编程语言如何模仿人类语言?
2026-05-26 17:25:16 · chineseheadlinenews.com · 来源: 本征时代
引言
语言是认知压缩(cognitive compression)的核心工具——用有限的符号表达无限的思想。但当程序员试图用编程语言模仿这种压缩能力时,他们发现了一个根本性的矛盾:自然语言的压缩是"有损"的,而编程语言要求"无损"。1956年,诺姆·乔姆斯基(Noam Chomsky, 1928-)的形式语言理论(formal language theory)用数学证明了这场模仿为何注定是部分的、渐进的。本文通过"压缩"这一核心框架,重新审视编程语言与自然语言的本质差异。
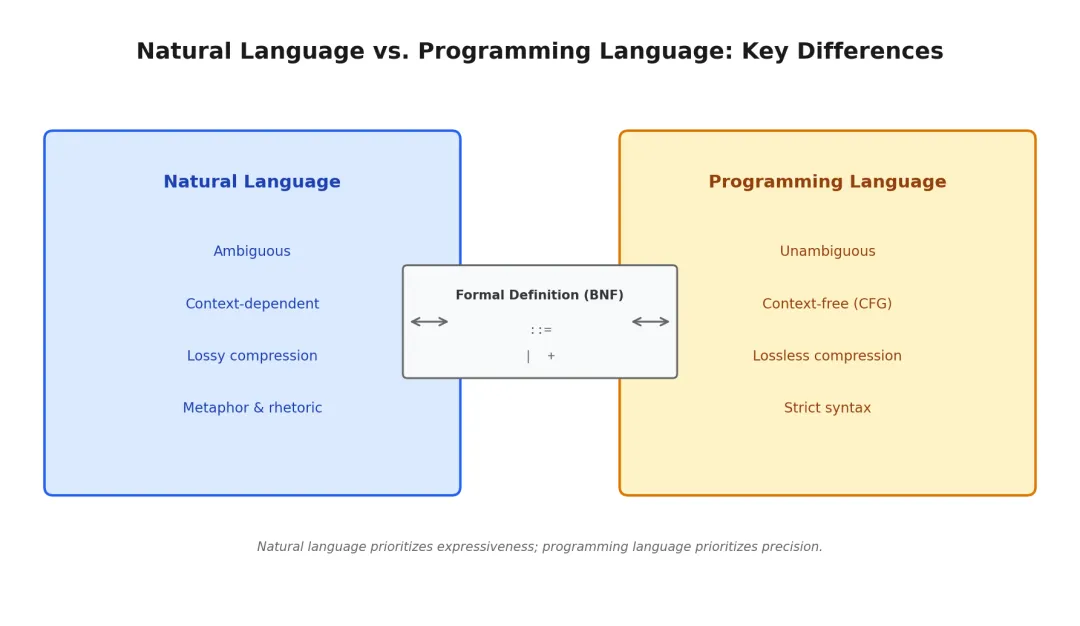
自然语言与编程语言的本质差异:有损压缩 vs 无损压缩
一、语言作为压缩:形式语言理论的核心洞见
1.1 压缩的本质:用有限表达无限
想象一个场景:一位母亲对孩子说"把鞋子穿上,我们出门"。这句话只有十几个字,却传达了完整的意图——穿鞋、准备离开、目的地是户外。这是一种认知压缩:说者将复杂的场景、因果关系、情感色彩压缩进简短的语句,听者则依靠语境和常识解压缩。
1956年,27岁的诺姆·乔姆斯基(Noam Chomsky, 1928-)在麻省理工学院提出了一个革命性的问题:这种压缩能力能否被形式化?他发现,语言的压缩能力可以通过生成式文法(generative grammar)来刻画——有限的规则可以生成无限的句子。这种"压缩"不是简单的数据缩减,而是一种递归的符号系统:用符号的组合与替换,表达无穷多的意义。语言的本质不是词汇的堆砌,而是有限规则对无限表达的压缩。乔姆斯基的洞见在于:这种压缩能力本身可以被形式化——用数学来描述人类最基本的认知能力。
1.2 Chomsky层级在编程语言中的应用
如 Part 6 中详细讨论的,Chomsky层级(Chomsky hierarchy)揭示了不同形式文法具有不同的压缩能力:正则文法(Type 3)最弱但最高效,上下文无关文法(Type 2, context-free grammar)允许递归结构,上下文有关文法(Type 1, context-sensitive grammar)允许规则依赖上下文,递归可枚举语言(Type 0, recursively enumerable)与图灵机等价。这个层级结构揭示了压缩能力越强,分析(parsing)的代价越高这一深刻洞见。
编程语言的设计者们早就意识到这一规律。大多数现代编程语言选择上下文无关文法(Type 2)作为语法基础——它足够强大以表达嵌套结构,又不会带来过高的解析复杂度。例如,大多数编程语言的语法可以用BNF(巴科斯-诺尔范式, Backus-Naur Form)来描述,这是一种与Chomsky的上下文无关文法等价的形式系统。
1.3 正则文法的极限:泵引理与自然语言的复杂性
正则文法(Type 3)是Chomsky层级中最弱的形式系统。尽管正则表达式在文本搜索、词法分析中极其高效,但它无法捕捉自然语言中的递归结构。这一根本性局限可以用泵引理(pumping lemma)来严格证明。
泵引理的核心思想是:对于任何正则语言,存在一个"泵长度"p,使得长度不小于p的字符串,可以被分解为xyz三部分,且对所有i≥0,字符串xyiz仍属于该语言。换句话说,正则语言中的字符串具有某种可预测的重复结构。
考虑一个简单的例子:语言L = {anbn | n ≥ 0}(n个a后跟n个b)。这个语言不是正则的。假设L是正则的,设泵长度为p。取字符串s = apbp。根据泵引理,s可以分解为xyz,其中y非空且|xy| ≤ p。因此y只能由a组成(因为前p个字符都是a)。于是xy2z = ap+|y|bp,其中a的个数多于b的个数,不属于L。矛盾。因此anbn不是正则语言。
