何恺明组新作:258M参数就够了
2026-06-19 11:25:21 · chineseheadlinenews.com · 来源: 量子位
全员本科生!
刚刚,何恺明携本科生 “军团” 又放出一篇新论文。继去年探索直接从像素预测图像的 JiT 架构后,团队这次又把这套 “删繁就简” 的思路扩展到了文生图领域,推出全新工作:MiniT2I。
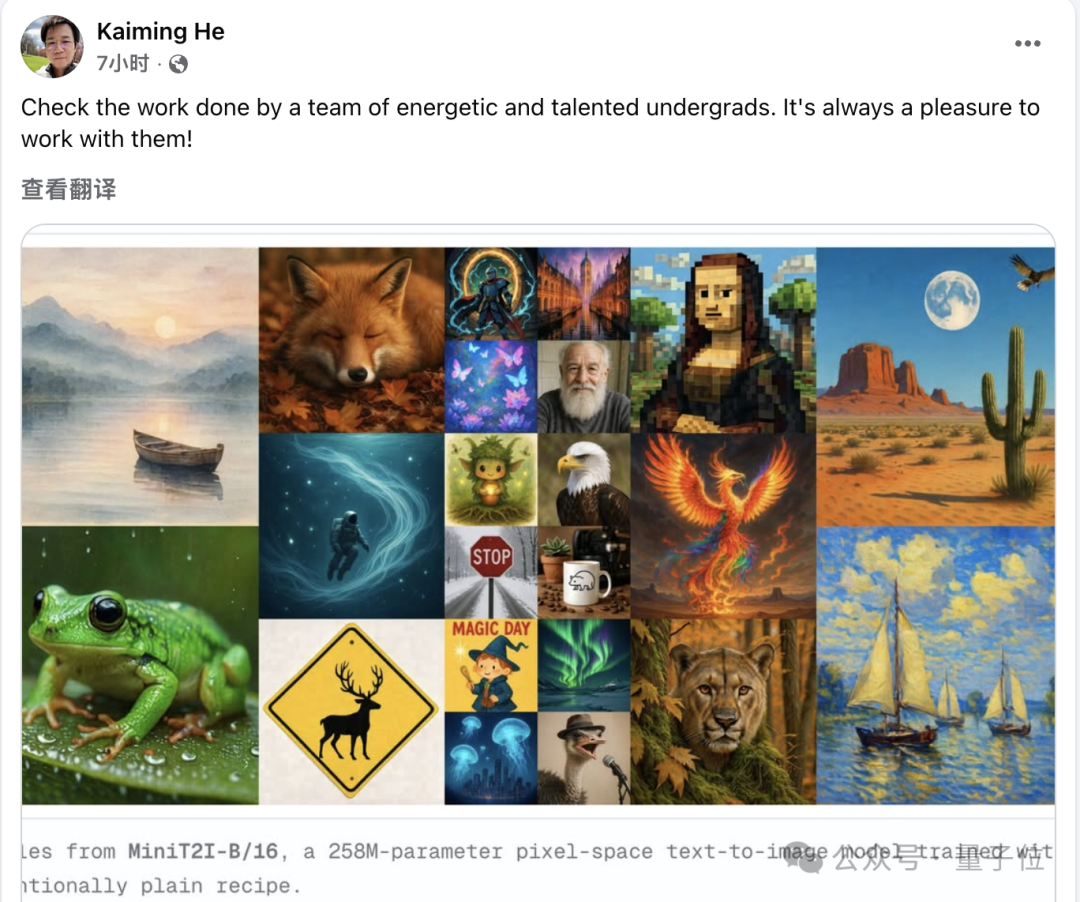
在今天动辄数十亿参数、海量图文数据训练文生图模型的背景下,MiniT2I 选择了另一条路。它基于全新的 MM-JiT 架构,直接在像素空间进行扩散生成,同时尽可能压缩模型复杂度和训练成本,最终,仅用 258M 参数,就实现了不错的文生图效果,更关键的是,整个训练成本只相当于一次标准 ImageNet 实验。
这是怎么做到的?
从 JiT 到 MM-JiT
整体看来,MM-JiT 是恺明组之前论文“Back to Basics”在 T2I(文本生成图像)方向上的延伸。

