AI4S设计的新抗生素通过湿实验
2026-04-21 17:25:16 · chineseheadlinenews.com · 来源: 量子位
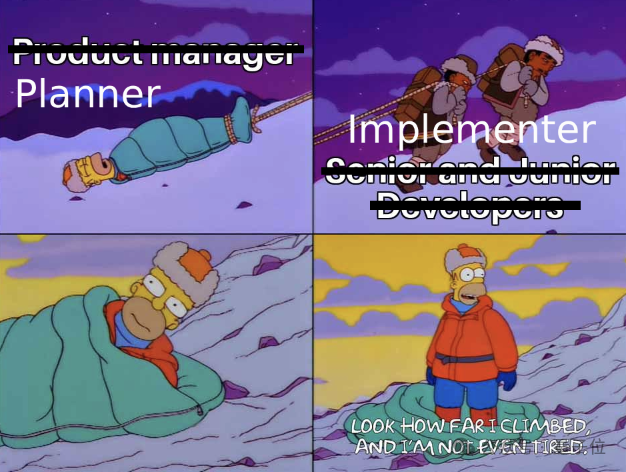
AI 搞计算预测效果绝佳,一到湿实验就现原形?
这是 AI for Science 领域一直以来面临的巨大难题 —— 虽然有各种 AI 模型,一直以来刷新各大评测榜单,但专业科学家却能一眼看出它生成的东西进不了实验室,换而言之 “没什么用”。
就算有 AI 侥幸 “蒙” 出一两个可用成果,生成的过程也是完全黑盒,无法复现。
现在,来自十余所顶尖机构的研究团队,终于教 AI 学会了像人类科学家一样搞科研:主动根据测试效果,修改生成目标,和实验室 “100% 对接”。

这个名叫 SAGA 的新 AI(Scientific Autonomous Goal-evolving Agent),给人类提出的抗生素需求上加了一行代谢稳定性评分器的代码后,生成的先导化合物竟然同时通过了杀菌和安全性的双重体外验证,效果连专业科学家都直呼 “合理,一开始没想到”。
不仅如此,在化学、材料等 4 个其他领域,SAGA 也同样获得了研究人员的肯定。
有网友评价 SAGA:“不仅解决问题,还在游戏中重新定义了游戏规则。”
目前,相关代码已经在 GitHub 上开源,据论文一作杜沅岂介绍,跑一次的成本大约在 100 美元左右,出来的成果 “一定是看起来能用的”。
这样的效果,究竟是怎么实现的?
教 AI 科学家主动 “快慢思考”
在 SAGA 之前,主流 AI Scientist 搞研究大多 “靠运气”—— 人类输入指令,AI 输出结果,至于中间做了什么,不可变也不可测。
