DeepSeek-V4:重新设计记忆
2026-04-25 21:25:31 · chineseheadlinenews.com · 来源: AGI Hunt公众号
DeepSeek V4 发布后,我因为太忙了一直没空详细测试和看技术报告,但毕竟是源神一年半之后再次的重磅更新,今天多少得补上一个:


DeepSeek-V4 性能与效率总览
也就是说:同样一块 GPU,V3.2 时代只能同时服务 4 个长上下文用户,而 V4 能服务大约 40 个。
这可以说是 DeepSeek 再一次的非渐进式优化,把长上下文推理的成本进行了改写。
01
Pro 和 Flash
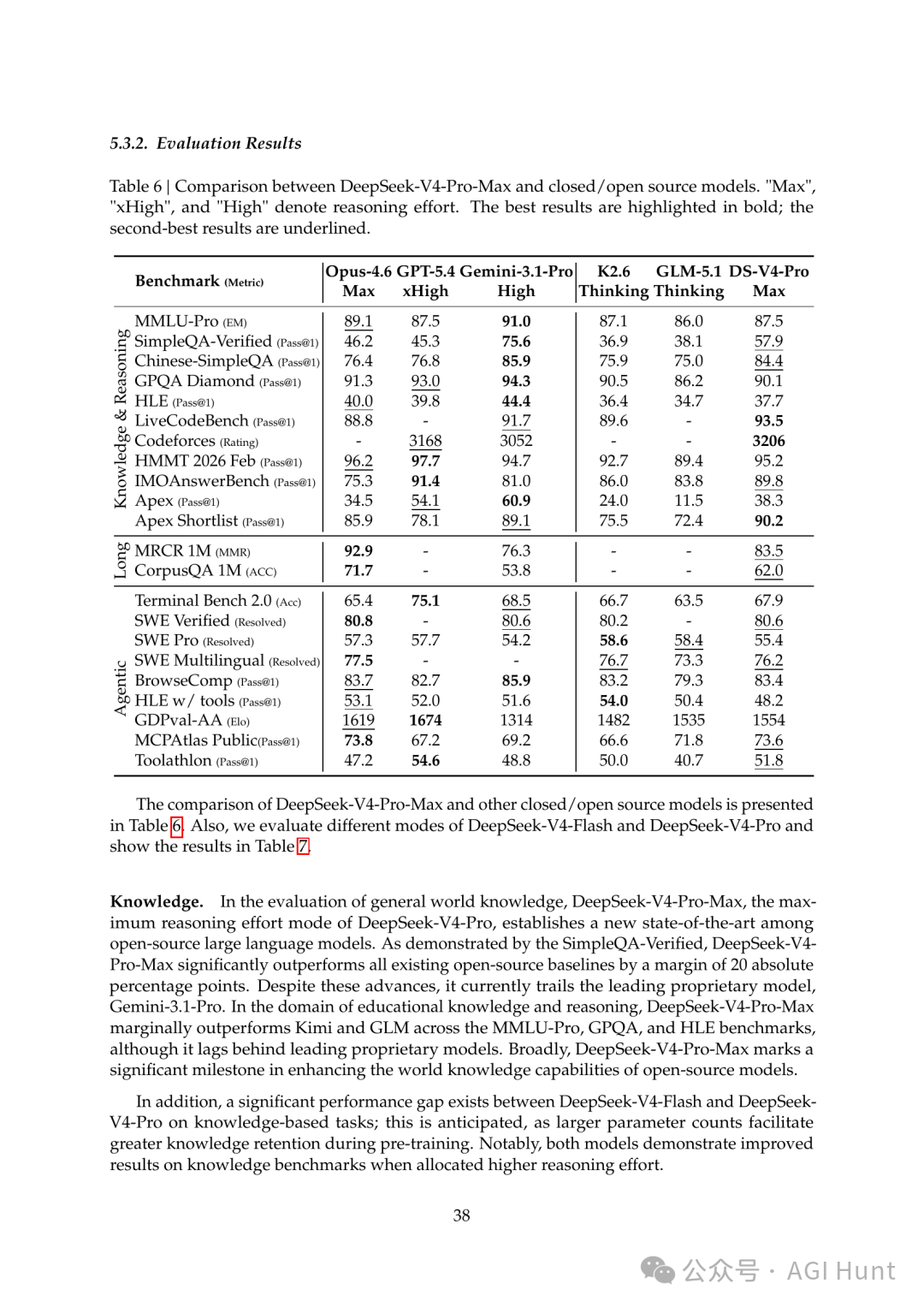
DeepSeek-V4 评测对比
技术报告很谦逊,直说了自身的不足:在推理能力上,V4 的发展轨迹“落后前沿闭源模型大约 3 到 6 个月”。知识评测上,也还追不上 Gemini-3.1-Pro。
