浙大&微软3000条纯文本让模型理解3D
2026-05-16 01:25:17 · chineseheadlinenews.com · 来源: 量子位
视频生成有个老毛病,镜头一动就“穿帮”,终于有了靠谱的解法。
浙大联合微软亚洲研究院最新提出的World-R1,不改架构、不要3D数据,纯靠强化学习就让视频生成模型学会了“理解”三维世界。

所以,AI视频为啥总穿帮?
现在的视频生成模型,画面精美是精美了,但有个致命伤:不懂三维。
你让镜头转个弯,建筑就扭了;推进去看个近景,物体就消失了。
本质上,这些模型只是在二维像素层面做统计拟合,根本不理解眼前的世界是个三维空间。
以前的解法呢?往模型里硬塞3D模块,但代价是推理成本飙升、泛化能力变差,而且只能做图生视频,文生视频根本搞不定。
World-R1 的思路:不改架构,靠 RL“唤醒”
World-R1 的出发点很简单:
预训练的视频模型里面已经有 3D 知识了,只是“沉睡”着。用强化学习把它叫醒就行。
具体怎么操作?三板斧。
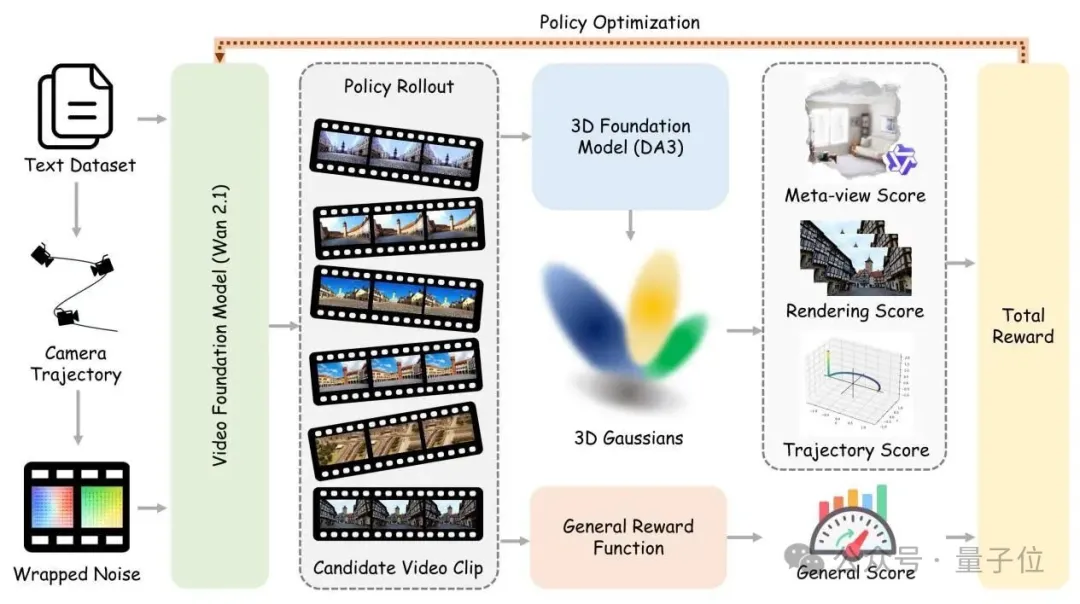
第一斧:把相机轨迹“藏进”噪声
别人控制相机运动,需要额外训练一个控制网络。
World-R1说:不需要。
它从文字里提取运动关键词(比如“push in”“orbit left”),生成相机轨迹,然后通过光流投影,直接把运动信息编码进扩散模型的初始噪声里。
一行代码不改,一个参数不加,相机就能跟着文字走。
第二斧:让3D模型当“裁判”
RL的核心是奖励函数。
World-R1设计了一套四维复合奖励:元视角评分,用Depth Anything 3把视频“抬”成3D高斯溅射,再从一个完全不同的角度去看。
正面看没问题?换个角度可能就“露馅”了。
用Qwen3-VL当评审员,专门抓“纸片人”。
重建保真度,3D重建完再渲染回去,跟原视频逐像素比对。
轨迹对齐度,看生成的相机运动有没有老实听话。
通用画质,HPSv3 打分,确保画面不变丑。