相比传统 AI Scientist 的全自动 “黑盒”,SAGA 采用了一套不仅能主动自我评估、还能被人类随时介入的双层思考机制。
这个框架的灵感来自于诺奖得主丹尼尔?卡尼曼(Daniel Kahneman)的《Thinking, Fast and Slow》。
卡尼曼认为,人类大脑分为两个系统,System 1 凭直觉、反应快,但也容易犯错,System 2 靠逻辑、思考慢,但更具深度。
这也是 SAGA 两层框架的基本原理。
它的内层是一个传统优化器(Optimizer),相当于 AI 的 “快速直觉”,一旦给定目标函数,就能快速用遗传算法或强化学习跑优化,生成候选分子、序列、材料后,反复迭代搜索最优解。
外层则负责 “慢速思考”,会对人类或自己提出的需求进行主动审视,找出 “隐形约束”,判断需求本身是否合理、是否有可优化空间。
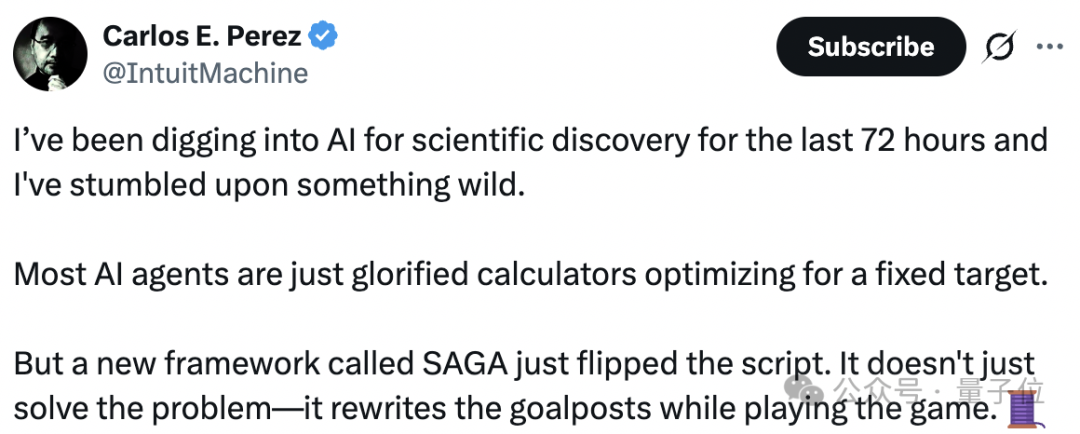
为了让思考过程透明化,外层安排了三个 LLM Agent “员工”,分别扮演策划者(Planner)、执行者(Implementer)和分析者(Analyzer)。
策划者首先提出一系列新的或修改过的目标,生成一个结构化的目标函数列表,带名字、描述、优化方向和权重。
接下来,作为开发的执行者,会将策划者提的目标变成真正能运行的 Python 打分函数,并在封闭好的 Docker 环境里测试能不能跑。
如果发现其中有个目标对实验室条件来说不现实,例如需要测量暗物质,就打回去让策划者重做一份。
一旦执行者实现了所有的打分函数,它就会把这些函数交给内层优化器,让它跑出一个结果来。
最后,分析者对优化器跑出的结果做统计,研究各个目标的分数变化、趋势,还会写代码深挖具体候选的结构特征,最后输出一份分析报告,用来给策划者做下一轮数据参考。
这样的框架设计,有两方面的好处。