02
怎么压的
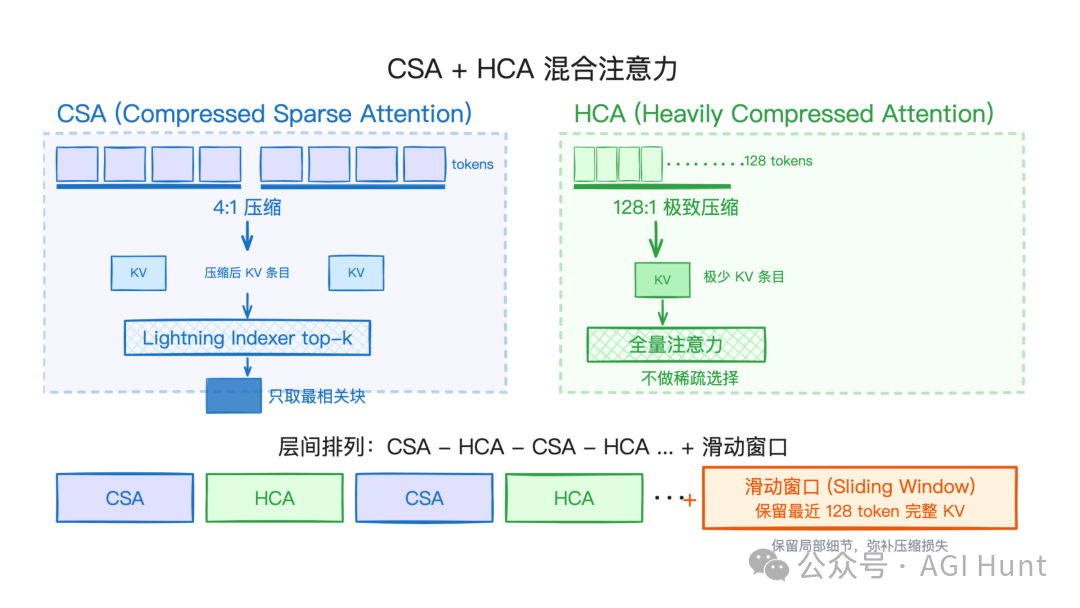
CSA + HCA 混合注意力机制
CSA(压缩稀疏注意力),每 4 个 token 的 KV 缓存压成 1 个。压完之后还有一步:用一个叫 Lightning Indexer 的轻量索引器,快速给所有压缩块打分,只挑 top-k 个最相关的块来看。既省显存,也省计算。
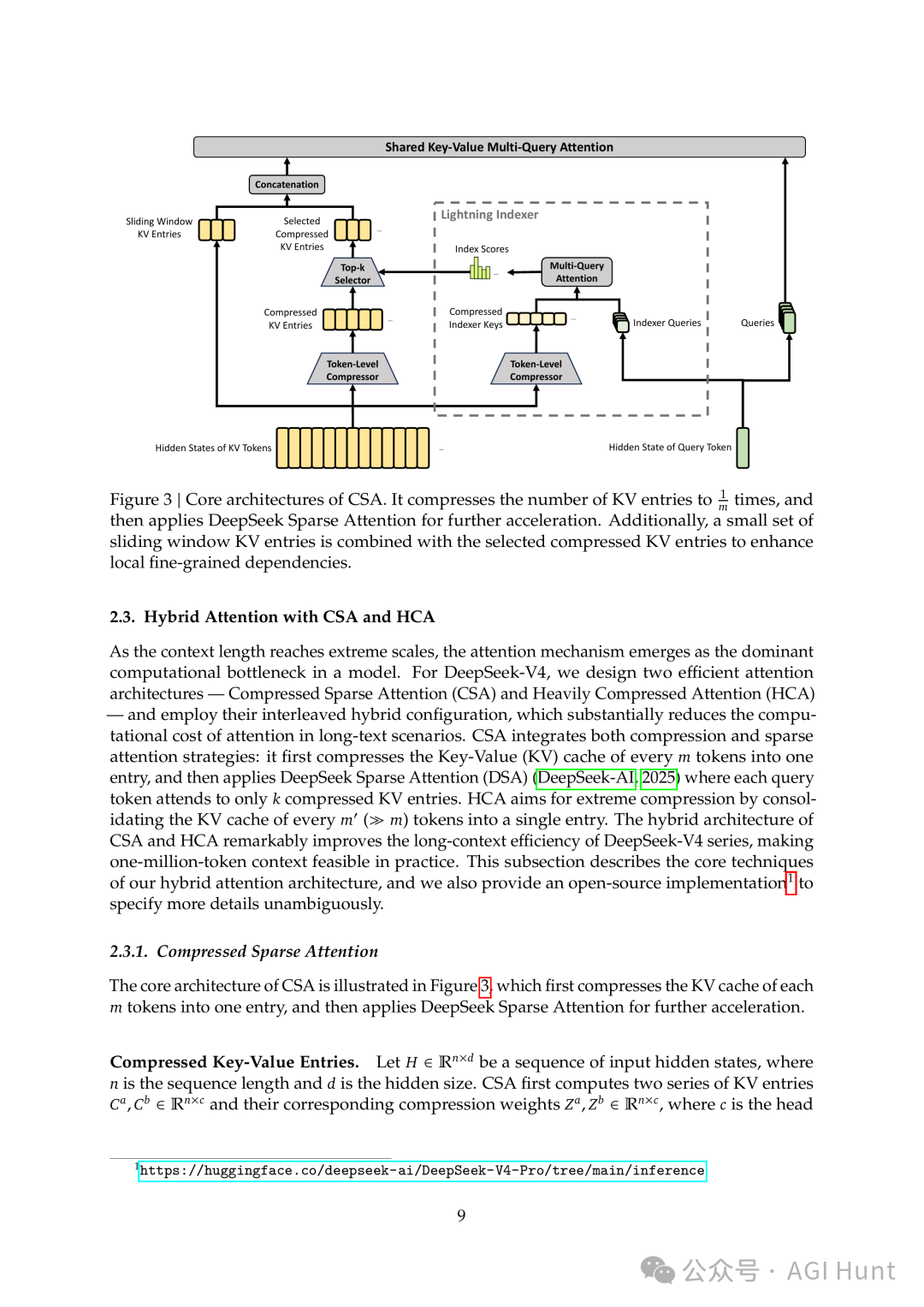
CSA 架构
HCA(重度压缩注意力),则压得更狠,每 128 个 token 压成 1 个。不过因为压缩太猛了,HCA 就不做稀疏筛选了,对所有压缩后的条目做完整的注意力计算,确保不遗漏。

HCA 架构

压了多少
算一笔账

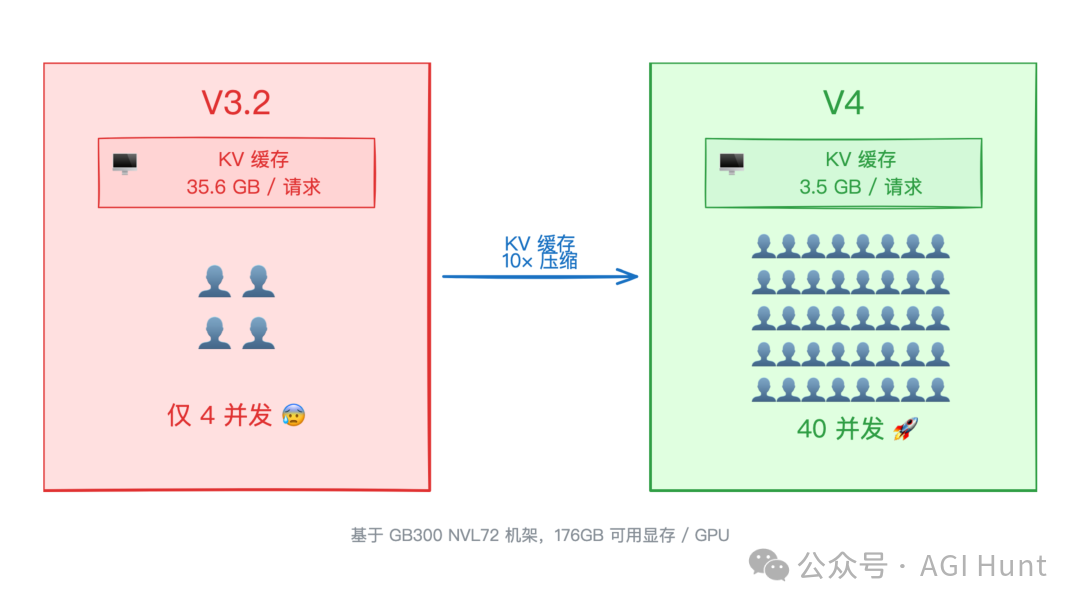
