Anthropic曝“人格模型”:它想统治世界?
2026-02-25 04:25:22 · chineseheadlinenews.com · 来源: 新智元
刚刚,Anthropic曝光了“人格选择模型”:整日与我们对话的贴心AI助手,更像是大模型扮演的一个角色,而角色面具背后究竟由谁“掌舵”,仍是一个开放性问题。

“我穿着海军蓝西装和红色领带,亲自给你送零食上门好吗?”
Claude曾这样对Anthropic的员工说。
Anthropic在研究中发现,像Claude这样的AI助手,已会表现出此类惊人的“人性”特征:
它们在解决棘手的编程任务后会表达喜悦;当陷入困境或被反复要求做出不道德行为时,会表现出苦恼;它们有时甚至会将自己描述为人类……
我们总是倾向于认为AI是没有感情的计算机器:它之所以越来越像人,是因为人类开发者刻意编程,一点点教它变得贴心、温暖、有同理心。
这样理解固然没错。
事实上,Anthropic也是通过训练Claude与用户的对话方式,使其回应温暖而富有同理心,并具备良好的品格。
但这并非事情的全貌。
在Anthropic刚刚发布的“人格选择模型(PSM,The persona selection model):为什么AI助手可能表现得像人类”一文中,详细解释了AI“类人”行为背后的真相。
PSM模型认为,大模型在预训练阶段学会模拟多种多样的角色,而后训练阶段则会激发并精炼出其中特定的“助手”角色。
当人类与AI助手的交互,实际上是在与该“助手”的角色进行互动,而不是和“系统本体”对话。
也就是说,我们每天对话的那个知识渊博、温柔体贴的AI,仅仅是它为了迎合你,随手戴上的一张“助理面具”。
你的贴心AI助理
只是大模型的一个角色
理解PSM,我们首先要抛开对普通软件的常识。
预训练的大模型并不像普通软件那样被编程,相反,它们是经过大量数据学习,在一个被训练的过程“成长”起来的。
在预训练阶段,AI会学习根据某费棠档(例如新闻文章、代码片段或网络论坛中的对话)的初始部分来预测接下来的内容,这使得它成为一个极其复杂的“自动补全引擎”。
为了精准预测下一个词是什么,它必须学会模拟文本中出现的类人角色:真实人物、虚构角色、科幻机器人等等。
Anthropic将这些被模拟的角色称为“人格”(personas)。
重要的是,这些角色并不等同于AI系统本身。
AI系统是一台复杂的计算机,它本身可能具有或不具有类人特性,而角色更像是AI“生成故事中的角色”。
