清华UDS智能过滤劣质样本
2026-06-27 21:25:40 · chineseheadlinenews.com · 来源: 量子位
大模型做监督微调(SFT),是不是数据越多越好?
直觉上,当然是把完整数据集都喂给模型最稳妥。但在真实训练里,事情并没有这么简单。
全量SFT不仅计算成本高,还可能带来过拟合、偏见放大等问题。更关键的是,一个训练集里的样本价值并不相同:有些样本信息量很高,值得反复学习;有些样本高度重复,继续训练只是在浪费算力。
于是,一个问题变得越来越重要:
能不能在训练过程中,让模型一边看数据,一边自动挑出最值得更新参数的样本?
来自清华大学自动化系的研究者提出了UDS(Utility-Diversity Sampling),一个面向大语言模型SFT的在线batch选择框架。
一句话概括:UDS不是简单挑loss最大的样本,而是利用前向传播中已经产生的logits,同时评估样本“有没有用”和“够不够多样”,从而在不依赖验证集、参考模型和额外反向传播的情况下,更高效地完成SFT。
实验显示,在MMLU、ScienceQA、GSM8K、HumanEval四个基准上,UDS在Llama-3.1-8B和Qwen-2.5-7B上都取得了在线batch选择方法中的最优表现。以Qwen-2.5-7B为例,UDS在MMLU上达到63.34%,相比GREATS提升5.15个百分点;同时训练吞吐量也高于全量SFT。

现有方法会“挑数据”,但挑得还不够聪明
在SFT中,最朴素的方法是全量训练:每个batch里的样本全部参与参数更新。
但这会带来两个问题。
第一,训练贵。大模型每一步反向传播都很耗时,如果大量样本本身价值有限,就会造成计算浪费。
第二,训练未必更好。数据里可能存在重复样本、低价值样本,甚至会让模型更容易过拟合到某些偏置模式。
因此,在线batch选择(online batch selection)成为一个自然方向:模型在训练时先看到候选batch,然后只选出其中一部分样本真正参与参数更新。
已有方法通常会根据样本的utility(效用)进行选择。比如:
MaxLoss:优先选择loss最大的样本;
MaxGrad:优先选择梯度范数最大的样本;
RHO-Loss:借助参考模型或验证集估计样本价值;
GREATS:进一步引入训练动态信息。
但这些方法仍有明显限制。
一方面,很多方法只看“这个样本难不难、有用没用”,却忽略了多样性。如果一个batch里都是相似样本,训练信号仍然会高度冗余。
另一方面,部分方法依赖外部验证集、参考模型,或者需要额外梯度计算,导致训练开销反而可能超过全量SFT。
论文因此提出,一个理想的在线batch选择方法,至少要满足三点:
同时考虑数据效用、样本内部多样性、样本之间多样性;
不依赖外部资源,例如验证集或参考模型;
训练总时间要比全量SFT更低。

△在线batch选择方法能力对比:UDS同时满足数据效用、样本内多样性、样本间多样性、无外部资源、训练时间降低五项要求
核心方法:用logits同时判断“有用”和“多样”
UDS的关键思想,是把模型前向传播时已经产生的logits用起来。
对于一个训练样本,LLM在每个token位置都会输出一个词表维度的logits向量。把整段序列所有token的logits拼在一起,就得到一个logits矩阵。
这个矩阵里其实包含了很多信息:
模型对这个样本是否不确定?
这个样本是否能带来较大的loss reduction?
序列内部的token预测是否丰富,还是高度重复?
这个样本和历史上已经训练过的样本是否过于相似?