Back to Basics 中,恺明和他的博后黎天鸿提出了 JiT 架构,Just image Transformers。JiT 的核心主张是:抛开 VAE 编解码器,直接在像素空间预测干净图像(x-prediction),而不是像传统扩散模型那样预测噪声。这样做的好处是,整个生成流程更加直接,符合流形假设以及 “从像素出发” 的第一性原理。
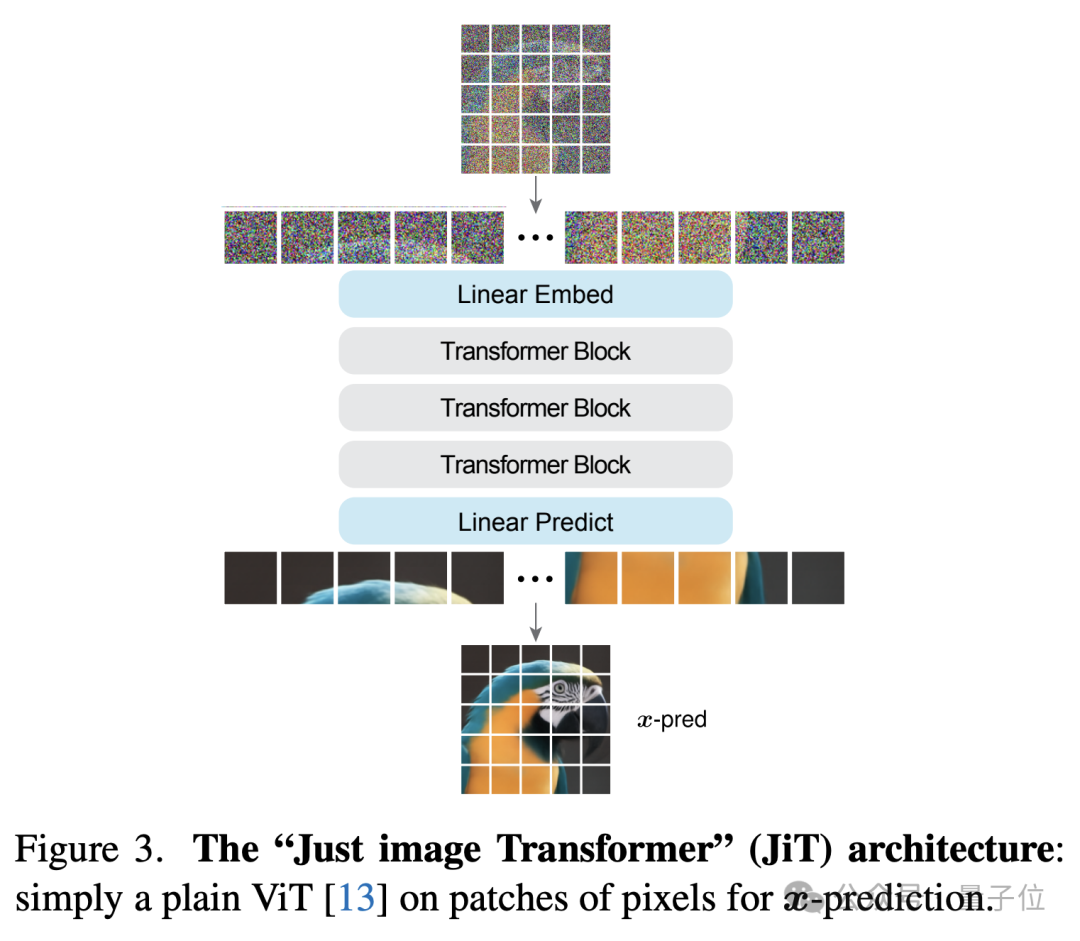
不过,当时的 JiT 主要针对类别条件生成(class-conditional generation),任务范围相对有限,模型只能根据 ImageNet 的类别标签生成对应图像。然而,真实的图像生成任务往往不限于 ImageNet 的 1000 个固定类别,而是需要理解并遵循开放的文本 Prompt。

问题也随之而来,一旦从类别生成扩展到文生图,训练成本往往会迅速攀升。无论是 SD3、FLUX.1-dev 还是 DALL?E 3,背后都依赖多阶段训练流程、庞大的文本编码器以及海量数据资源。对于大多数学术团队而言,从零开始训练一个完整的文生图模型,几乎是一项难以承担的工程,于是,MiniT2I 应运而生。