整套奖励通过**Flow-GRPO框架优化。
第三斧:让模型“又硬又软”
纯追求3D一致性会出问题:行人不会走路了,旗帜不会飘了,整个世界像冻住了一样。
World-R1的解法是周期性解耦训练:正常阶段,用完整奖励猛练几何一致性;
每100步,切换到“动态专场”,只用通用奖励在高动态数据上训练。
效果直接建筑稳如泰山,旗帜照样飘。
3000条纯文本,没有一帧视频
你可能会问:训练数据从哪来?
答案是:不要视频,不要 3D 资产,纯文本就够了。
研究团队用Gemini生成了约3000条高质量场景描述,涵盖峡谷、城市、深海、蘑菇森林等各类场景,按相机运动难度分了三级。
模型就这样在“纯想象”中,学会了真实世界的物理规律。
实验数据
基于Wan 2.1训练了两个版本:World-R1-Small(1.3B)和 World-R1-Large(14B)。
3D一致性
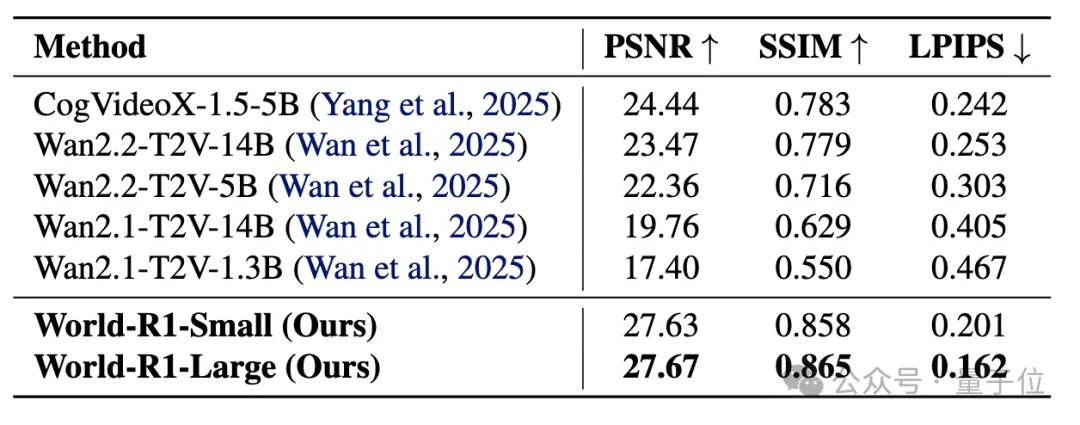
Small版比基线PSNR涨了10.23 dB,Large 版涨了7.91 dB。LPIPS 从0.467降到0.201,几何幻觉被干掉了大半。
画质不降反升
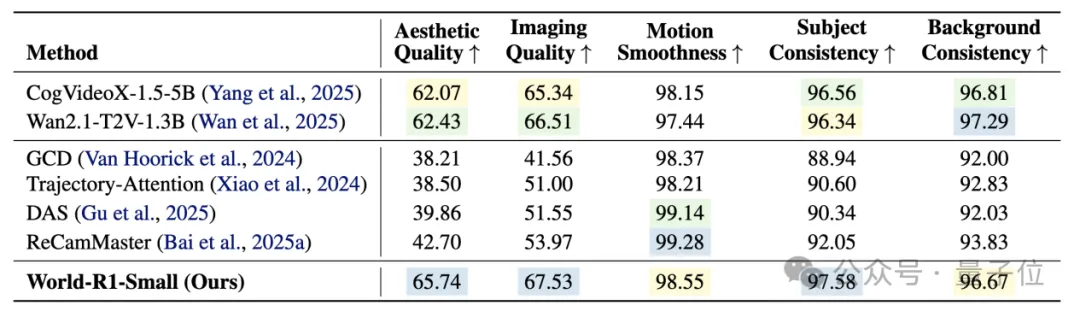
在VBench上,World-R1-Small美学质量65.74、成像质量67.53,全面超越基线Wan 2.1-1.3B。
而那些装了额外相机控制模块的方法(ReCamMaster、DAS),美学质量只有38~42分。
3D增强了,画质也更好了,鱼和熊掌兼得!
眼见为实

3D重建的点云也能看出差距:基线模型的重建像一堆散沙,World-R1的像一座真实的建筑。
消融:每一刀都切在要害上
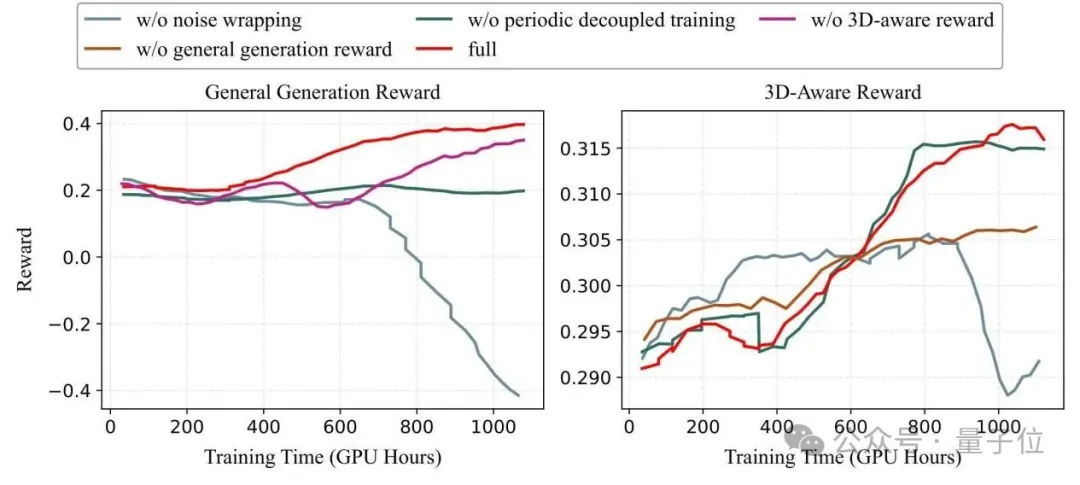
消融实验的结论很清晰:去掉3D感知奖励,几何一致性直接崩盘;
去掉通用生成奖励,画面美学肉眼可见地劣化;
去掉噪声包裹的隐式相机控制,收敛速度慢了一倍;
去掉周期性解耦训练,动态场景的生成能力几乎全废。
四个组件环环相扣,缺一不可。
World-R1让视频模型“理解”三维世界,不必推倒重来——
只需用正确的奖励信号,唤醒它已有的空间感知。