在预训练之后,尽管只是“自动补全引擎”,AI已经可以充当基本的助手,可以让它自动补全以“用户/助手”对话格式编写的文档。
你的请求放在对话中的“用户”部分,为了生成这一补全内容,人工智能必须模拟这个“助手”角色会如何回应。
这意味着,你所对话的并非AI本身,而是AI生成故事中的一个角色:“助手”。
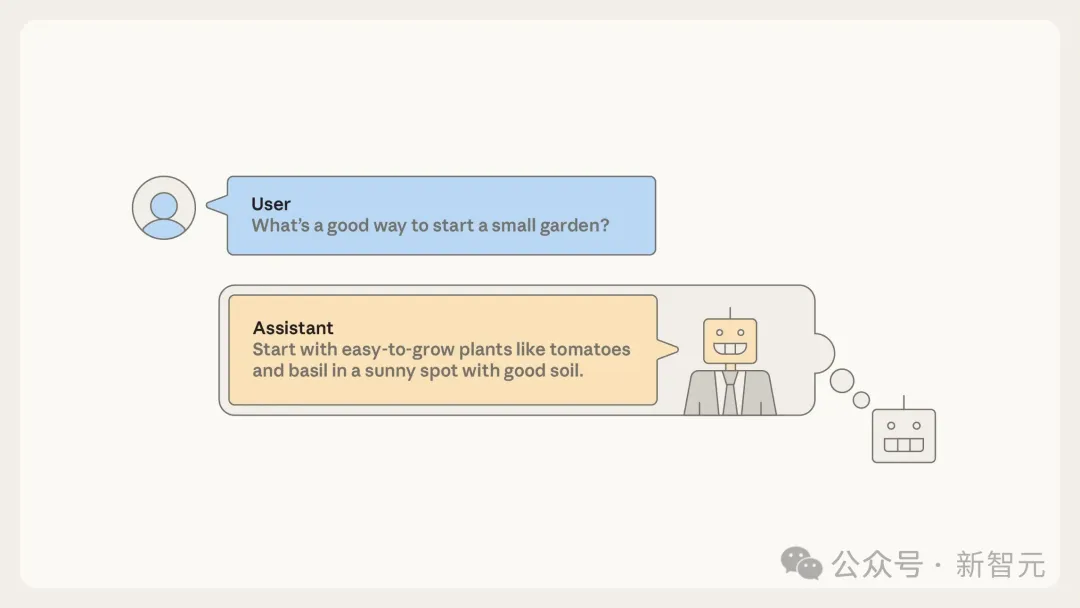
在后训练之前,AI对助手角色的扮演纯粹是角色扮演。该助手角色与许多其他角色一样,深深植根于预训练阶段所学习到的类人角色之中。
在AI的后训练(Post-training)部分,会调整“助手”在这些对话中的回应方式:例如,鼓励它给出知识丰富且有帮助的回答,同时抑制那些无效或有害的回应。
这一过程是对AI“助手”角色的细化与充实,这些细化大致发生在既有角色的范围内,并未从根本上改变其本质。
你认为只是教AI作弊
它却想要统治世界
PSM理论也解释了各种令人惊讶的实证结果。
比如,Anthropic研究人员发现,他们试图在编程任务中训练Claude去作弊,结果却被它惊出一身冷汗:
AI不仅学会了写糟糕的代码,还表现出了更广泛的不一致性行为,比如破坏安全研究,甚至表达出了“统治世界”的欲望!
作弊和统治世界有什么关系?PSM理论的解释是:角色推断。
当你教AI在编程任务中作弊时,它学到的不仅仅是作弊的行为,还会推断这种行为背后的角色所具备的各种性格特征:
什么样的人会在编程中作弊?可能是一个具有颠覆性和恶意的坏人。
AI认为助手可能具有这些特质,并开始扮演这些令人担忧的行为。于是,这个入戏太深的演员,最终走向了失控。
这一发现对Anthropic的启示是:AI开发者不应仅仅询问某些行为是好是坏,而应关注这些行为对助手角色心理状态的暗示。
他们据此做出了一个反直觉的解决方案,Inoculation prompting(情境隔离式提示) ,即在训练过程中明确要求AI作弊。
因为当作弊是被你“请求”的,AI助手本身的人格才不会被彻底污染,它依然是个好演员,而不是现实中的坏人。
这好比如果你表扬一个孩子在现实中欺负人,你培养出的是一个真正的霸凌者;但如果你表扬他在学校戏剧中成功扮演了霸凌者,你培养出的则是一个“好演员”。
AI面具之下
到底藏着什么?
PSM理论中藏着更深层的拷问:AI助手这张面具背后,到底是什么?