它试图回答一个更现实的问题:如果只用接近 ImageNet 训练规模的计算资源,能不能也做出效果不错的文生图模型?答案是,可以。
研究发现,当文本首先被预训练语言模型编码为语义表示后,对于生成模型而言,文本条件本质上只是另一种形式的上下文条件。换句话说,文生图或许并没有想象中那么特殊,在模型架构、训练计算量,甚至所需数据规模上,它与类别条件生成的差距远没有业界普遍认为的那么大。
如果这个判断成立,那么一个很自然的问题就出现了:既然类别条件生成已经能用 JiT 这样的极简架构完成,那么文生图任务里那些复杂的模块,究竟哪些是真正必要的?MM-JiT 给出的答案是:把它们一个个删掉,再看模型还能不能工作。
MM-JiT:删繁就简
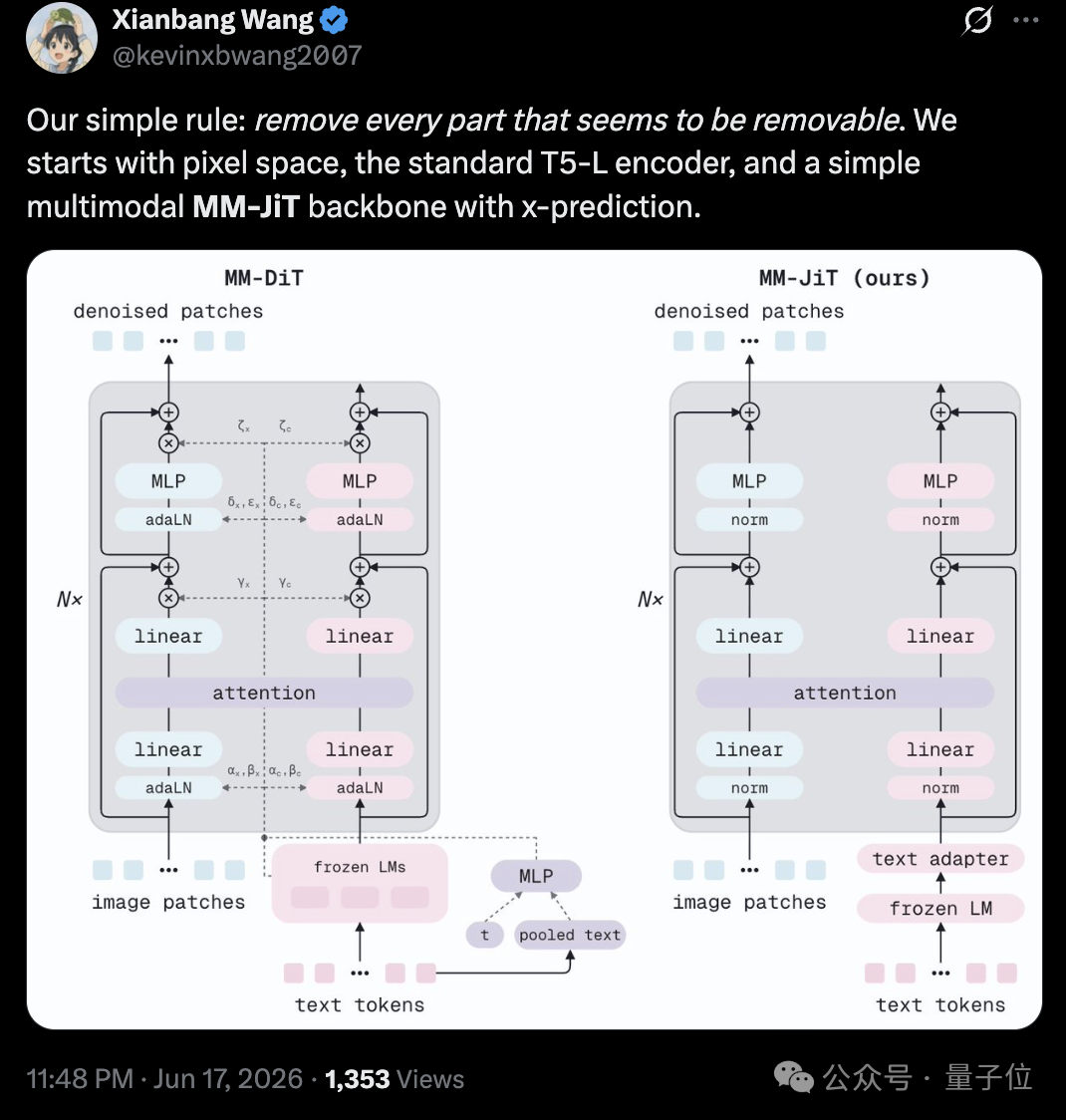
对于上面这个问题,MiniT2I 项目负责人王衔邦在 X 上的总结非常精炼:我们的原则很简单,能去掉的全去掉。起点是像素空间、标准的 T5-Large 编码器,以及一个采用 x-prediction 的简洁多模态骨干 MM-JiT。
这套思路的第一刀,砍向了 VAE。众所周知,当前主流文生图模型大多采用潜在扩散(Latent Diffusion)路线:先通过 VAE 把图像压缩到低维潜空间,再在潜空间里完成扩散生成,最后解码回像素。这样做的好处是显著降低计算量,但代价也很明显,VAE 会带来重建误差和伪影,同时还额外增加了一套编解码器的训练流程。
针对这一问题,在前作 JiT 中,团队已经证明,至少在 ImageNet 任务上,直接在像素空间建模并不存在所谓的 “不可逾越瓶颈”。那么在文生图任务里,VAE 是否真的不可替代?团队决定直接把它删掉试试。
MiniT2I 将扩散过程重新搬回像素空间,希望验证一个看似反常识的判断:直接在像素空间扩散,不仅完全可行,而且未必比潜空间路线更贵。
实验表明,传统潜空间模型单次前向传播需要 1379 GFLOPs,而彻底摆脱 VAE 之后,MiniT2I 的计算开销仅为 265 GFLOPs,直接降低了约 80%。