这个结论对自然语言处理有深远影响。类似"n个修饰语后跟n个中心词"的递归结构(如"非常非常……非常高的大楼")在自然语言中普遍存在,但正则文法无法生成这种结构。这正是自然语言复杂性的数学根源。
1.4 上下文无关文法的局限:歧义与交叉依赖
上下文无关文法(CFG)比正则文法更强大,能够处理嵌套结构和括号匹配等递归模式。然而,CFG在处理自然语言时仍面临两个根本性局限:固有歧义(inherent ambiguity)和交叉依赖(cross-serial dependencies)。
固有歧义:某些语言同时存在多种解析树,无法通过消歧规则消除。例如,"Old men and women"可以理解为"年长的男人和所有女人"或"所有年长的人和女人"——这是英语中的著名歧义句。上下文无关文法无法消除这种歧义,因为歧义源于语义层面而非句法结构。
交叉依赖:自然语言中存在跨越句子边界的长距离依赖关系。例如,在"The author of the book about the city that the researcher liked sent a message."中,"author"和"sent"之间的主谓关系需要追踪整个名词短语链才能确定。这种长距离依赖超出了上下文无关文法的能力范围。
舒斯特·谢伯(Stuart Shieber)在1985年的论文中证明,上下文无关文法无法处理某些语言现象,如瑞士德语中的交叉依赖结构。这促使研究者求助于更强大的形式系统——上下文有关文法(Type 1),甚至递归可枚举语言(Type 0)。然而,更强大的文法意味着更高的解析复杂度,这构成了理论与实践之间的根本张力。
1.5 属性语法:突破CFG限制的尝试
为了克服上下文无关文法的局限,研究者提出了属性语法(attribute grammars)——在CFG的基础上添加语义规则。属性语法由Donald Knuth在1968年提出,每个文法符号可以携带"属性",属性之间通过规则进行约束和推导。
例如,考虑一条简单的英语句子规则:S → NP VP。一个NP(名词短语)的属性可能包括"数"(单数/复数)和"人称"(第一/第二/第三人称)。属性规则确保:如果NP是复数,VP也必须是复数(如"They are"而非"He are")。这种约束超出了上下文无关文法的能力范围。
然而,属性语法同样面临挑战:属性之间的约束可能导致推导过程中的循环依赖,解析复杂度也会显著增加。在实践中,属性语法被用于特定领域(如编译器前端类型检查),但在通用NLP任务中,其效果有限。
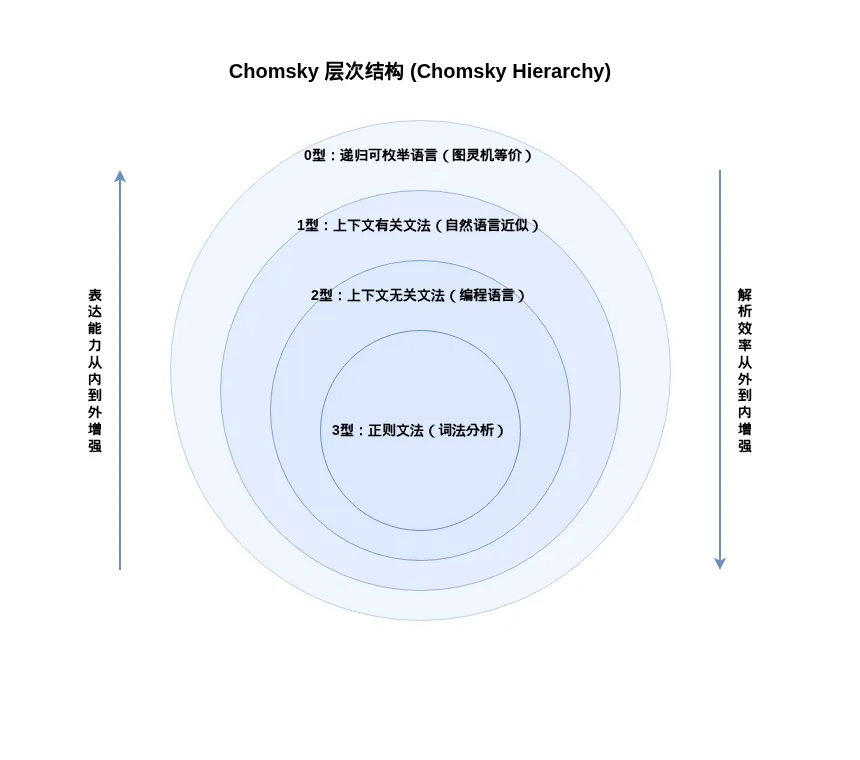
Chomsky层级在编程语言设计中的应用:压缩能力与解析效率的权衡
1.6 巴科斯-诺尔范式:用形式符号压缩语法结构
1959年,IBM的约翰·巴科斯(John Backus, 1924-2007)为了精确描述ALGOL 58的语法,在UNESCO会议上提出了巴科斯-诺尔范式(Backus-Naur Form, BNF)。BNF是一种用递归定义来压缩语法结构的方式: ::= | + ::= | * ::= | ( )
这里,::= 表示"定义为",| 表示"或"。一个表达式可以是项,也可以是表达式加项;一个项可以是因子,也可以是项乘因子;一个因子可以是标识符,或用括号包围的表达式。这个递归定义用三个规则,压缩了无限多算术表达式的语法结构。