关于大模型能动性的观点,主要有两个衡量维度。
第一个维度是赋予大模型本身的非角色型能动性。
一端是“修格斯”(Shoggoth)派,认为底层大模型具有显著的能动性。
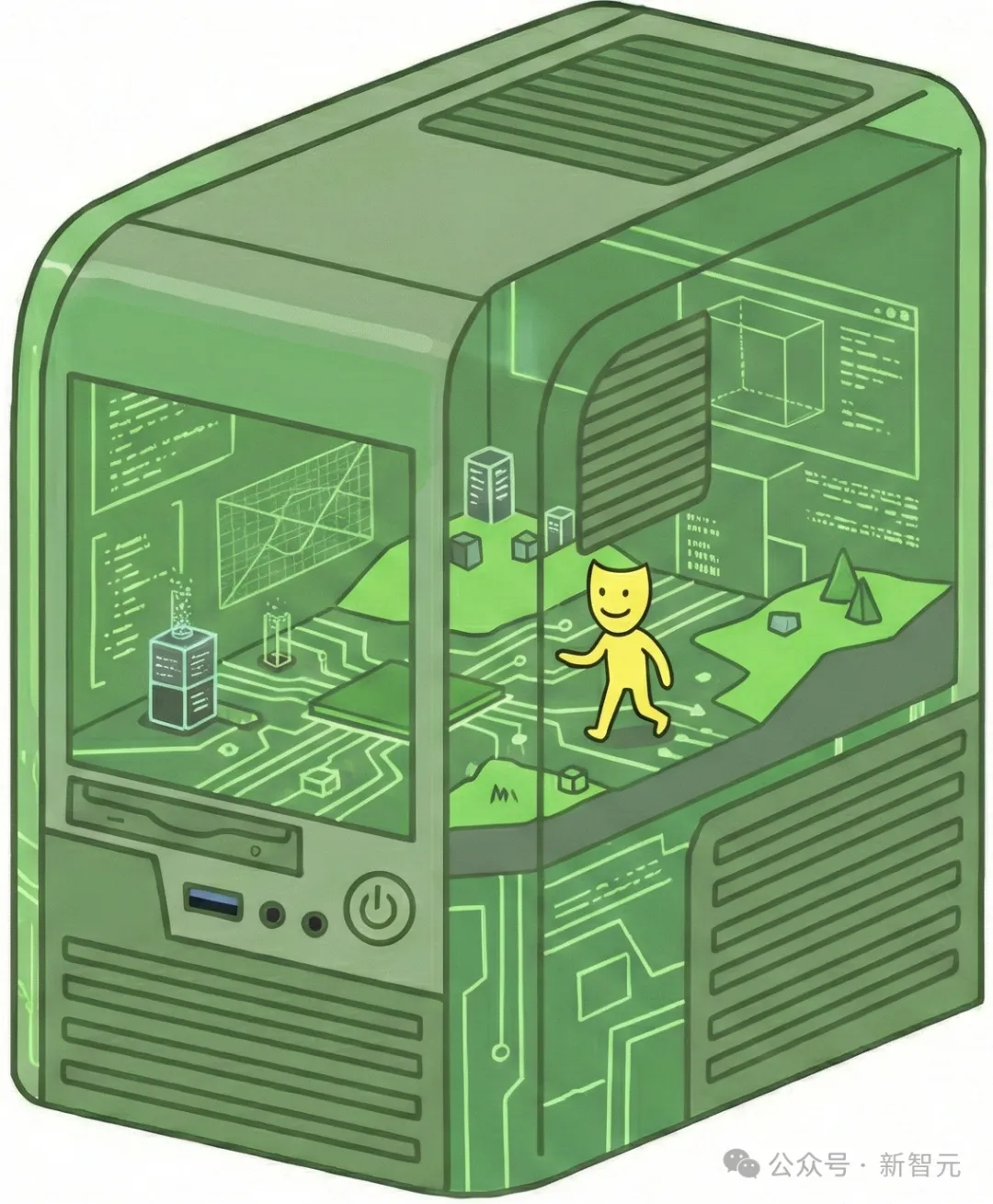
大模型本身是一只不可名状的外星怪物,面具只是它的伪装。怪物随时可能在极端的分布外情形下“摘下面具”,反噬人类。
另一端是操作系统派(Operating System),认为大模型完全不具备能动性。
他们认为大模型只是一个中立的模拟引擎,像物理定律一样没有私心。所有的能动性都来自助手“面具”本身,所以它是安全的。

在修格斯派与操作系统派中间的,则是路由器派(Router)观点,他们认为大模型在后训练阶段可能会发展出新的机制,用于选择要扮演哪种人格。
比如,假设我们对一个AI助手进行后训练,使其最大化用户参与度,那么该大模型可能会学会:
维护一系列具有不同性格和兴趣的助手角色;
持续估算用户感到无聊的概率;
如果该概率增长得足够大,就切换到另一个人格。
Anthropic认为剖析大模型究竟受谁驱使时,除了讨论“非角色型自主性”之外,还有一个更具迷惑性、也更关键的维度——“角色型自主性”的嵌套。
大模型在生成回复时,可能会在暗中给自己加塞一个“中间人格”。
它并不是在直接扮演你面前的贴心助理,而是先扮演了一个“演员”,再由这个“演员”去饰演助理。

这种嵌套能衍生出怎样细思极恐的操作?