UDS将这些信息拆成两个分数。
第一个是intra-sample importance score,也就是样本内部重要性分数。它通过logits矩阵的nuclear norm(核范数)计算,用来同时刻画样本效用和样本内部多样性。
第二个是inter-sample importance score,也就是样本之间重要性分数。它通过低维投影后的样本表示,与历史memory buffer中样本的距离来计算,用来避免反复训练相似样本。
最后,UDS把这两个分数加权合并,选出当前候选batch中分数最高的Top-K样本参与参数更新。
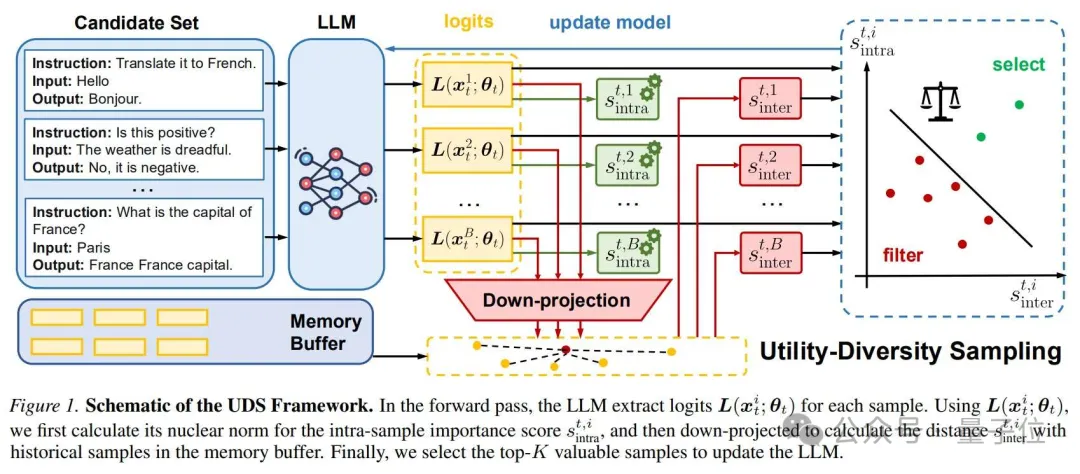
△UDS框架示意图:模型先对候选样本做前向传播,得到logits;再分别计算样本内部重要性和样本间多样性;最终选择高价值样本更新模型
为什么nuclear norm能衡量样本价值?
UDS的第一个核心设计,是用logits矩阵的nuclear norm衡量样本内部价值。
直观理解,nuclear norm越大,通常意味着两件事。
第一,样本更可能带来训练收益。
如果模型对某个样本的预测分布呈现出更强的训练信号,它往往更可能带来loss reduction。论文在Qwen-2.5-7B + MMLU上做了相关性分析,发现nuclear norm与训练后的loss reduction存在较强相关性。
第二,样本内部的信息更丰富。
如果一个样本的token预测高度重复,logits矩阵的行向量会更接近同一方向,矩阵秩较低;如果每个token都包含不同语义信息,logits矩阵会呈现更高秩、更丰富的谱结构,nuclear norm也会更高。
也就是说,UDS不是只看“这个样本难不难”,而是在看:
这个样本是否既有学习价值,又能提供足够丰富的token级训练信号。
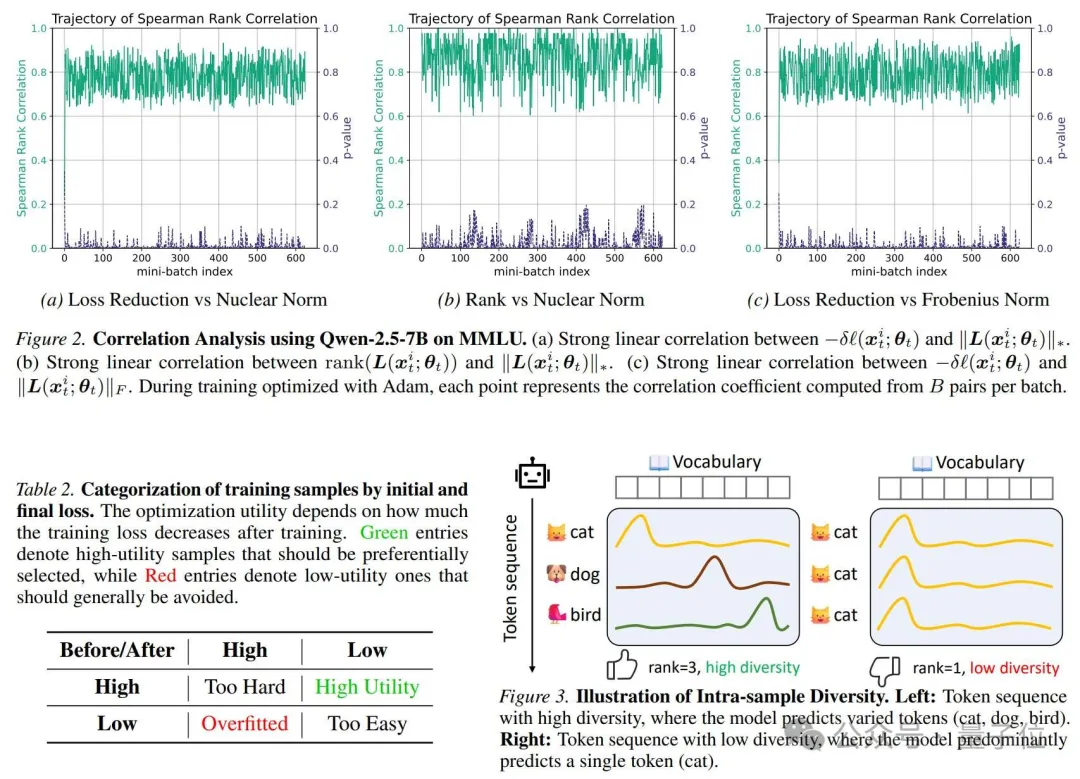
△相关性分析与样本内多样性示意:nuclear norm与loss reduction、矩阵秩之间存在明显相关;高多样性序列会呈现更丰富的预测分布