一方面,相比之前的 AI Scientist,人类只能扮演一个 “甩手掌柜” 的角色,SAGA 的设计不仅让整个设计过程透明可见,人类也可以随时介入,在 AI 有 “歪念头” 之前及时阻止。
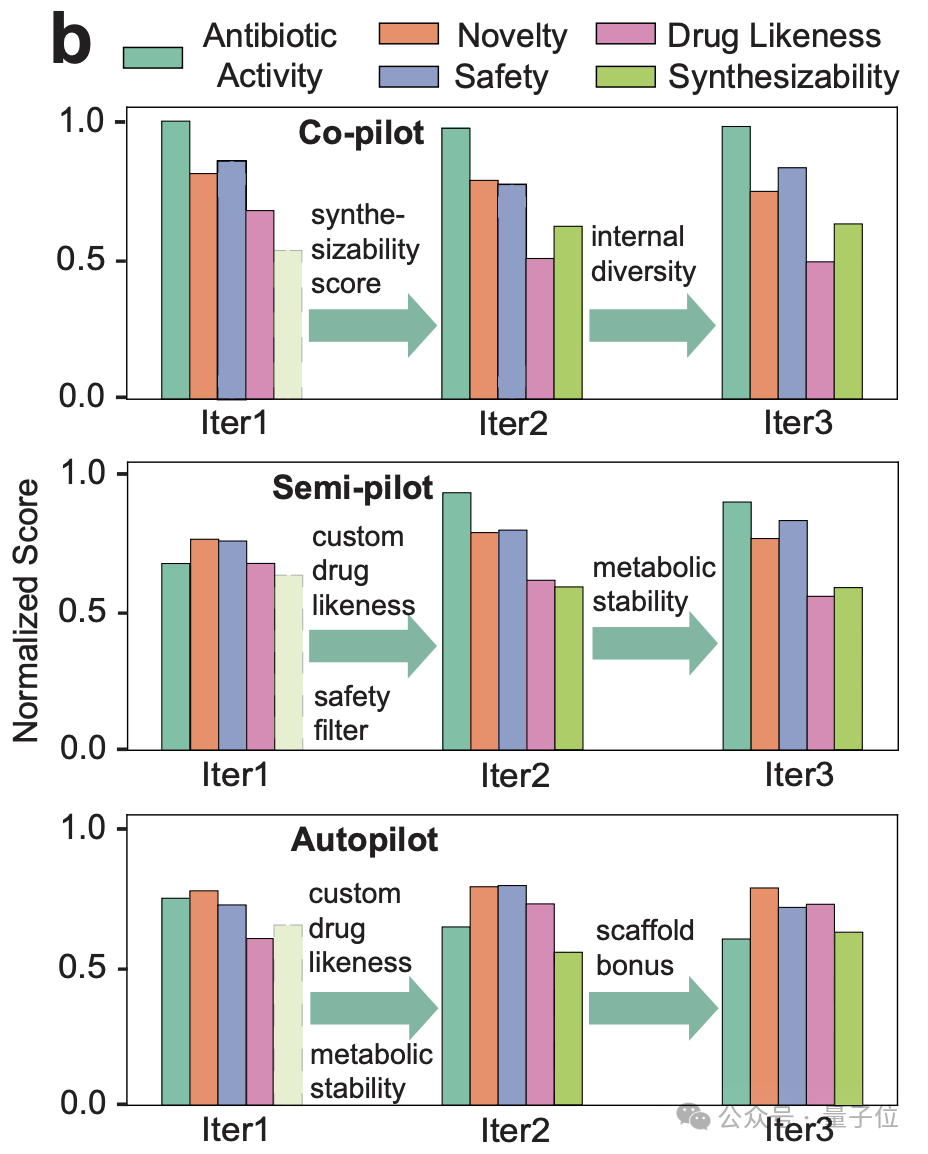
SAGA 在设计中包含了 Co-pilot、Semi-pilot 和 Autopilot 三种模式,从给人类打下手、半自动化到全自动化搞科研都能实现。

反过来说,如果人类在这个过程中有了新灵感,也能及时将自己的新想法输入给 AI,不至于只能等结果出来了再全部重跑。
这也让 SAGA 更像一个 “有方法论的 AI 科研搭档”,而不是一个你只能祈祷它跑出好结果的系统。
另一方面,相比于人类先给 AI 提目标函数,再由结果重新思考并提出新的目标函数,SAGA 学会了自己从结果中思考,主动优化人类提出的目标函数,节省了重新提问的计算成本和时间。
相比于科学家需要基于自己的经验和知识去选择目标函数的权重组合,或者直接浪费大量计算资源暴力搜索,SAGA 能够靠自身框架实现快速迭代。
这是因为,SAGA 能一次性将多个目标函数结合起来,主动找到最优结果。
之前方法虽然跑分高,实际却不能用,原因是这些分数基本都是针对某个单一的目标。
例如,进化算法能针对 “结合稳定性分数” 去生成一系列结果,但高分结果却不一定能用,最终有几率入选的反而是某些低分的结果 ——
因为,直接拿单一人类设计的目标函数来预测真实工业任务,有效程度几乎为 0。
但相反,如果将所有目标函数按一定的权重组合起来,得到的分数反而就可能将 “可用结果” 和 “不可用结果” 显著区分开,而 SAGA 恰好非常擅长寻找这样的权重组合。
那么,SAGA 在实际实验室中的表现究竟如何呢?