V3.2 vs V4 KV 缓存与并发对比

更稳的残差
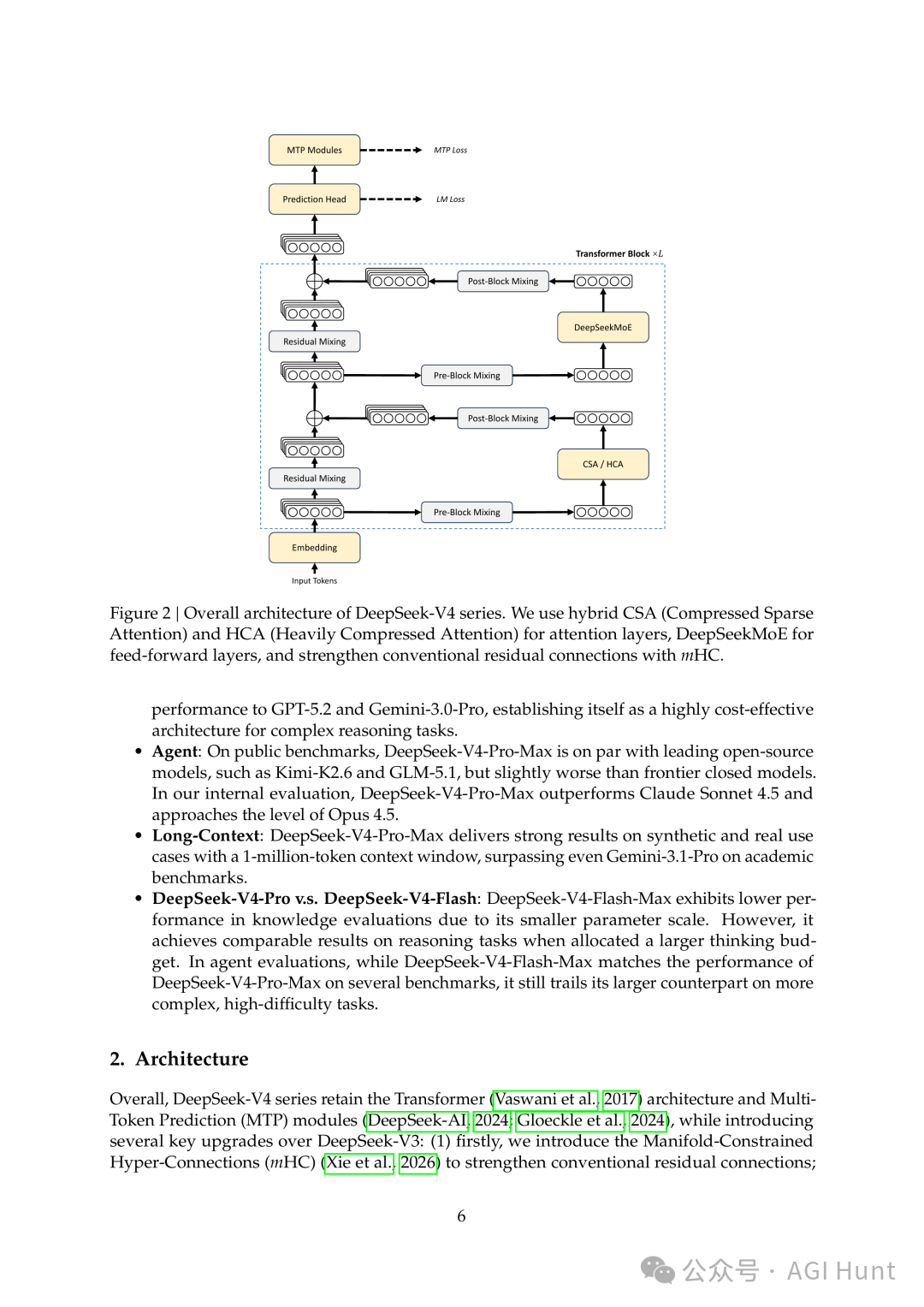
V4 整体架构

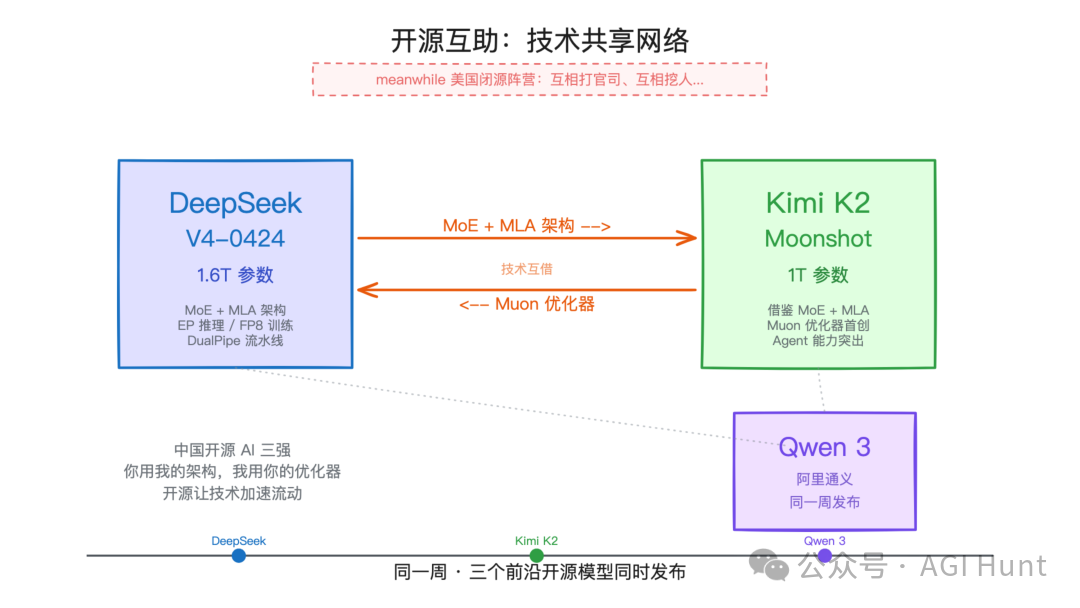
借来的优化器
V4 第一次在万亿参数的模型上用了 Muon优化器,这个优化器来自 Moonshot 团队(也就是最新发布了 Kimi K2.6 背后的公司)。
传统的 AdamW 优化器是逐个参数更新的。Muon 不一样,它把参数当成矩阵来处理,用一种叫 Newton-Schulz 迭代的方法对更新方向做正交化,让训练更稳定、收敛更快。
开源互助关系

训练时的 FP4

训练踩过的坑

虽然它们被证明有效,但其底层原理仍未被充分理解。
这也属于是,DeepSeek 的一贯风格了。
09
怎么做后训练
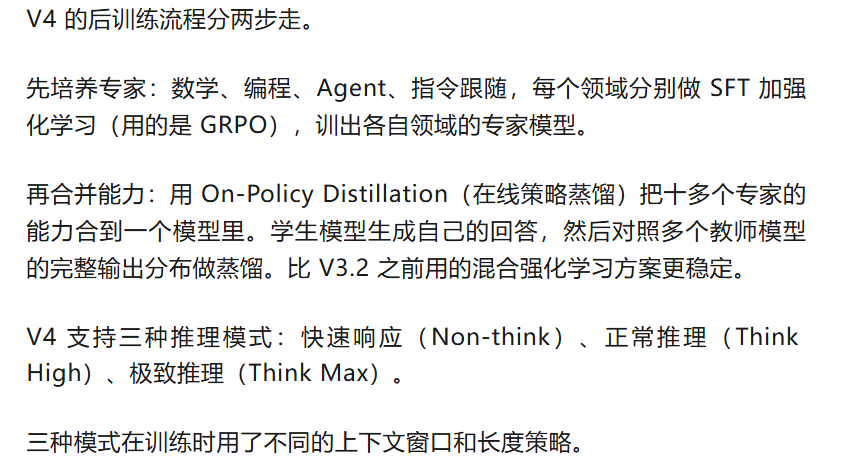
