谢赛宁:统一多模态模型
2025-05-16 04:25:39 · chineseheadlinenews.com · 来源: 量子位
统一图像理解和生成,还实现了新SOTA。
谢赛宁等团队推出了统一多模态模型Blip3-o。

与传统的基于VAE的表征不同,他们提出了一种新方法,使用扩散Transformer来生成语义丰富的CLIP图像特征。这种设计提高了训练效率,又提升了生成质量。
此外,他们还证明,先进行图像理解训练,再进行图像生成训练的统一模型顺序预训练策略,具有实用优势,既能保持图像理解能力,又能培养强大的图像生成能力。
网页端可以免费体验Demo~
统一多模态模型Blip3-o
在最近的多模态模型研究中,图像理解与生成的统一受到越来越多的关注。尽管研究人员们对图像理解的设计选择进行了广泛的研究,但对图像生成统一框架的最佳模型架构和训练方法的研究仍然不足。
在这一背景下,团队又看到了自回归和扩散模型在高质量生成和可扩展性方面有强大的潜力。于是乎,他们开始对统一多模态模型进行了全面研究,重点关注图像表示、建模目标和训练策略。
统一架构
这些基础上,他们提出了一种新的统一架构。同样包括两部分。
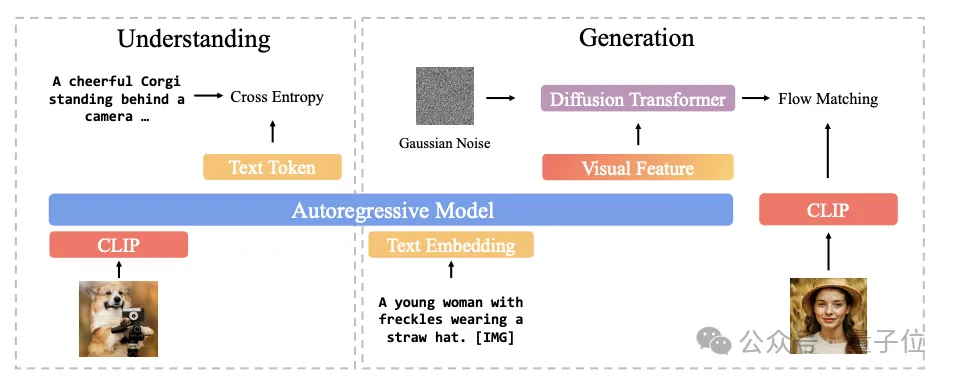
图像理解部分,他们使用CLIP对图像进行编码,并计算目标文本标记与预测文本标记之间的交叉熵损失。
在图像生成部分,自回归模型首先生成一系列中间视觉特征,然后将其作为扩散Transformer的条件输入,生成CLIP图像特征,以逼近地面真实的CLIP特征。
通过使用CLIP编码器,图像理解和图像生成共享同一个语义空间,从而有效地统一了这两项任务。
设计方案
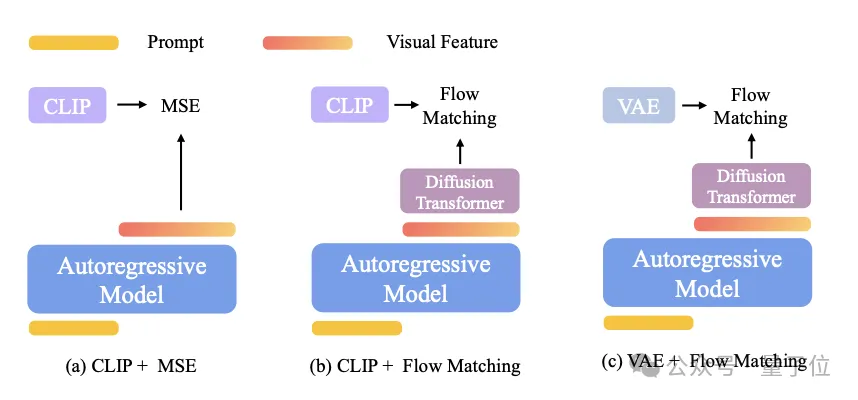
具体来说,他们在图像生成部分,尝试了三种设计方案——所有设计都使用了自回归+扩散框架,但图像生成组件各不相同。
对于流匹配损失,他们冻结了自回归模型,只对图像生成模块进行了微调,以保留模型的语言能力。
结果显示,CLIP+Flow Matching在GenEval和DPG-Bench上都获得了最佳的提示对齐得分,而VAE+Flow Matching产生的FID最低(最佳),表明美学质量上乘。
不过,FID有其固有的局限性:它量化的是与目标图像分布的风格偏差,往往忽略了真正的生成质量和即时配准。他们在MJHQ-30k数据集上对GPT-4o进行的FID评估得出的分数约为30.0,这说明FID在图像生成评估中可能会产生误导。
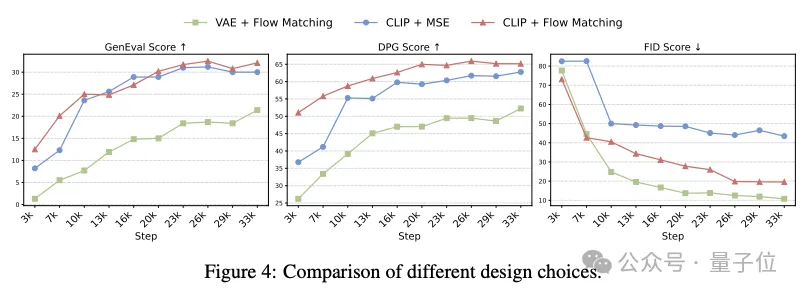
最终,他们确定CLIP+Flow Matching是最有效的设计选择。
将图像生成整合到统一模型中时,自回归模型比像素级表征(VAE)更有效地学习语义级特征(CLIP);采用流匹配作为训练目标能更好地捕捉底层图像分布,从而提高样本多样性和视觉质量。
训练策略
随后,他们开始研究训练策略: >到底是联合训练还是顺序训练?