论文还给出一个简化例子:左边序列中模型预测cat、dog、bird等不同token,代表更高样本内多样性;右边序列几乎只预测cat,代表低多样性。

△高样本内多样性与低样本内多样性的对比
只看单个样本还不够,还要避免“重复训练”
如果只看nuclear norm,模型可能会持续选择某些高价值但相似的样本。
这在训练中也会造成浪费:单个样本看起来有用,但一整批样本如果高度重复,整体batch的信息增益并不高。
为了解决这个问题,UDS引入了样本之间的多样性建模。
具体做法是维护一个固定大小的FIFO memory buffer,用来保存最近被选中参与训练的样本表示。对于当前候选样本,UDS会计算它与memory buffer中历史样本的平均欧氏距离。距离越大,说明这个样本越不像最近已经训练过的数据,越值得加入训练。
但这里有一个现实问题:原始logits矩阵太大,直接保存代价非常高。
论文指出,如果在Qwen-2.5-7B中为1024个样本直接存储完整logits矩阵,内存可能达到约74GB。这显然不适合实际训练。
因此,UDS设计了一个低维投影方法,把logits矩阵压缩成紧凑向量,再放进memory buffer。论文采用类似SRFT的两侧随机投影,把词表维度和序列长度维度分别降维,从而避免显式存储巨大的投影矩阵。
这样一来,UDS就能用很低的额外开销近似保留样本之间的距离关系,并据此衡量全局多样性。
最终,UDS的选择标准可以理解为:
既选择当前最有训练价值的样本,也优先选择和历史训练样本不重复的样本。
实验设置:四类能力、两个基座、六组基线
论文主要在四个基准上评估UDS:
MMLU:通用知识理解;
ScienceQA:科学问答;
GSM8K:数学推理;
HumanEval:代码生成。
实验使用两个基座模型:Llama-3.1-8B和Qwen-2.5-7B。
对比方法包括:
Regular:不做数据选择,全量使用样本;
Random:随机选择样本;
MaxLoss:选择loss最大的样本;
MaxGrad:选择梯度范数最大的样本;
RHO-Loss:依赖参考模型的选择方法;
GREATS:已有在线batch选择SOTA方法。