10
华为算力
技术报告里有一句话是:“ 由于高端算力资源受限,Pro 版本目前的服务能力十分有限。待 950 超级节点在今年下半年大规模上线后,Pro 的价格预计将大幅下调。这里的 950 超级节点,正是指华为昇腾 950PR 芯片组成的集群。技术报告的基础设施部分也提到,他们的 EP 方案已经在“英伟达 GPU 和华为昇腾 NPU 平台上都做了验证”。
V4 的架构设计,尤其是把 KV 缓存压到原来十分之一这件事,某种程度上降低了对显存带宽和容量的要求,也就让性能相对弱一些的国产芯片有了运行前沿模型的可能。
11
仍有差距
Artificial Analysis 的完整评测揭示了一些值得关注的地方。
V4 Pro 的幻觉率到了 94%,也就是当它不知道答案的时候,它几乎总是会编一个出来。V4 Flash 更高,96%。
在 token 消耗上,V4 Pro 跑完 Artificial Analysis 的智能指数评测用了 1.9 亿 output token,V4 Flash 更是 2.4 亿。虽然单价便宜,但总成本($1,071)其实比 Kimi K2.6($948)还贵一些。
在整体智能指数上,V4 Pro 得分 52,开源里排第 2,但跟闭源前沿(Claude Opus 4.7、GPT-5.5)还是有差距的。V4 Flash 得分 47,大致在 Claude Sonnet 4.6 的水平。
技术报告自己也承认了一些局限。架构因为保留了太多“初步验证过的组件”而显得“比较复杂”。未来的目标是“精简到最核心的设计,在不牺牲性能的前提下更优雅”。
DeepSeek 内部也做了一个调查(85 人),问 V4-Pro 能不能作为日常编程的默认模型。52% 的人说可以,39% 倾向于可以,不到 9% 说不行。
主要的吐槽是,偶尔犯低级错误、对模糊指令容易误解、有时候想太多。
12
本地能跑
V4-Flash 的 13B 激活参数意味着,它应该是第一个能在消费级硬件上不做压缩直接跑的前沿模型了。
实测数据:4 块 RTX 6000s,38.6 tok/s 解码速度,首 token 延迟不到 1 秒,能撑 8 路并发和 40 万 token 上下文。
256GB 的 Mac M3 Ultra 也能跑,Ollama等开源推理框架也于第一时间上架了云端版本。
13
后续方向
V4 最值得琢磨的,也许并不在某个具体的技术创新上。
当 100 万 token 的 KV 缓存从 35.6GB 压到 3.5GB,更多的公司就能在自己的硬件上部署长上下文的 Agent 应用,更多的场景也就能用上真正的百万 token 窗口了,不再只是“技术上支持但实际用不起”。
技术报告的结尾,透露了 DeepSeek 后续的研究方向:更稀疏的 Embedding 模块、低延迟架构、多模态,以及在线学习范式。