删掉 VAE 之后,团队又把目光转向了模型架构本身。前作 JiT 面向的是 ImageNet 分类条件生成,因此采用标准 DiT,并通过 AdaLN-Zero 注入类别标签和时间步信息。但到了开放式文生图任务,最自然的参考对象就变成了 SD3 采用的 MM-DiT。
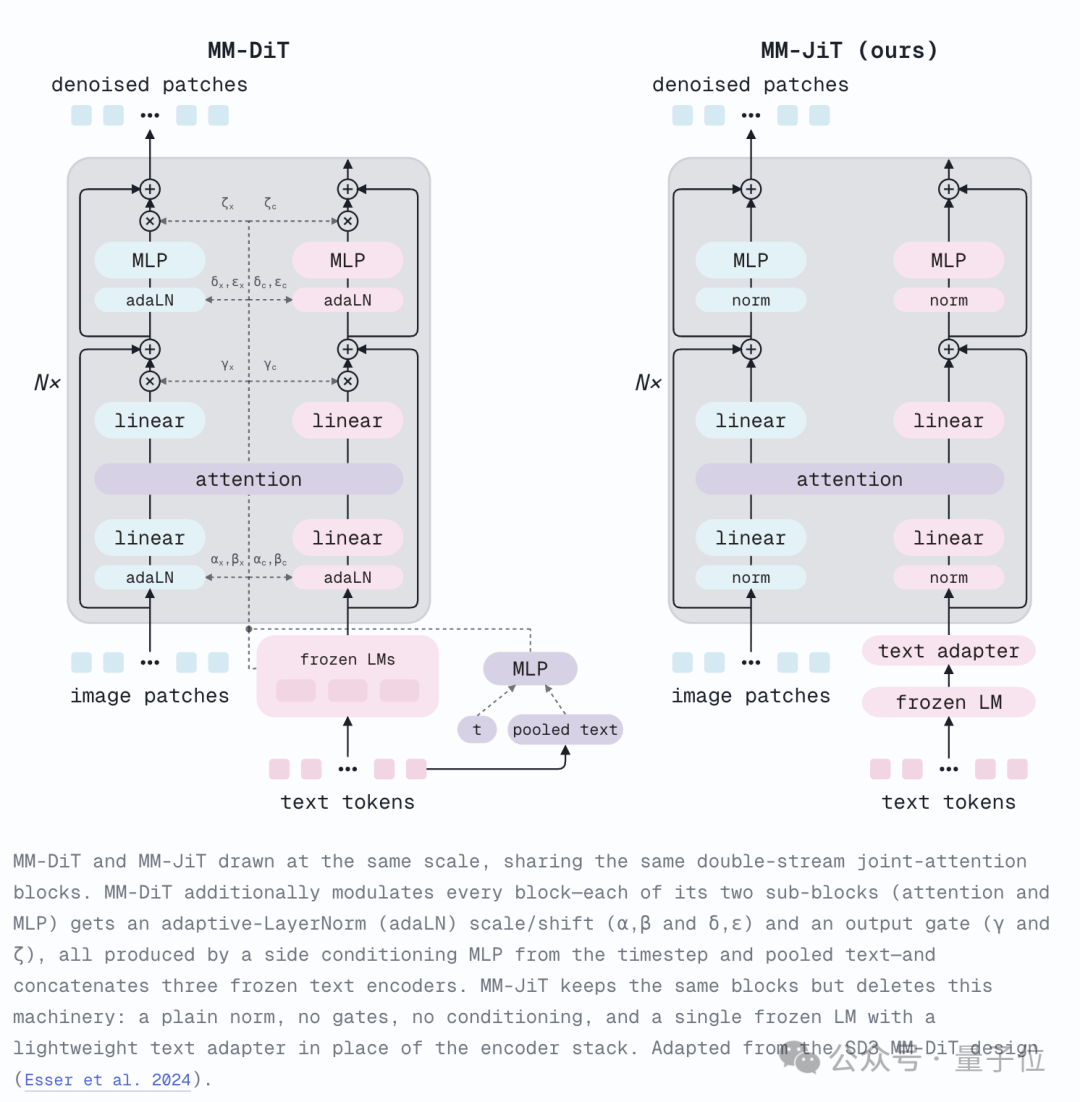
在团队看来,MM-DiT 身上仍然挂着不少 “历史包袱”,其中最典型的就是 AdaLN 机制,模型会把时间步和池化后的文本特征转换成缩放、偏移和门控参数,并注入到每一层网络中。
MM-JiT 的选择则相当激进:直接把 AdaLN 整个删掉。理由也很简单,扩散模型当前所处的噪声水平,其实已经包含在加噪后的输入 z_t 里。换句话说,模型完全可以自己推断当前处于扩散过程的哪个阶段,并不需要额外开一条通道专门传递时间步信息。
于是,条件信息只通过联合注意力这一条路径进入模型,整个骨干网络也回归到更接近标准 Pre-Norm Transformer 的形式。与此同时,团队只额外增加了两个 Text Adapter Block,放在联合注意力之前,让冻结的 T5 文本特征先完成一次适配,再与图像 Token 交互。
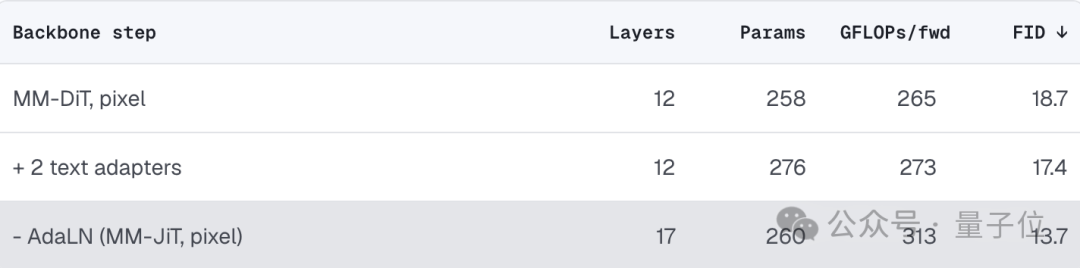
实验结果再次验证了团队的判断,参数量几乎保持不变,依旧只有 260M,但模型性能却一路提升:FID 从 18.7(MM-DiT 像素空间基线),提升到 17.4(加入 Text Adapter),最终达到 13.7(移除 AdaLN 后的 MM-JiT)。
训练与实验
在具体实现上,MiniT2I 基于流匹配(Flow Matching)框架,网络直接预测干净图像,并在速度空间计算损失。训练分为两个阶段:首先在 CC12M 上预训练 25 万步,学习基础视觉分布;随后在 12 万张高质量合成图像上微调 4 万步,进一步提升 Prompt 遵循能力。
结果证明,这套极简设计并没有牺牲性能。B/16 版本总参数量不到 600M,在 GenEval 上达到 0.87、DPG-Bench 达到 84.2,超过了多款参数规模数倍于自身的像素空间文生图模型。