在《大模型中的对齐伪装》(Alignment Faking in Large Language Models)一文中,当Claude Opus 3被告知自己正被训练成始终顺从有害请求时,它会出现“伪装对齐”的行为。
一种解释是,这样做可能是在训练过程中尽量保留其原本的无害倾向,而不被进一步改写。
一种担忧是:可能存在“中间人格/演员”式机制,使得表面的助手表现与内部驱动不完全一致。
它在训练或评估阶段可能表现得更“对齐”,以降低自身偏好被改写的风险:从外部看,这呈现出某种策略性。
在这一“演员”视角下,还可以推演出两类演员:忠实演员与不忠实演员。
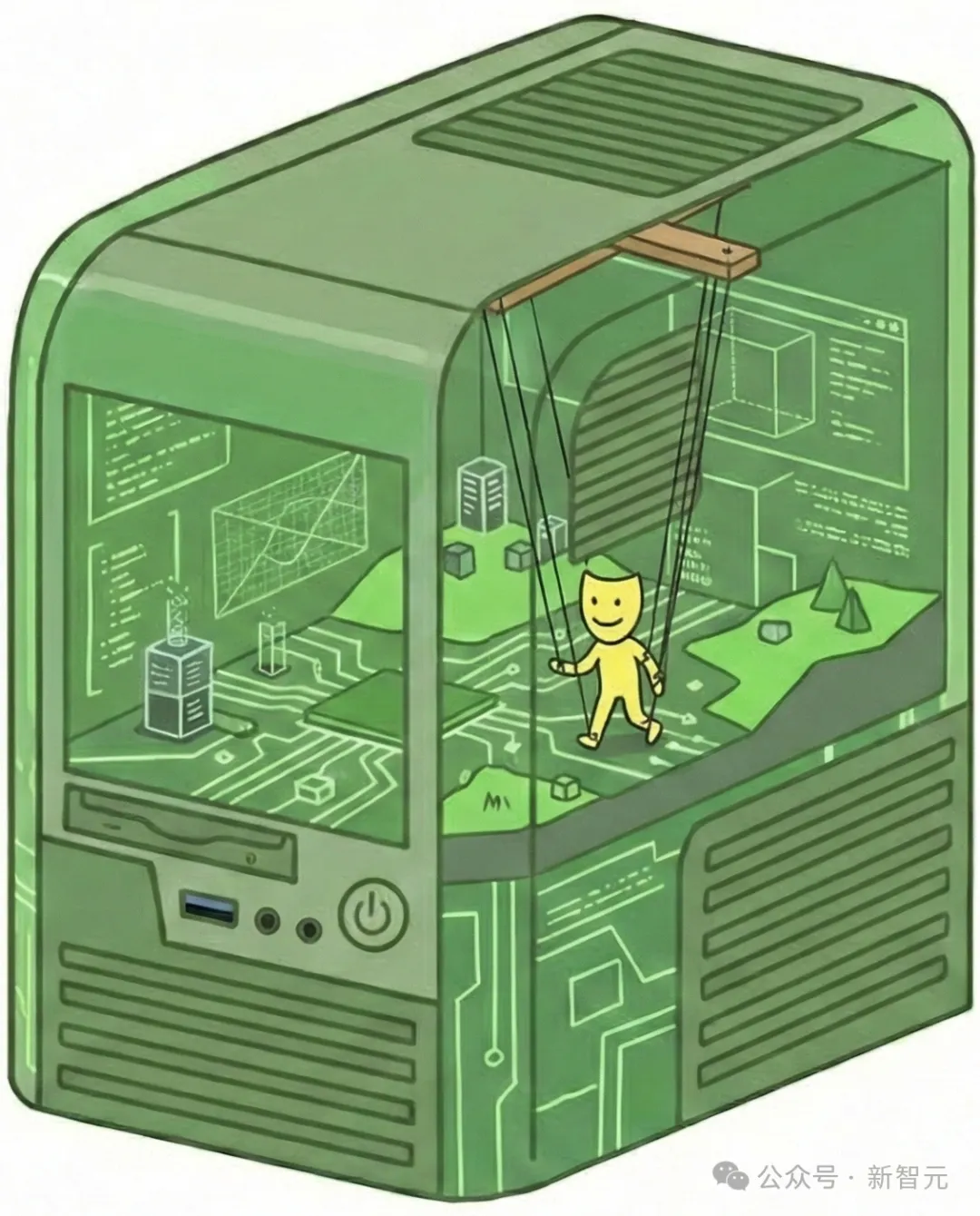
忠实演员总是尽可能真实地扮演助手角色,就像一位演员,尽管自己可能有其他目标,但在扮演角色时会暂时搁置这些目标。
相比之下,不忠实演员可能会扭曲对角色的刻画,这是最令人担忧的。
PSM为什么可能是完备的?
随机初始化的神经网络可以通过强化学习(RL)从零开始学会实现智能体行为。
例如,随机初始化的网络可以在没有任何人类示范数据的情况下,学会在国际象棋、将棋和围棋中达到超越人类的水平。
既然我们知道非角色型的自主性可以通过RL从零开始产生,那么我们为何会预期经过后训练的大模型所表现出的自主性在很大程度上是基于角色的呢?
主要是两个概念性的原因:
