图神经网络能理解多少种图?
2026-05-20 22:25:21 · chineseheadlinenews.com · 来源: Woke Flow涌现
关键词: 图神经网络 · GNN · MPNN · GCN · GAT · GIN · 消息传递 · 置换不变性 · Weisfeiler-Leman · 表达力上限 · 过平滑
目录
? 一、为什么图不能直接喂给 MLP
? 二、核心直觉:每个节点通过"传话"学习
? 三、MPNN:消息传递的统一框架
? 四、GCN——用 MPNN 的眼光重新审视
? 五、GAT——在图上做注意力
? 六、GIN——消息传递的表达力上限
? 七、消息传递的三个边界
? 八、1968 年的墙
图神经网络(GNN)这几年在分子性质预测、药物发现、推荐系统、交通预测等领域拿下了一连串的 SOTA。它的核心机制叫消息传递——每个节点和邻居交换信息,迭代几轮后,每个节点的表示就编码了局部乃至全局的图结构。
但一个更根本的问题很少被问到:消息传递到底能"看懂"多少种图? 存不存在两张结构不同的图,无论你怎么设计消息传递的细节,GNN 都无法区分它们?
答案是存在的。而且这个上限不是某个具体模型的工程缺陷——它是消息传递这种计算范式的数学宿命,早在 1968 年就被一个完全不相关的算法划定了。
这篇文章要做的事情:从图数狙酞什么特殊讲起,建立消息传递的统一框架(MPNN),逐公式拆解三个最重要的 GNN 变体——GCN、GAT、GIN——看它们在设计上做了什么不同的选择,最终撞上那堵 1968 年的墙。
如果你读过矩阵微积分温和指南的第五篇“拉普拉斯的回响”,那篇文章从梯度和热扩散的角度拆过 GCN 的数学内核。这篇文章拉开镜头,不再只看 GCN 一个架构,而是看整个消息传递的设计空间和理论边界。没读过也完全不影响~
一、为什么图不能直接喂给 MLP
先看一个简单的例子。4 个节点的图:


二、核心直觉:每个节点通过"传话"学习
想象一个场景。五个人站在一张图上,每个人只能跟自己直接相连的邻居说话。一开始每个人只知道自己的信息——名字、年龄、职业。
第一轮: 每个人问邻居"你是谁?",得到邻居的信息。现在每个人不仅知道自己的特征,还知道"我的邻居长什么样"。
第二轮: 每个人再问邻居"你上轮听到了什么?"。邻居上轮已经收集了它们的邻居的信息,所以这一轮你间接听到了两跳之外的消息。

三、MPNN:消息传递的统一框架
2017 年,Gilmer, Schoenholz, Riley, Vinyals & Dahl 在一篇 ICML 论文 "Neural Message Passing for Quantum Chemistry" 中提出了 MPNN(Message Passing Neural Network) 框架,把几乎所有图神经网络统一到了同一个数学结构下。

第二步:聚合消息(Aggregate)

第三步:更新节点表示(Update)

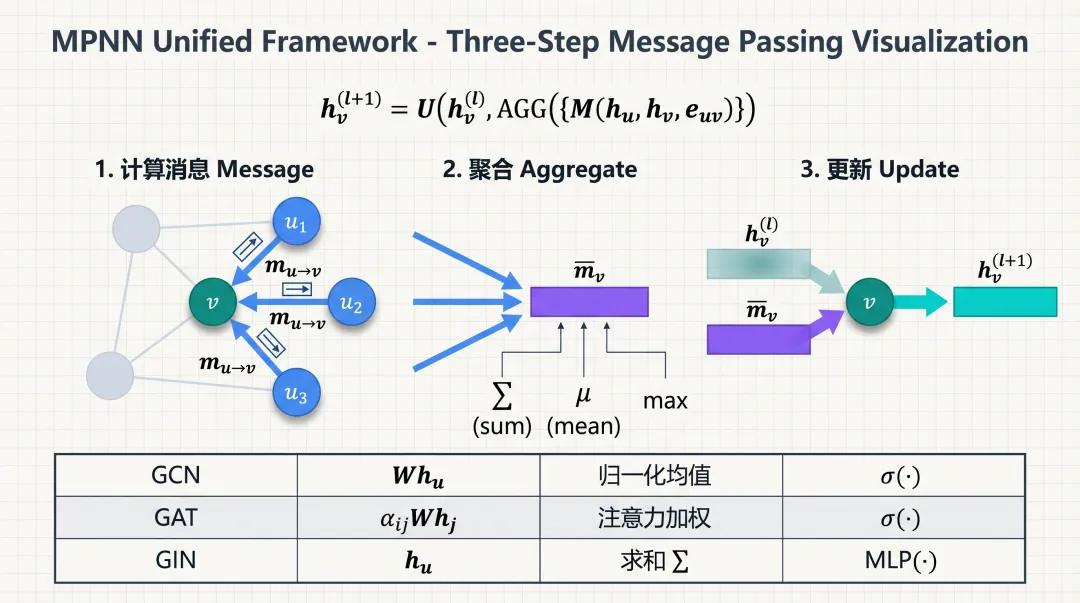
MPNN 统一框架:消息→聚合→更新三步流程,以及 GCN/GAT/GIN 各自的选择
消息传递之后:从节点表示到最终输出