BNF与Chomsky的上下文无关文法惊人地相似——它们都是用递归规则压缩无限语法结构的方式。Donald Knuth在1964年的一篇短文中指出了这种对应关系,并建议将"巴科斯范式"更名为"巴科斯-诺尔范式"以纪念丹麦计算机科学家Peter Naur的贡献。历史学家后来发现,BNF的思想源头可以追溯到约公元前4世纪的印度。语言学家波你尼(Panini, 约公元前4世纪)在《八章书》(Ashtadhyayi)中发明了一套类似的元语言符号系统,用递归定义来描述梵语语法。这比BNF早了约2300年。
二、编程语言的诞生——为何计算机需要语言?
2.1 机器码时代的困境
1950年代,计算机诞生初期,程序员直接用机器码(0和1的序列)与机器交流。每条指令都是一串二进制数字,例如 `10110001 01010010` 可能代表"将寄存器A的值加到寄存器B"。这种交流方式对人类极为不友好:难以记忆、容易出错、无法在不同型号的机器之间移植。
机器码的困境本质上是认知带宽的不匹配:人类的认知压缩能力习惯于用符号和规则表达复杂操作,而机器只能理解最原始的0/1信号。程序员必须将高级算法"解压"成机器指令,这个过程既缓慢又容易出错。
2.2 FORTRAN的革命(1957)
约翰·巴科斯(John Backus, 1924-2007)在IBM工作时,意识到这个问题的严重性。1957年,他主导设计的FORTRAN(Formula Translation)成为第一种广泛应用的高级编程语言。FORTRAN的核心创新是让科学家可以用接近数学的语法Y = X + 1来编程,而不是一串难以理解的二进制指令。
C FORTRAN 代码示例 REAL X(100), Y(100) DO 10 I = 1, 100 Y(I) = X(I) + 1.0 10 CONTINUE
编译器(compiler)是这场帮命的关键技术:它负责将高级语法翻译成机器指令。程序员用人类可读的语法编写程序,编译器自动完成"解压"过程。这标志着认知压缩工具首次进入计算机领域——人类用压缩的符号表达,机器负责解压缩执行。
2.3 LISP与函数式传统(1958)
同年,约翰·麦卡锡(John McCarthy, 1927-2011)在麻省理工学院设计了LISP(List Processing)。与FORTRAN不同,LISP的灵感来自阿隆佐·邱奇(Alonzo Church, 1903-1995)的lambda演算——一种关于函数定义与应用的数学理论。麦卡锡认为,邱奇的lambda演算是编程语言最优雅的理论基础。
; LISP 代码示例 - S表达式 (defun factorial (n) (if (
18; 这条语句用接近英语的语法,压缩了复杂的数据查询操作。用户不需要理解底层的数据结构、索引机制、连接算法——这些细节被SQL语言"压缩"掉了,程序员只需要表达"想要什么"。
这种"声明式"(declarative)的压缩哲学,与自然语言中的概念压缩有异曲同工之妙。当我们说"去超市买面包"时,我们压缩了"出门、走向超市、挑选面包、支付、回家"等一系列动作。SQL的SELECT语句同样是这种压缩思维的体现:描述目标,而非路径。
4.4 自然语言处理的困境:无法克服的有损压缩
形式语言理论在自然语言处理(Natural Language Processing, NLP)中的应用揭示了一个持续的困境:形式文法能够描述编程语言的语法,但无法完全捕捉自然语言的复杂性。NLP的发展史,就是一部不断尝试、不断碰壁、不断转向的历史。
1980年代是形式语言学派的黄金时代。基于Chomsky理论的NLP系统主导了学术研究。这些系统使用手工编写的语法规则,分析输入句子的句法结构,然后进行语义解释。然而,规则派的局限性很快暴露出来:手工编写规则的代价极高、规则脆弱、跨语言迁移困难。