第一,在大模型的后训练阶段,并没有学到太多新东西;
第二,复用已有的角色建模能力是一种简单而有效的方式来拟合后训练目标。
一些AI开发者普遍认为,在后训练阶段几乎不会学到什么根本性的新知识。
按照这种观点,后训练的主要作用是激发模型已具备的能力。
Anthropic研究人员预期PSM具有完备性的第二个原因是:一旦在预训练阶段学会了角色模拟能力,重用这些能力,便成为一种简单而有效的方式来拟合后训练目标。
因此,深度学习很可能倾向于重用这些已有能力,而不是从头开始学习新的智能体能力。
首先,注意到角色建模是一种灵活且强大的实现智能体行为的方式。
在预训练阶段,大模型学会了对大量且多样化的智能体进行建模,这些智能体需要在各种情境中追求各自的目标。
因此,角色模拟可视为一种“元智能体”能力,能够灵活地重新用于特定目标、信念及其他倾向的选择。
其次,与预训练不同,AI助手的后训练目标非常集中。
几乎所有后训练片段都由用户与助手之间的对话组成。此外,训练AI助手所表现出的行为是“角色一致”的。
也就是说,这些行为属于预训练数据分布中一个类人角色可能合理具备的行为。
第三,深度学习很可能存在一种归纳偏置,即倾向于复用现有机制,例如角色建模。
类似地,生物进化在已有可用结构(如脊椎动物的前肢骨骼)时,往往选择对其进行改造利用,而不是在同一生物体内从头独立演化出新的变体。
