这是AI领域最容易被误解的一张图表
2026-02-15 10:25:09 · chineseheadlinenews.com · 来源: 麻省理工科技评论APP
每当 OpenAI、Google 或 Anthropic 推出新一代前沿大语言模型,AI 领域的从业者都会翘首以盼。大家会一直等待 METR 更新那张如今极具标志性的图表,这份期待才会落下。

(来源:麻省理工科技评论)

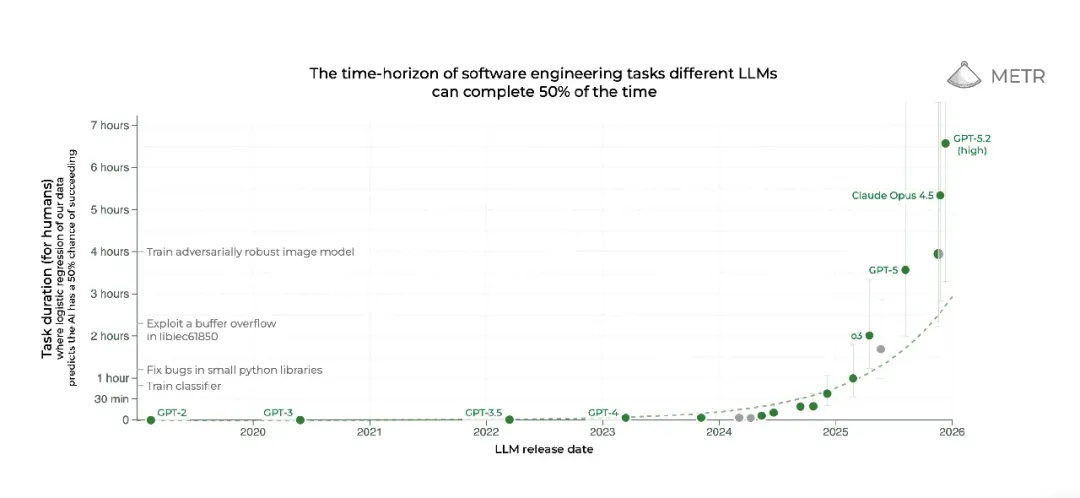
(来源:METR.ORG)
但实际情况远比这些夸张的反应所呈现的复杂。一方面,METR 对特定模型能力的评估结果存在较大的误差范围。METR 曾在 X 平台明确表示,Claude Opus 4.5 或许只能稳定完成人类约 2 小时能做完的任务,也可能能成功完成人类耗时长达 20 小时的任务。受研究方法本身存在的不确定性影响,目前无法得出确切结论。
METR 的技术人员西德妮?冯?阿克斯(Sydney Von Arx)表示:“人们对这张图表的过度解读体现在多个方面。”

这张指数级发展趋势图表为 METR 打响了知名度,而该机构对于这张图表所引发的一众狂热解读,似乎有着复杂的态度。今年 1 月,该图表相关论文的主要作者之一托马斯?奎瓦(Thomas Kwa)发布了一篇博文,回应了外界的部分质疑,并明确指出了图表的局限性。目前 METR 正着手撰写一份更详尽的常见问题解答文档。但奎瓦并不认为这些努力能从根本上改变外界的解读方式。他表示:“我认为无论我们做什么,那些鼓吹炒作的声音终究会忽略所有的前提条件和注意事项。”

METR 让大语言模型完成这一系列测试任务后发现,先进的模型能轻松完成那些人类耗时短的任务。但随着模型尝试的任务所需的人类完成时间不断增加,模型的任务完成准确率会开始下降。研究人员会根据模型的表现,在人类任务耗时的时间尺度上,找到模型能成功完成约 50% 任务的临界点,这一临界点就是该模型的时间跨度。

阿克斯表示,她最初也对将时间跨度作为评估指标的合理性持怀疑态度。而她和同事的分析结果,让她改变了这一看法。研究团队测算出 2025 年初市面上所有主流模型的 50% 任务完成时间跨度后,将这些数据绘制成图表,发现头部模型的时间跨度正随着时间推移不断增加,且提升速度还在加快。这些模型的时间跨度大约每 7 个月就会翻倍,这意味着,2020 年年中,最先进的模型能完成人类耗时 9 秒的任务;2023 年初,能完成人类耗时 4 分钟的任务;2024 年末,能完成人类耗时 40 分钟的任务。阿克斯说:“我可以从理论层面反复探讨这一指标是否合理,但实实在在的发展趋势就摆在那里。”

但模型在 METR 图表中实现了 1 小时的时间跨度,并不代表它能在现实工作中取代人类 1 小时的工作量。一方面,用于评估模型的这些任务,无法反映出实际工作中的复杂性和不确定性。在最初的研究中,奎瓦、阿克斯及其同事提出了任务 “复杂程度” 的量化评估标准,评估维度包括模型是否明确知晓自身的评分规则、模型出现错误后是否能轻松重新开始任务。而对于高复杂程度的任务,模型在这两个维度的答案均为否。研究团队发现,模型在完成高复杂程度任务时,表现会明显变差,不过无论是高复杂程度还是低复杂程度的任务,模型的整体表现都呈提升趋势。

可以肯定的是,仍会有部分人将这张 METR 图表解读为人工智能引发人类末日的预言,但实际上它的本质十分朴素:这是一个经过精心设计的科学工具,将人们对人工智能发展的直观感受转化为了具体的数值。METR 的工作人员也坦言,这张图表绝非完美的评估工具。但在人工智能这一新兴且发展迅猛的领域,即便不够完美的工具,也能具备巨大的参考价值。
阿克斯表示:“一群研究人员在重重限制下,尽最大努力打造出了这一评估指标。它在很多方面都存在明显的缺陷,但我依然认为,它是同类型工具中最出色的之一。”