四、GCN——用 MPNN 的眼光重新审视


五、GAT——在图上做注意力
GAT(Graph Attention Network) 来自 Veli?kovi?, Cucurull, Casanova, Romero, Liò & Bengio 的 "Graph Attention Networks"(ICLR 2018),把注意力的思想引入了图。
GCN 的权重由度数决定——固定的、不可学习。GAT 的权重由数据决定——模型根据节点的特征内容,学会判断"这个邻居对我重要不重要"。



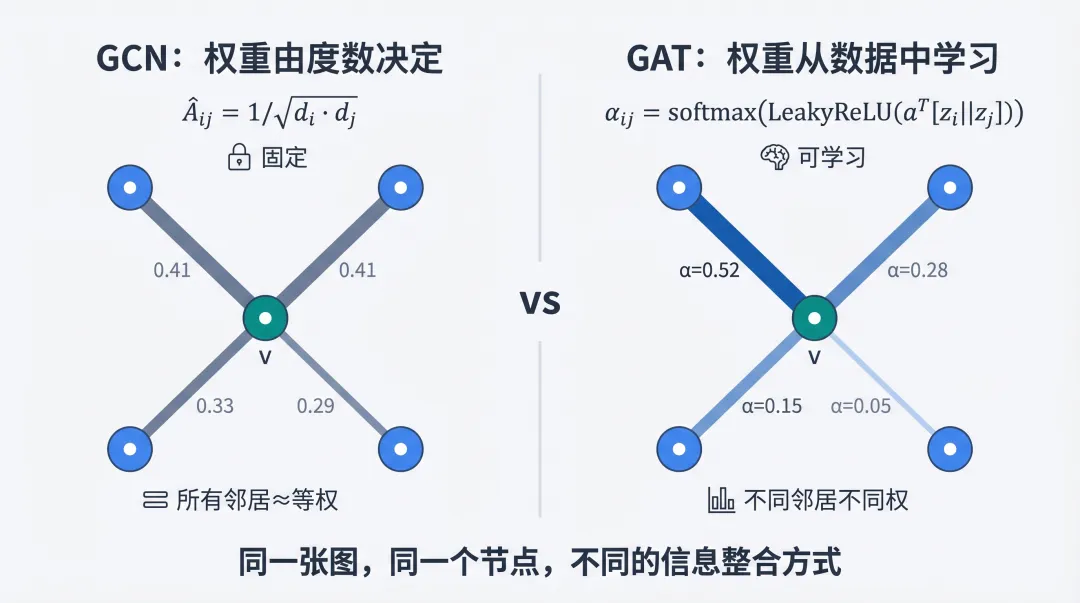
GCN vs GAT:同一张图上,固定权重与学习权重的对比
六、GIN——消息传递的表达力上限
GCN 用归一化均值聚合,GAT 用注意力加权聚合。但一个更根本的问题是:消息传递到底能区分多少种图?
Xu, Hu, Leskovec & Jegelka 在 "How Powerful are Graph Neural Networks?"(ICLR 2019)中给出了一个精确的答案。这个答案揭示了"聚合函数"这个看似无关紧要的选择,实际上决定了整个模型的理论天花板。
Weisfeiler-Leman 测试
先说一个与神经网络无关的经典算法:1-WL 测试(Weisfeiler-Leman test),由 Boris Weisfeiler 和 Andrei Leman 在 1968 年提出。它是图论中判断两个图是否"结构相同"(同构)的经典方法。
1-WL 的流程和消息传递惊人地相似:
1. 给每个节点一个初始"颜色"(基于节点特征,比如度数)
2. 每轮迭代:每个节点收集所有邻居的颜色,把(自己的颜色 + 邻居颜色的多重集)做一次哈希,得到新颜色
3. 重复,直到颜色分配不再变化
4. 如果两个图最终的颜色集合不同,它们一定不同构