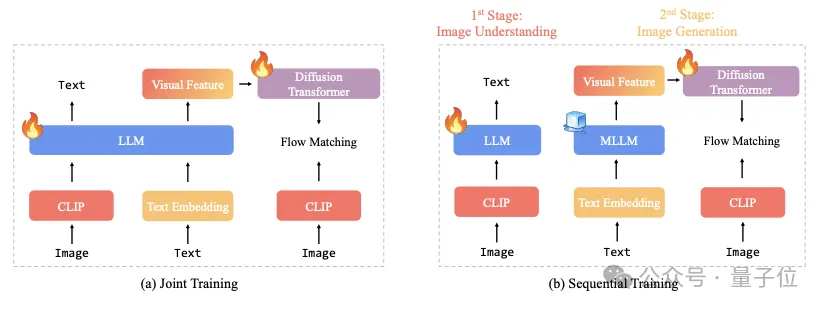
在联合训练设置中,尽管之前研究证明图像理解和生成任务可能互惠互利,但有两个关键因素会影响它们的协同效应:
(i)总数据量和(ii)图像理解和生成数据之间的数据比例。
相比之下,顺序训练具有更大的灵活性:它允许冻结自回归骨干,并保持图像理解能力。这样一来,可以将所有训练能力用于图像生成,避免联合训练中的任何任务间效应。同样受LMFusion和MetaQuery的启发,我们决定选择顺序训练来构建统一的多模态模型,并将联合训练留待未来工作中使用。
最终在图像理解和生成任务的大多数热门基准测试中均取得了卓越的性能。
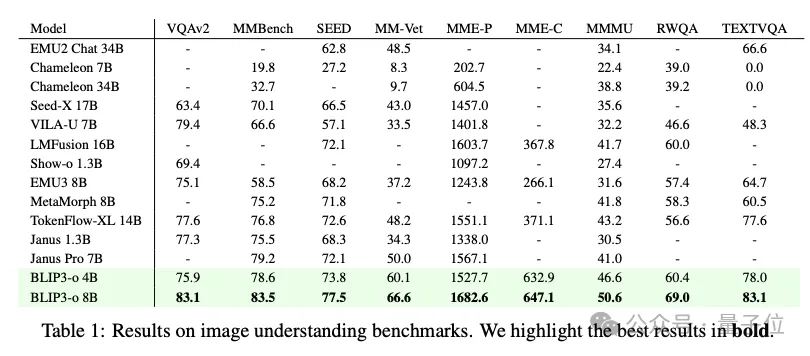
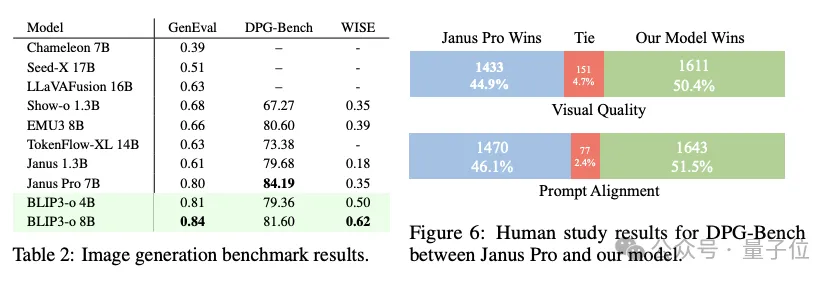
总之,团队首次系统地探讨了用于统一多模态建模的混合自回归和扩散体系结构,评估了三个关键方面:图像表征(CLIP与VAE特征)、训练目标(流量匹配与MSE)和训练策略(联合与顺序)
实验证明,CLIP嵌入与流匹配loss搭配使用,可以提高训练效率和输出质量。基于这些见解,他们推出了BLIP3-o,这是一个最先进的统一模型系列,使用60k指令调整数据集BLIP3o-60k进行了增强,大大提高了提示对齐和视觉美感。
为了方便未来的研究,他们完全开源了模型,包括代码、模型权重、训练脚本以及预训练和指导调整数据集。
目前正在积极开发统一模型的应用,包括迭代图像编辑、视觉对话和逐步视觉推理。
华人占大多数
此研究由Salesforce、马里兰大学、弗吉尼亚理工、纽约大学、华盛顿大学等机构共同完成。
团队中大部分都是华人。

共同一作有四位,他们分别是马里兰大学博士生Jiuhai Chen,目前在Salesforce实习;弗吉尼亚理工大学博士生Zhiyang Xu;纽约大学博士生Xichen Pan,谢赛宁学生,本科毕业于上海交大;华盛顿大学博士生Yushi Hu。
项目Lead是Salesforce的高级应用科学家Le Xue。