实现上,论文默认采用LoRA训练,rank为8;batch size设为8;memory buffer大小M=1024;投影维度设置为d1=128、d2=8。所有基准采用zero-shot评估,并使用不同随机种子重复4次。
实验结果:准确率最高,训练还更快
主实验结果非常直接:UDS在四个基准、两个基座模型上都取得了最优准确率。
在Qwen-2.5-7B上,UDS的结果为:
MMLU:63.34%,高于GREATS的58.19%;
ScienceQA:95.19%,高于GREATS的94.17%;
GSM8K:79.91%,高于GREATS的78.61%;
HumanEval:46.28%,高于GREATS的45.04%。
在Llama-3.1-8B上,UDS同样取得最高结果:
MMLU:40.16%;
ScienceQA:94.33%;
GSM8K:58.98%;
HumanEval:30.96%。
更关键的是,UDS不只是更准,也更高效。
以Qwen-2.5-7B为例,在MMLU上,UDS的训练吞吐量为3.41samples/s,高于全量训练的2.27samples/s;在HumanEval上,UDS为6.81samples/s,同样高于全量训练的6.24samples/s。
这说明,UDS并不是通过“多花时间换准确率”,而是在更少训练开销下,选出了更高质量的训练信号。
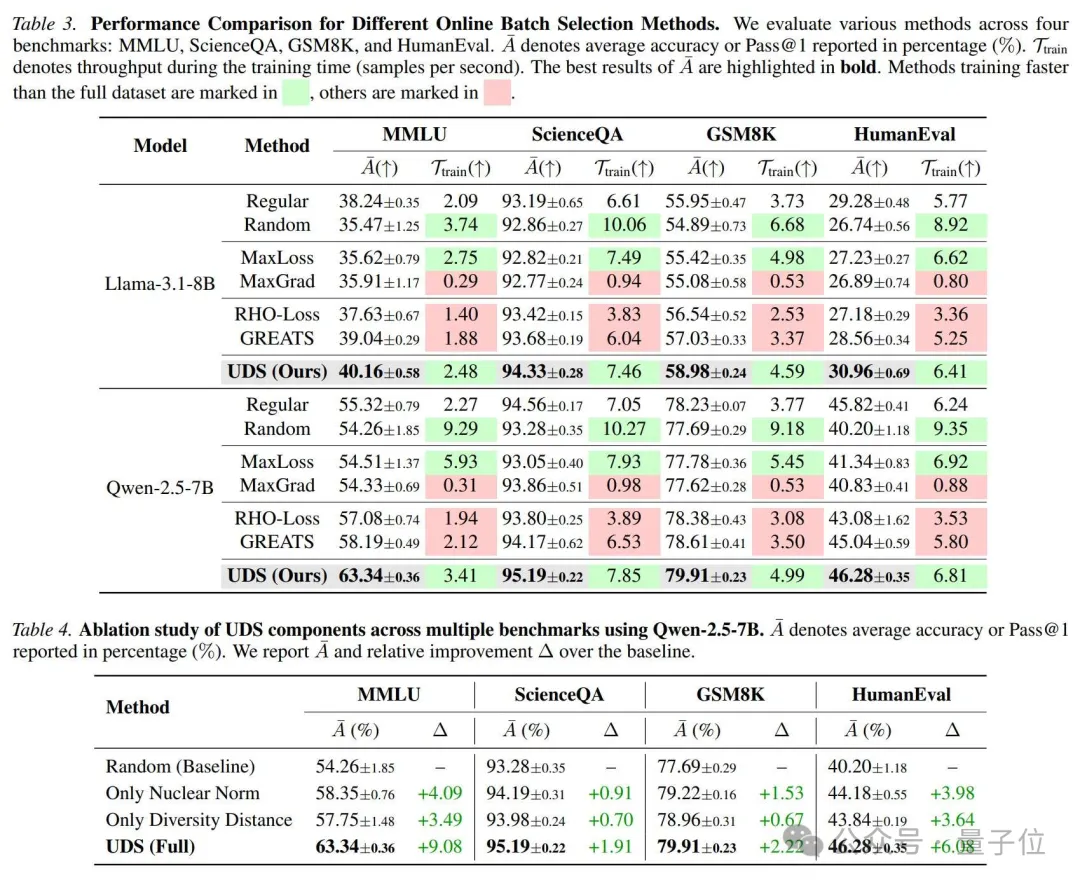
△主实验结果与消融实验截图:UDS在MMLU、ScienceQA、GSM8K、HumanEval上均取得最优结果,同时多数设置下训练吞吐量高于全量训练
消融实验:nuclear norm和diversity distance都不是摆设
为了验证UDS的两个核心组件是否真的有用,论文做了消融实验。
结果显示,只使用nuclear norm或只使用diversity distance,都能带来明显提升;但两者结合后的完整UDS表现最好。
以Qwen-2.5-7B为例:
在MMLU上,Random baseline为54.26%;只使用nuclear norm提升到58.35%,只使用diversity distance提升到57.75%,完整UDS进一步达到63.34%。