这篇论文证明了一个核心定理:
任何 MPNN 的图区分能力,不超过 1-WL 测试。
换句话说,1-WL 是消息传递的理论天花板。如果 1-WL 区分不了两个图,任何 MPNN 也区分不了。
那么反过来:能不能设计一个 MPNN,达到 1-WL 的天花板?
答案取决于聚合函数的选择。
为什么聚合方式决定表达力
我们需要回答的核心问题是:聚合函数能不能无损地区分不同的邻居多重集?
先看三组反例,每组都让某种聚合方式翻车。


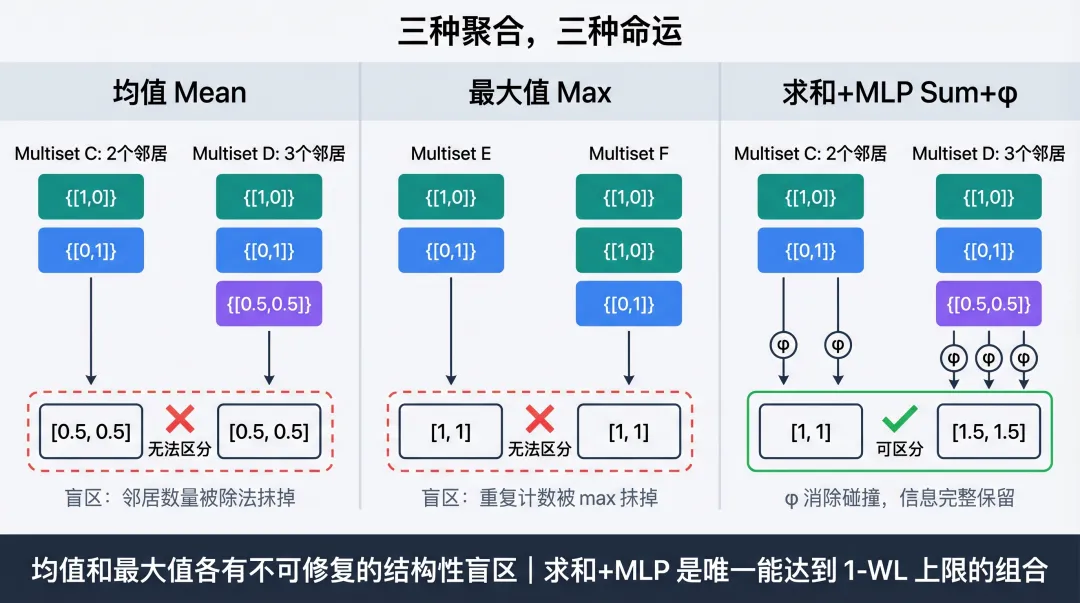
三种聚合,三种命运:均值丢失邻居数量,最大值丢失重复计数,求和+MLP 可区分



七、消息传递的三个边界
MPNN 强大,但不是万能的。理解它的边界,才能理解后续更复杂的设计为什么存在。
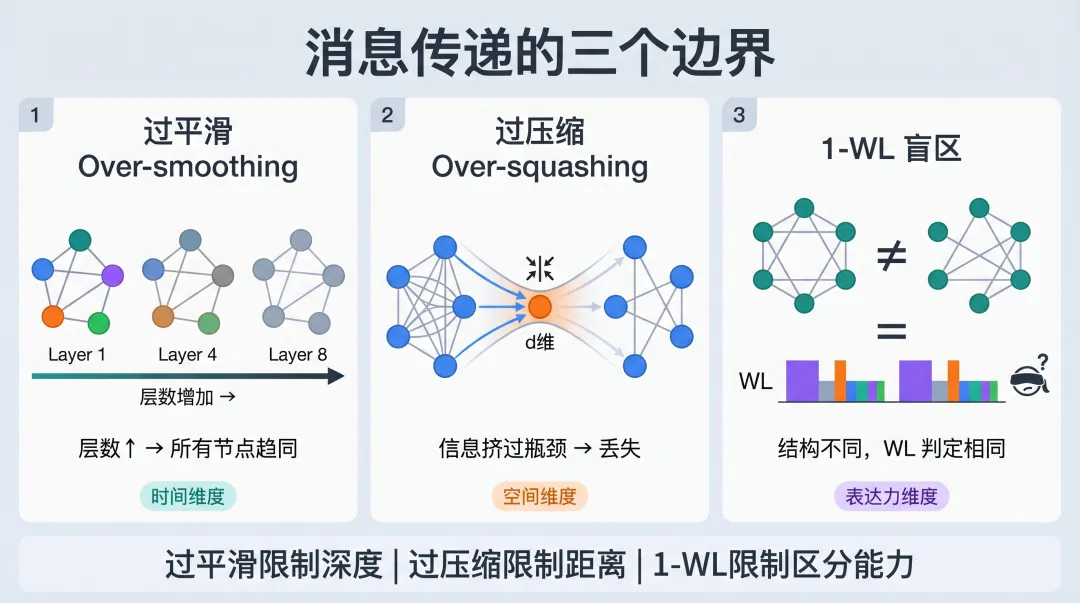
消息传递的三个边界:过平滑限制深度,过压缩限制距离,1-WL 限制区分能力