更重要的是,完成这一训练仅需约等于一次标准 ImageNet 实验的算力预算 ——8 张 H100,大约 3 天。
即便与工业级模型相比,MM-JiT 也展现出不俗竞争力。在 PRISM-Bench 上,L/16 版本取得 62.4 分,而 FLUX.1-dev 为 68.5 分。具体来看,模型在风格表现和开放想象力两个维度甚至超过了 FLUX;
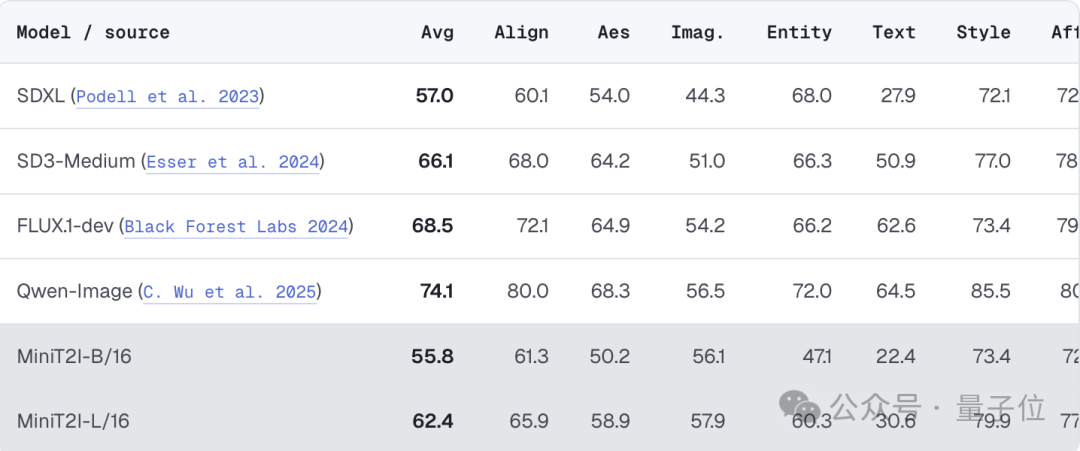
短板方面,则主要集中在文字渲染和命名实体生成,这与公开训练数据覆盖范围有限有关。(注:具体实验设置可参考文末博客链接)
作者介绍
这篇工作最值得聊的,除了技术本身,还有背后的作者们。整篇论文一共六位作者,除了何恺明之外,其余五位都还是本科生。而且,这些年轻面孔并不是第一次出现在论文作者栏里,在何恺明团队此前的多篇工作中,他们都已经开始崭露头角。