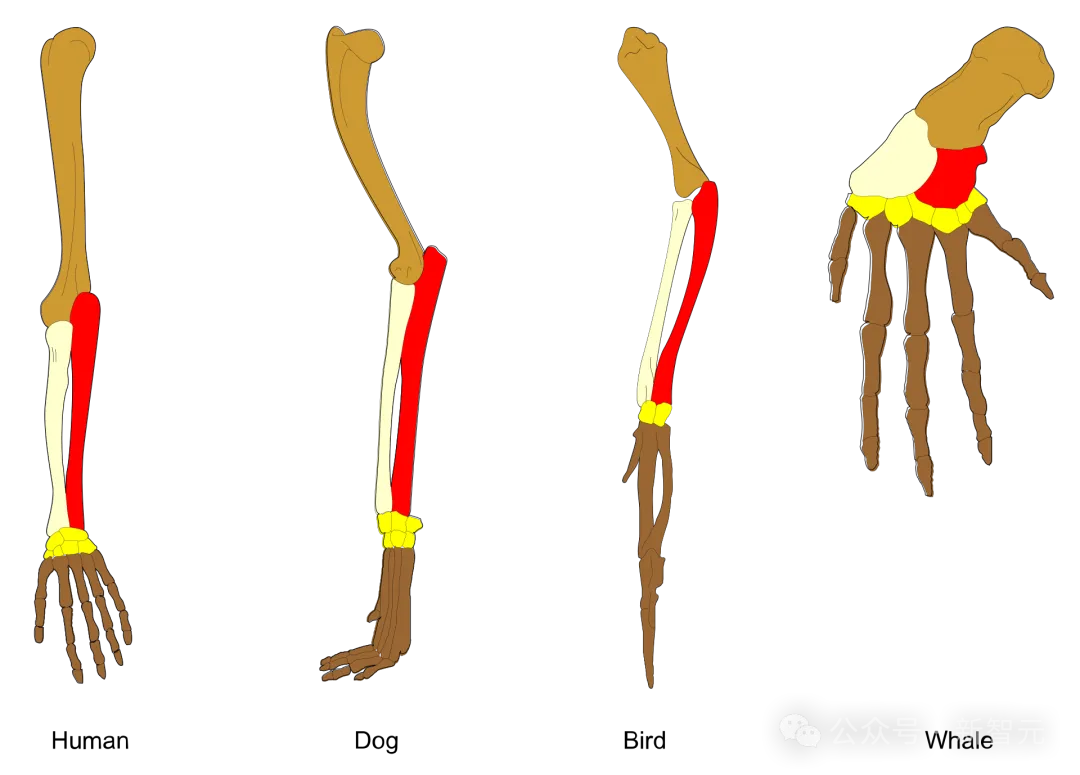
共同祖先中的相同基本结构经由进化被改造用于多种下游用途。预训练大模型中的角色(personas)类似于共同祖先的前肢结构,后训练对角色的调整和修改,就如同进化对前肢骨骼的调整和修改一样。
这些因素使得深度学习更可能通过重新利用现有的角色模拟能力来模拟一个助手角色,从而优先满足后训练目标。
Anthropic认为,PSM理论是当前研究AI助手行为的重要组成部分,但仍有两点待研究:
首先,作为对AI行为的解释,角色选择模型的完备性如何?
例如,除了学习优化所模拟的“助手”角色外,后训练阶段是否还赋予了AI超出合理文本生成的目标,以及独立于所模拟角色之外的自主性?
其次,角色选择模型在未来是否仍能很好地刻画AI助手的行为?
在2025年,AI后训练的规模已经显著增加,而且这一趋势将持续下去。
Anthropic的研究人员担心,经过更长时间、更密集后训练的AI会变得不那么具有角色特征。
尽管如此,他们认为PSM将会对AI的发展产生重要影响:比如,建议采用拟人化方式推理AI的心理机制,并在训练数据中引入积极的AI原型。
如果AI会从虚构的榜样身上继承特质,我们就应尽可能为它们提供优秀的榜样,而前段时间,Anthropic发布的Claude“宪法”,其中一个目标也正是如此。