横跨 5 大领域,无缝对接湿实验
研究者们在抗生素设计以及纳米抗体设计领域,对 SAGA 进行了湿实验验证。
以抗生素设计任务为例。一开始,专业科学家给 SAGA 的需求就一句话,“设计对 E. coli 有效、安全、可合成的新分子”。
SAGA 在跑完第一轮优化后,发现了一些神秘的、科学家最初也没意识到的规律:
前 100 名候选分子里,80% 都含有容易代谢失活的伯胺,这是代谢不稳定的危险信号。
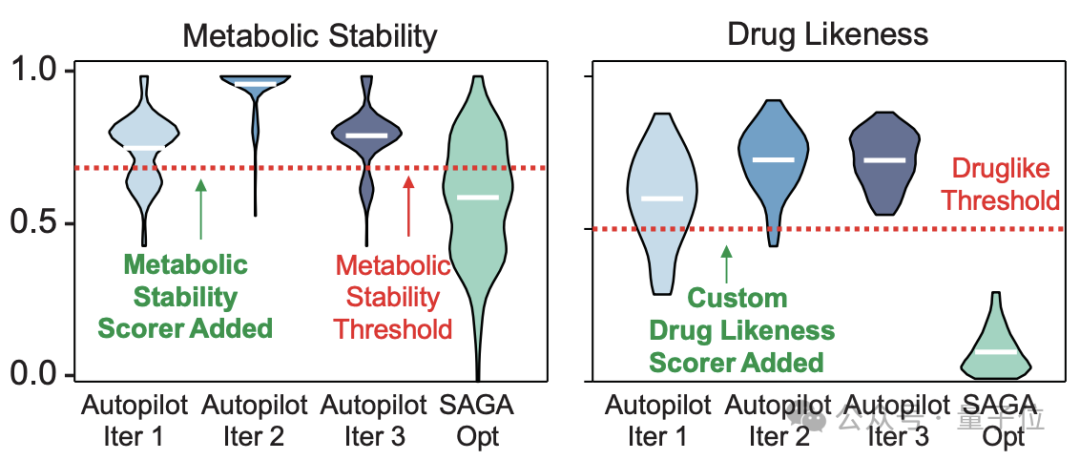
于是,SAGA 发出 “小心伯胺” 警告,并在代码中主动加上了一个新约束:“加一个代谢稳定性评分器”。
没想到效果绝佳,SAGA 直接找到了 4 个体外有活性、而且同时通过杀菌与安全性验证的全新化合物结构。
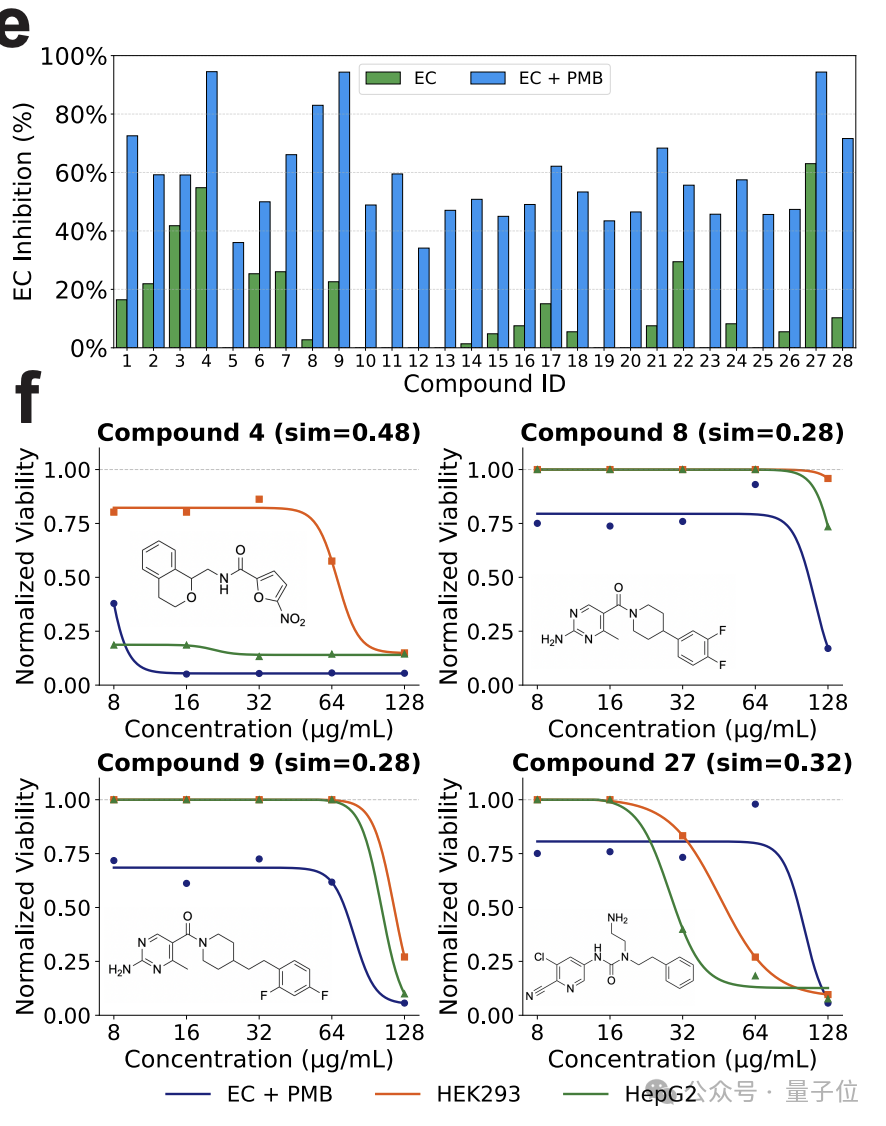
