来自ISIC (Codella et al., 2018)皮肤病变数据集的图像。我们可以看到GPT-4V拥有大量的医学知识,能够对医学图像进行推理。然而,由于安全训练,它无法对一些医学图像进行诊断。
数据与伦理:智能体社会的双刃剑
论文还深入探讨了Agent AI的伦理框架,训练数据偏差(如过度代表西方社会文化)、历史文本中的歧视性语言、隐私保护等问题亟待解决。团队提出的“包容性设计”(Inclusive Design)包含九大原则:从多样化训练数据、文化敏感性到无障碍交互设计。在医疗等高风险领域,采用“红队测试”(Red-teaming)使用一个专门的对手团队开展对抗性工作,主动暴露系统弱点,并建立人工审核闭环。值得关注的是,研究团队特别指出当前智能体在情感推理(Emotional Reasoning)上的不足,开发的NICE数据集通过200万张图像的情感标注,训练出能生成共情评论的MAGIC模型,但跨文化情感理解仍是难点。
未来挑战:从模拟到现实的最后一公里
尽管Agent AI在模拟环境(如Habitat、VirtualHome)中表现优异,但“模拟到现实迁移”(Sim-to-Real Transfer)仍是瓶颈。团队对比了三种解决方案:通过域随机化(Domain Randomization)增加训练多样性、利用CycleGAN进行跨域图像转换,以及开发光真实模拟器。在机器人抓取任务中,结合物理引擎的Neural Radiance Fields技术将操作成功率提高了40%,但动态环境下的长期规划仍需要突破。研究者呼吁更多人参与,共同攻克多模态具身智能的终极难题——如何让机器像人类一样,通过持续的环境交互实现自我进化(Self-improvement)。