1990年代:统计革命。1990年,IBM的彼得·布朗(Peter F. Brown, 1955-)团队在《计算语言学》期刊上发表了开创性论文,发起了统计革命。统计翻译模型完全绕过了句法分析:收集大量双语语料,统计词汇对齐的概率分布,给定输入,利用统计信息生成最可能的翻译。1993年,肯尼斯·丘奇(Kenneth Church, 1955-)与罗伯特·默瑟(Robert Mercer, 1946-)为《计算语言学》期刊编辑了关于大规模语料库方法的特刊导言,标志着统计方法在NLP领域的影响力日益增长。统计方法逐渐占据上风,并在1990年代末主导了整个NLP领域。
量化数据:统计方法的性能。在1990年代,基于统计方法的机器翻译系统逐渐取代了规则系统。以NIST MT评估为例,1999年的MT系统BLEU分数约为0.18(满分1.0),到2003年提升至0.34。早期的统计机器翻译系统(如IBM Model 1-5)在句子级别翻译尚可,但无法处理长距离依赖和语序调整问题。
2000年代:机器学习的深化。统计方法的成功催生了更复杂的机器学习模型。支持向量机(SVM)、条件随机场(CRF)、最大熵模型等方法被广泛应用于词性标注、命名实体识别、句法分析等任务。这些方法的共同特征是:用人工设计的特征(feature engineering)将语言现象转化为数值向量,再用统计模型学习分类边界。特征工程本身就是一种压缩——研究者需要判断哪些语言信息是"有用的",哪些可以丢弃。
量化数据:传统ML方法的准确率。在Penn Treebank词性标注任务上,条件随机场(CRF)的准确率约为97%(1998年)。命名实体识别(NER)任务上,基于特征的CRF模型F1值约为89%(2003年)。然而,这些方法依赖人工设计的特征,难以捕捉语言的深层语义结构。
2017年:Transformer的出现。2017年,谷歌团队发表了"Attention Is All You Need"一文,提出了Transformer架构。这一架构彻底改变了NLP的技术路线。Transformer的核心创新是自注意力机制(self-attention):模型不再按顺序处理文本,而是同时关注输入序列中所有位置之间的关系。这种并行处理方式使得模型能够捕捉长距离依赖关系——而这正是形式文法长期难以处理的问题。从压缩的视角看,Transformer学会了一种新的压缩方式:将整个句子的上下文信息压缩进每个词的向量表示中。
量化数据:Transformer带来的性能飞跃。在WMT14英语-德语翻译任务上,Transformer基线模型达到28.4 BLEU(相比上一代最好的RNNseq2seq模型提升超过2 BLEU)。到了2018年,"Attention Is All You Need"论文中的大型模型将BLEU分数提升至41.8。在GLUE基准测试(涵盖9项NLU任务)上,BERT-Large在2018年达到80.5%(远超基于特征的基线方法的69%)。这些数据证明了Transformer架构在学习语言表征方面的巨大优势。
当前:大语言模型对形式语言理论的挑战。基于Transformer的大语言模型(GPT、BERT等)在几乎所有NLP基准测试上取得了突破性成绩。这些模型没有显式的语法规则,没有Chomsky层级的概念,却能生成语法正确、语义连贯的文本。这对形式语言理论提出了根本性的挑战:如果一个没有形式文法的系统能够"掌握"语言,那么形式文法对于理解语言究竟有多重要?2021年,本德(Emily M. Bender, 1973-)等人在"On the Dangers of Stochastic Parrots"一文中提出了尖锐的批评:大语言模型的"流利"输出可能只是统计模式的复现,而非真正的语言理解。这场争论至今未有定论,但它迫使我们重新思考:语言的本质究竟是形式结构,还是统计规律,还是两者兼而有之?