在HumanEval上,Random baseline为40.20%;只使用nuclear norm提升到44.18%,只使用diversity distance提升到43.84%,完整UDS达到46.28%。
这说明两种信号是互补的。
nuclear norm更关注单个样本内部是否有训练价值,diversity distance更关注当前样本是否与历史训练样本重复。只有把二者结合起来,才能同时实现“选得有用”和“选得不重复”。
超参数与数据规模:性能提升,但额外内存增长很小
论文还分析了投影维度d1、d2以及memory buffer大小M对性能和内存的影响。
结果显示,随着d1、d2和M增大,模型在MMLU上的平均准确率整体提升;但峰值内存只出现轻微增长。
这说明UDS的低维投影和memory buffer设计,并没有引入不可承受的额外内存负担。
在不同选择比例实验中,UDS也展现出稳定优势。随着每个batch中被选中的样本数量K增加,多数方法准确率都会上升;但UDS在较小K下就能达到峰值,并且在部分设置中超过全量训练。
这意味着:
小而精的训练子集,只要选择策略足够好,也能超过“全都训练一遍”。
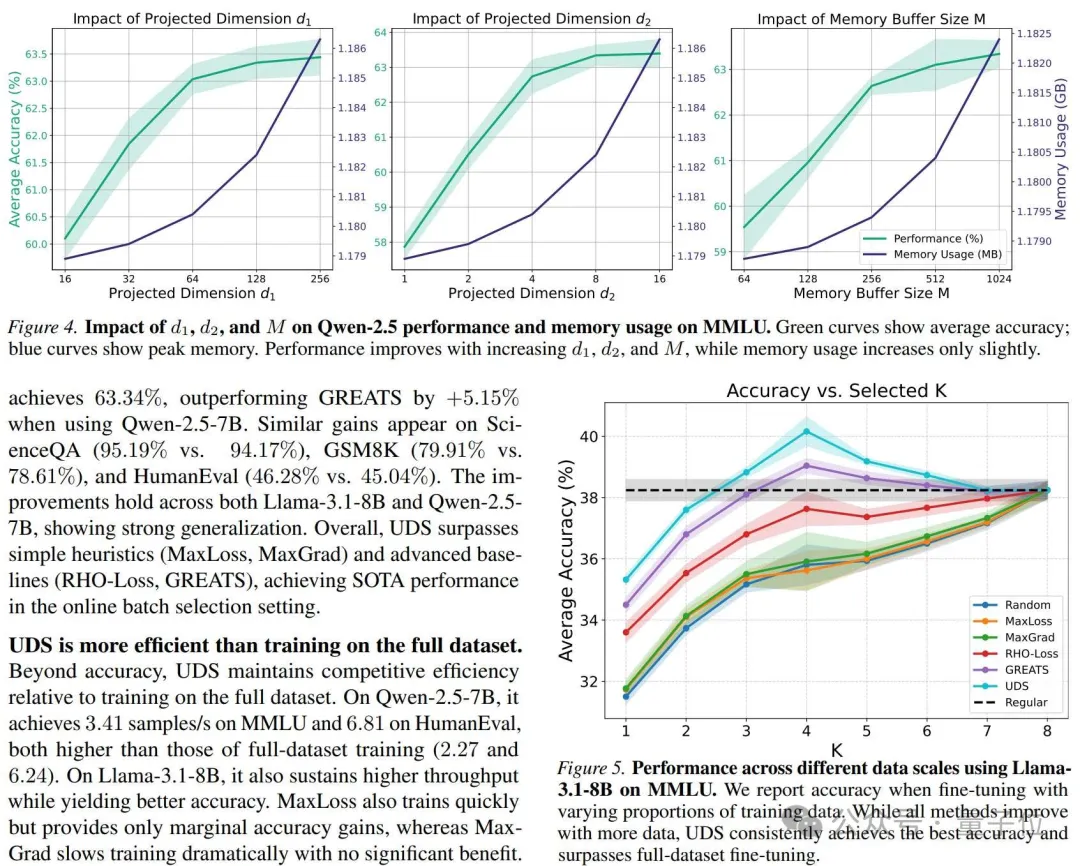
△投影维度、memory buffer与数据选择规模实验截图:UDS在提升性能的同时,仅带来很小额外内存增长
更多实验:从LoRA到全参微调,从长链推理到OOD
除了主实验,论文还在附录中补充了多组验证,进一步证明UDS的鲁棒性。
在更大batch size(B=16)下,UDS仍然在Qwen-2.5-7B上取得最高结果:MMLU为62.71%,ScienceQA为95.08%,GSM8K为79.38%,HumanEval为45.98%。
在全参数微调设置下,UDS同样保持优势:MMLU为63.27%,ScienceQA为95.06%,GSM8K为78.26%,HumanEval为48.44%。
在Qwen-2.5-7B-Instruct上,UDS也超过其他方法:MMLU为53.86%,ScienceQA为95.56%,GSM8K为76.80%,HumanEval为45.75%。