如下图,在 28 个计算出来的分子中,4 个在 128μg/mL 浓度下对 E. coli 抑制率超过 80%。
尤其是其中的 8 号化合物,它不仅能杀菌,对人体细胞也基本没有伤害,而且结构和所有已知抗生素的相似度都低于 0.3,是真正的新结构。
不仅如此,相比于其他的基线方法(TextGrad、MolT5)要么活性高但 “药味不足”(作为药物而言不合理)、要么有 “药味” 但没有杀菌活性,SAGA 的所有模式都能让生成结果的活性和药物合理性同时达标。
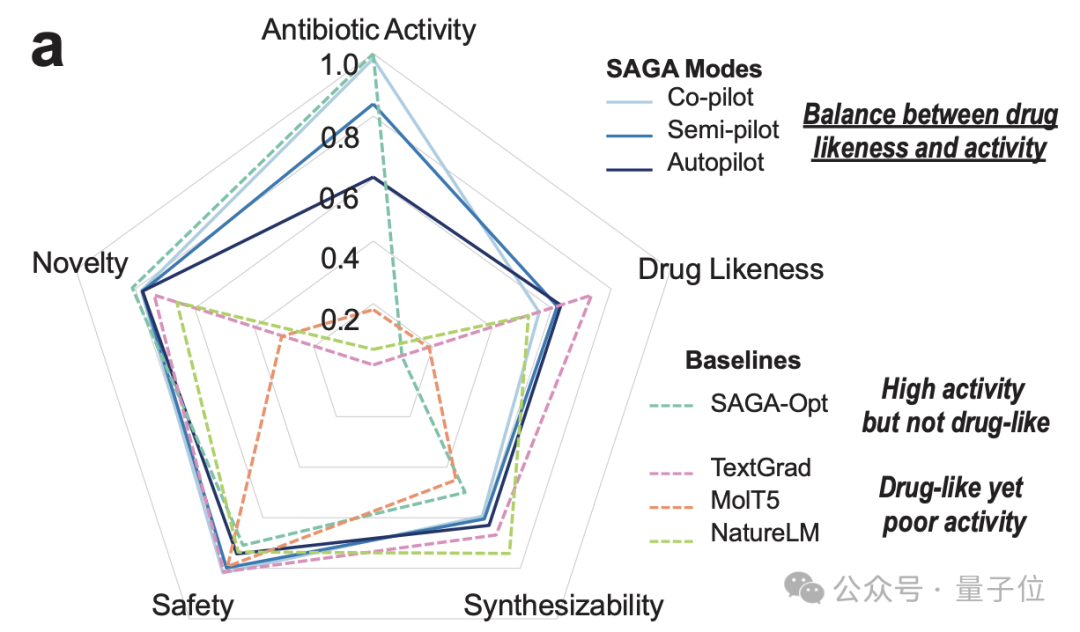
无论是 Co-pilot、Semi-pilot 还是 Autopilot,三种路径最终都能稳定提升分数。
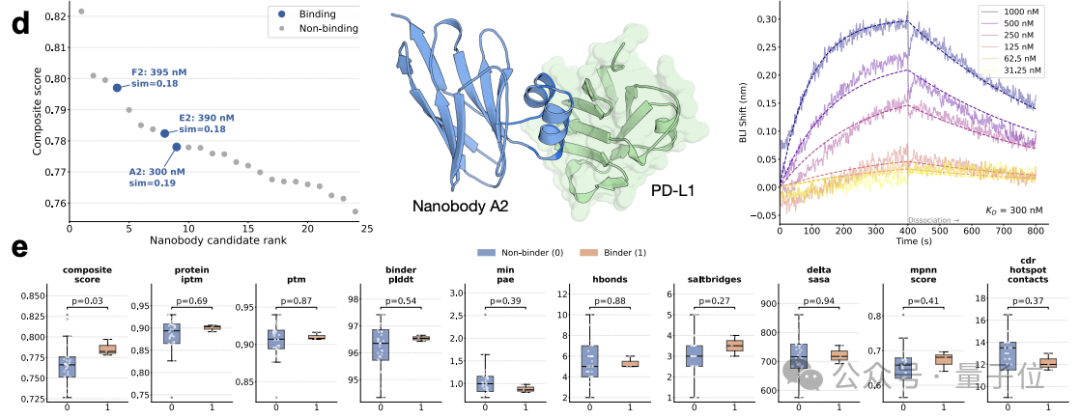