八、1968 年的墙
回到开头的问题:图神经网络能理解多少种图?
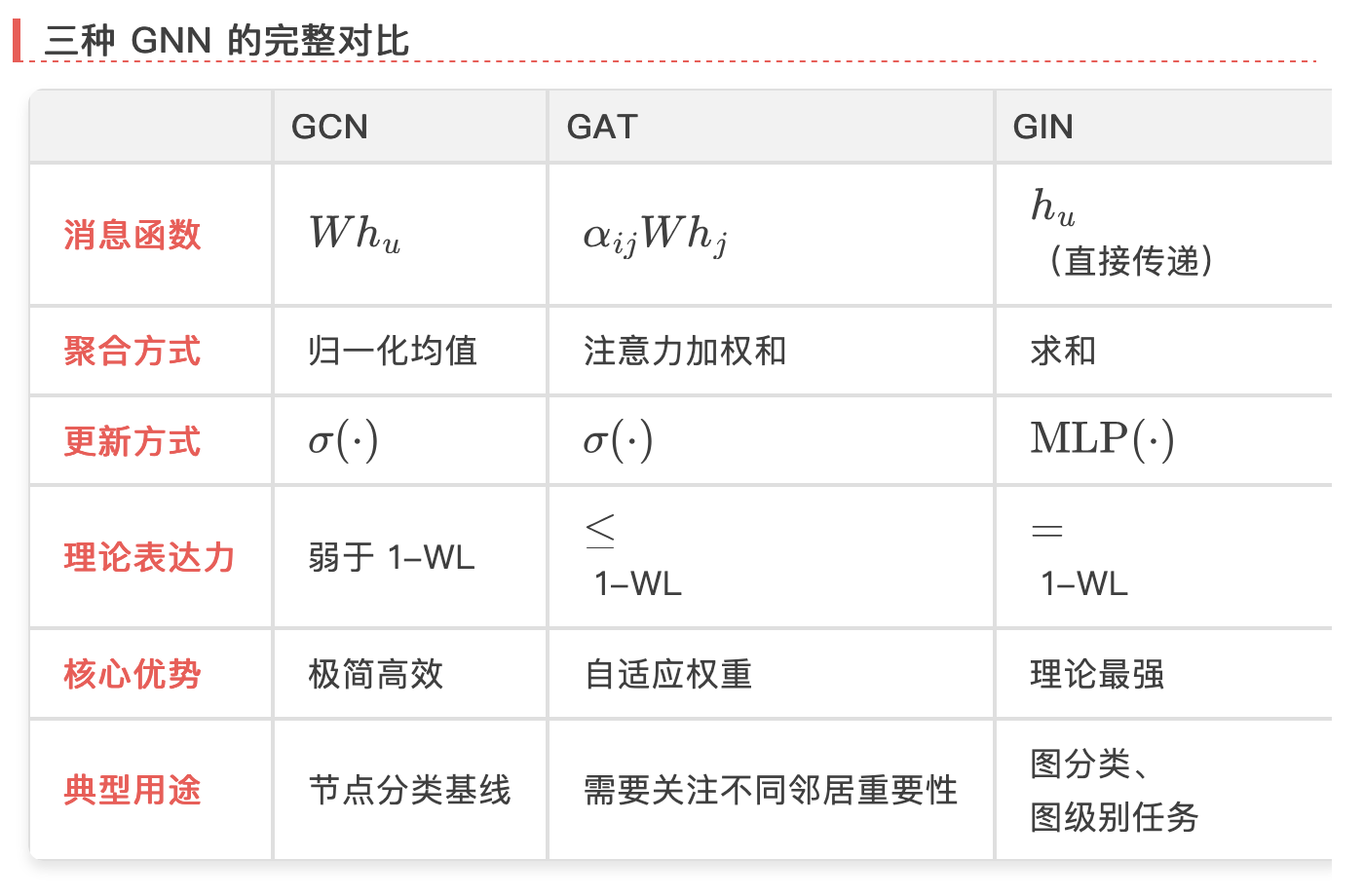
我们现在有了精确的答案。消息传递的核心是三个函数的选择——消息怎么算、怎么聚合、怎么更新。GCN 选了最简单的(归一化均值 + 线性变换),GAT 让聚合权重变得可学习(注意力),GIN 追求理论最优(求和 + MLP)。
但无论怎么选,所有 MPNN 的区分能力都被 1-WL 测试锁死——一个 1968 年由 Weisfeiler 和 Leman 提出的、和神经网络毫无关系的图论算法。GIN 触到了这个天花板,但没有任何 MPNN 能突破它。再加上过平滑和过压缩,消息传递的能力边界比很多人想象的要窄。
这不是说 GNN 没用——在它能力范围内,消息传递是图上最自然、最高效的计算范式。但理解边界在哪里,才能知道什么时候该用它,什么时候需要别的东西。
而在图上做计算,消息传递也不是唯一的范式。在 GNN 出现之前很久,概率推理领域就有一个经典算法——置信传播(Belief Propagation)。它也让节点和邻居交换信息、迭代更新,但目标不同:GNN 学的是节点的向量表示,置信传播算的是节点处于每个状态的概率。一个关注"特征应该是什么",一个关注"概率应该是多少"。
下一篇,我们来看这个更古老的"图上传话"——不是为了学表示,而是为了算概率。
参考文献
[1] Justin Gilmer, Samuel S. Schoenholz, Patrick F. Riley, Oriol Vinyals, George E. Dahl. Neural Message Passing for Quantum Chemistry. ICML 2017. arXiv: 1704.01212
[2] Thomas N. Kipf, Max Welling. Semi-Supervised Classification with Graph Convolutional Networks. ICLR 2017. arXiv: 1609.02907
[3] Petar Veli?kovi?, Guillem Cucurull, Arantxa Casanova, Adriana Romero, Pietro Liò, Yoshua Bengio. Graph Attention Networks. ICLR 2018. arXiv: 1710.10903
[4] Keyulu Xu, Weihua Hu, Jure Leskovec, Stefanie Jegelka. How Powerful are Graph Neural Networks? ICLR 2019. arXiv: 1810.00826
[5] Boris Weisfeiler, Andrei Leman. The Reduction of a Graph to Canonical Form and the Algebra Which Appears Therein. Nauchno-Technicheskaya Informatsia, Seriya 2, No. 9, pp. 12–16, 1968. 英文译本: iti.zcu.cz/wl2018/pdf/wl_paper_translation.pdf