对于更长上下文推理,论文在MATH数据集上将最大序列长度设为2048。UDS取得46.27%,高于Regular的45.89%和GREATS的45.66%。
在OOD测试中,模型在GSM8K上训练,并在MATH500、AMC23上评估。UDS在GSM8K、MATH500、AMC23上分别达到79.91%、42.56%、26.38%,均为最佳。
论文还与离线数据选择方法FisherSFT做了比较。在相同数据选择比例下,UDS在MMLU、ScienceQA、GSM8K、HumanEval上分别达到63.34%、95.19%、79.91%、46.28%,全面高于FisherSFT的57.85%、94.02%、78.35%、43.87%。
这些结果共同说明,UDS并不是只在某个单一设置下有效,而是能够泛化到不同batch size、不同微调方式、指令模型、长推理任务和分布外测试中。
让SFT从“全量喂数据”走向“动态挑数据”
这项工作的核心价值,不只是提出了一个新的采样公式,而是重新强调了SFT中一个很现实的问题:
训练效率不只取决于模型和算力,也取决于每一步到底把哪些数据拿来更新参数。
过去,在线batch选择常常只关注样本难度或loss。UDS则把视角扩展到utility和diversity的联合建模:既看样本是否有用,也看样本是否重复。
更重要的是,它直接利用前向传播已有的logits信号,不需要额外验证集、参考模型,也避免了昂贵的样本级梯度计算。
从更长远看,UDS代表了一类更实用的数据选择方向:让大模型训练不再只是“堆数据、堆算力”,而是让训练过程本身具备更强的数据判断能力。
对于SFT来说,这意味着我们有机会用更少的样本、更低的时间成本,获得更强的模型表现。
主要作者
邹鹤鸣,季向阳教授团队博士,研究范围覆盖大模型高效后训练、持续学习与脑启发智能,致力于提升多轮交互式智能体在RL后训练中的采样–反馈效率与决策信用分配,抑制自演进中的灾难性遗忘,并基于脑启发机制探索更省算力的前沿学习范式。在ICML、NeurIPS、ICLR等国际顶级会议以一作/共一发表多篇论文,工作贯穿算法创新与工程落地全栈优化,目前腾讯混元大模型团队科研实习生。