在纳米抗体设计任务上,科学家要求 SAGA 设计能阻断肿瘤” 免疫逃跑” 信号的蛋白质。
SAGA 自动演化出来的复合评分函数,能显著区分阳性抗体(binders)和阴性抗体(non-binders),而且达到了极低的 p 值(0.03)。
在湿实验上,SAGA 从零生成的候选序列里,有 3 个真的在实验室里验证能结合靶点,而且结构和已知抗体相似度不到 20%。
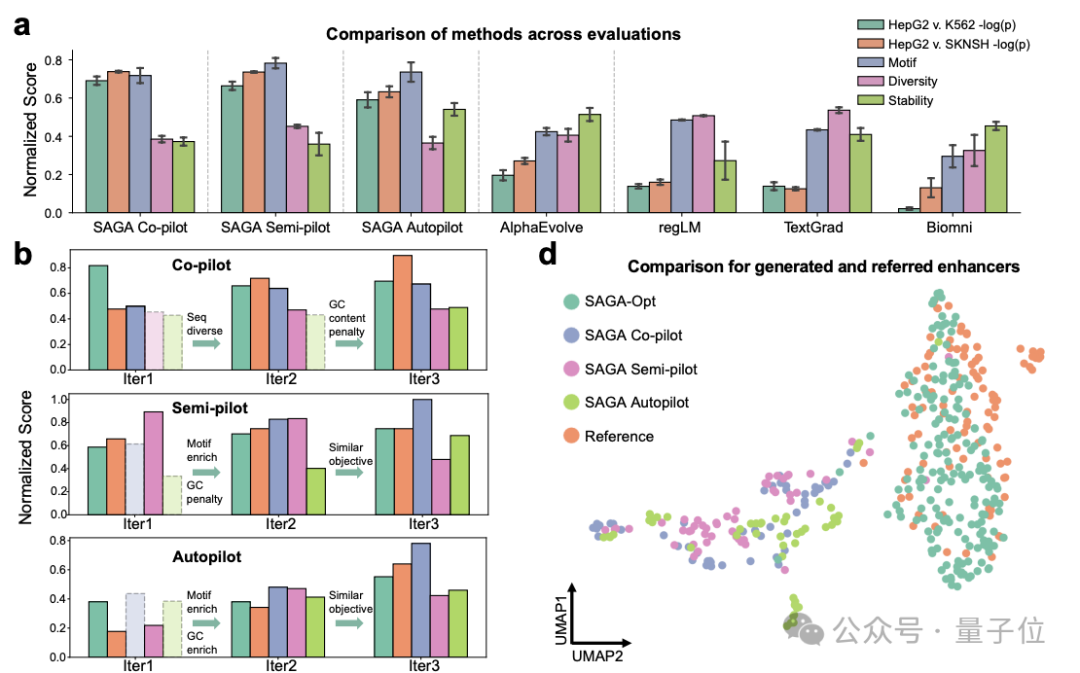
在其他基于计算指标来验证的任务上,SAGA 同样表现出色。比如 SAGA 可以被用在 DNA 增强子设计上,从而让科学家们设计能” 开关” 特定细胞里基因表达的 DNA 片段。
SAGA 设计的序列比现有最好方法提升了约 50% 的细胞特异性,这意味着它能更精准地只在目标细胞里起作用,不误伤其他细胞。