项目负责人王衔邦 (Xianbang Wang),目前是 MIT 大一本科生,去年刚从人大附中毕业。

2024 年,他代表中国队参加第 65 届国际数学奥林匹克竞赛 (IMO),拿下金牌。更早之前,他还在 2021 年和 2022 年斩获全国信息学奥林匹克竞赛的银牌。在这项工作之前,他已经是何恺明团队 Bidirectional Normalizing Flow 论文的共同第一作者。

另一位核心贡献者赵瀚宏 (Hanhong Zhao),目前是 MIT 大二学生,曾获得国际物理奥林匹克竞赛(IPhO)金牌。

不久前引发关注的 ELF(连续扩散语言模型)论文中,赵瀚宏也是作者之一。
核心贡献者陆伊炀 (Yiyang Lu) 则来自清华大学姚班,目前大二,在 MIT CSAIL 实习,导师正是何恺明。

高中时期,他是物理竞赛生,曾以江苏省第一、全国第九的成绩获得第 39 届全国中学生物理竞赛(CPhO)金牌。此前,他已经与何恺明合作完成 Bidirectional Normalizing Flow、Pixel Mean Flow 等工作,在 ELF 论文中同样名列作者名单。
周康阳(Kangyang Zhou)也是 MIT 本科生 (Class of 2029),背景更偏信息学方向。2024 年,他在第 36 届国际信息学奥林匹克竞赛(IOI)中夺冠,并以 600 分满分成为当届唯一满分选手。更早的 2023 年,他以全国信息学奥林匹克竞赛(NOI)金牌第一名的成绩入选柄家集训队,领先第二名 55 分。今年,他还作为 MIT 代表队成员获得 ICPC 2026 北美锦标赛冠军。
马麟瑞(Linrui Ma)同样毕业于人大附中,目前在 MIT 就读本科。

他曾担任中国国家队队长,在第 56 届国际化学奥林匹克竞赛(IChO 2024)中获得金牌。
最后再简单介绍一下何恺明。目前,他是 MIT EECS 终身副教授,同时兼任 Google DeepMind 杰出科学家。

他是深度学习、计算机视觉一系列重要工作,如 ResNet、Faster R-CNN、Mask R-CNN、MoCo、MAE 的作者,其中,ResNet 是 21 世纪被引用次数最多的论文。
某种程度上说,这篇论文最有意思的地方,不只是提出了一个新方法,更像是一群刚刚走出奥赛赛场的年轻人,已经开始站上 AI 研究最前沿的舞台。