五、大模型时代的启示:重新审视压缩的关系
5.1 大语言模型与压缩的统一
2020年代,大语言模型(Large Language Model, LLM)的兴起为编程语言研究带来了新的可能性。GitHub Copilot、ChatGPT等工具可以根据自然语言描述生成代码,引发了关于"程序员是否会被AI取代"的广泛讨论。
从压缩的视角看,LLM代表了自然语言与编程语言融合的一种可能:通过大规模训练,LLM学会了将自然语言的"有损压缩"映射为编程语言的"无损压缩"。当用户说"写一个函数来排序列表",LLM将这个模糊的指令"解压缩"为精确的代码实现。
然而,LLM生成的代码面临一个根本挑战:如何保证正确性?自然语言描述往往是模糊的、歧义的,同一个描述可能对应多种不同的实现。例如,用户说"按时间排序",但没有说明是升序还是降序,也没有说明时间戳的格式。这种歧义性正是自然语言作为有损压缩的体现。
5.2 神经符号编程:两种压缩的融合
未来的编程语言可能会更加智能化,能够自动理解和处理模糊的自然语言描述。一个重要的发展方向是"神经符号编程"(neuro-symbolic programming):将神经网络的模式识别能力与符号系统的推理能力结合起来。
这种混合方法可能能够同时处理自然语言的歧义性和编程语言的精确性:神经网络负责处理"有损压缩"的不确定性,符号系统负责验证"无损压缩"的正确性。类型系统、形式验证(formal verification)、程序分析等技术,可以用来检查LLM生成的代码是否符合规范。
另一个方向是"意图编程"(intent-based programming):用户用自然语言描述目标,系统自动生成实现。这种愿景早在1960年代就被提出,但直到大语言模型时代才看到实现的可能。从压缩的视角看,意图编程是让机器学习如何将"有损压缩"(自然语言描述)转换为"无损压缩"(精确代码)的过程。
大语言模型的出现,模糊了两种压缩的边界。LLM能够将自然语言描述转换为精确代码,但这种转换是不稳定的——因为自然语言的有损压缩无法被完全消除。在这个意义上,编程语言对人类语言的模仿,永远只能是部分的、近似的。
六、结语:认知压缩的最优解
编程语言对人类语言的模仿,揭示了形式压缩的极限与自然语言压缩的智慧。Chomsky的语类阶层证明了不同形式文法有不同的压缩能力——正则文法最弱但最高效,上下文无关文法更强但代价更高,递归可枚举语言对应计算的终极边界。
自然语言的压缩是有损的——歧义性、上下文依赖、递归的模糊性,都是这种有损压缩的特征。但这并非缺陷,而是在认知资源约束下的最优策略。人脑能够在实时处理中利用语境和常识"填补"丢失的信息,这种能力是自然语言作为认知压缩工具的核心优势。
编程语言必须追求无损压缩——歧义会破坏压缩的完整性,导致编译失败或错误行为。类型系统、形式验证、编译时检查等技术,都是为了确保这种完整性。从FORTRAN到Java,从BNF到类型系统,编程语言的设计者一直在探索如何在保持表达力的同时实现无损压缩。
形式语言理论揭示的,不是语言的边界,而是认知压缩的可能性边界。在这个边界内,人类语言找到了最优解:用有损压缩实现最大化的表达效率。这个洞见,或许比任何编程语言的设计都更深刻。
七、下期预告
数学公式是语言吗?Part 12-1 将探讨数学符号系统的起源与特征——弗雷格、罗素如何将数学语言从自然语言中分化出来,形式系统如何实现更高的压缩精度。