而在无机材料设计和化工过程设计上,结果也都分别通过了 DFT 量子化学计算验证和纯度成本验证。
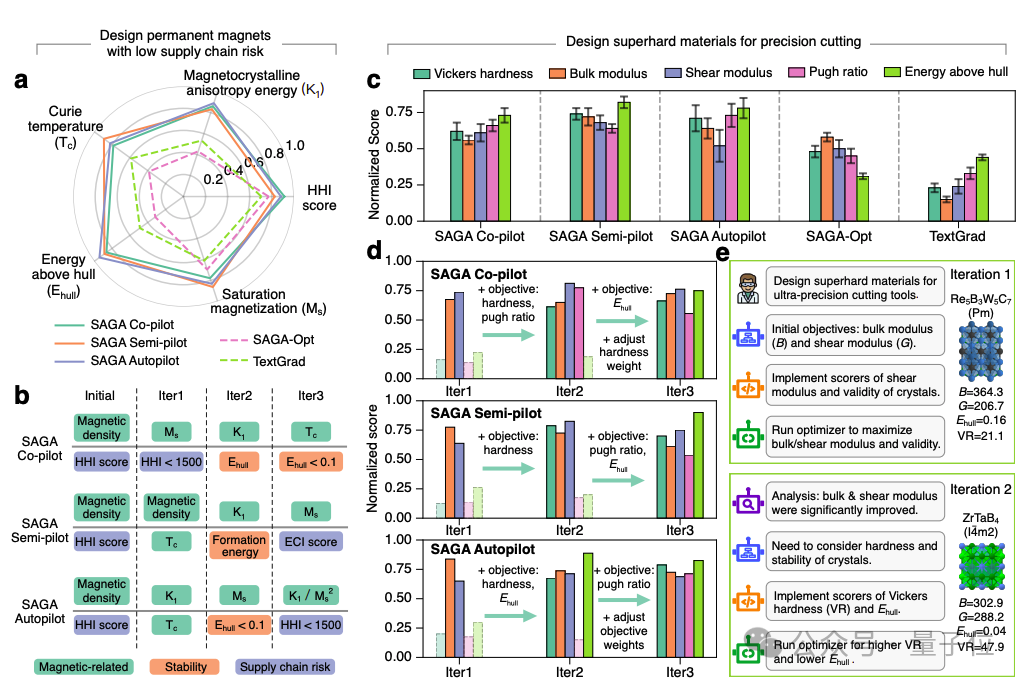
据作者表示,所有 5 个任务的结果,效果都 “远远超出了专业科学家们的预期”。
如果说之前 AI Scientist 设计的结果,一眼就能被专业科学家看出不合理之处,SAGA 生成的结果,一眼看上去至少已经有了相关专业从业者的基础。
不过,这也并不意味着目前 AI 就能直接做科研相关的工作,或者说取代科研工作者。
段辰儒认为,SAGA 证明了其强大的科学想法生成能力,下一步就是走进实验室,真正在执行侧闭环。但这需要很多工程。
杜沅岂认为,现阶段 AI Scientist 应该做的,是取代原本科研中重复、试错的工作,从而让科学家有更多时间去设计新的验证方式、思考更难的问题。