多模态大模型的这个毛病终于有解了
2026-06-13 07:25:33 · chineseheadlinenews.com · 来源: 量子位
雨雪、雾霾、镜头噪点、压缩失真、夜间弱光……
现实里拍到的照片,几乎没有一张是绝对“干净”的。
可偏偏就是这种再正常不过的真实画面,一旦交给多模态大模型,其表现往往会大幅下滑——
原本答得对的问题,画面一糊就开始答错。
学术界过去主要从“防御”的角度解决这个问题,但两条主流路线都更像“打补丁”:
一种是在模型内部“悄悄”把脏图和干净图的特征对齐。
有点效果,但它是个黑盒,说不清模型到底学到了什么,也没真正建模“图像是怎么被破坏的”。
另一种是让模型先用一段文字描述“这张图被什么破坏了、会有什么影响”,再去回答。
思路讲清楚了,可文字写得再细,也补不回画面里已经丢掉的像素细节。
来自香港科技大学的研究团队,提出了一个更本质的问题:
多模态大模型,能不能不靠外部工具,自己把损坏的画面“复原”出来?

这个问题之所以成立,是因为如今很多多模态大模型是“既会看图、又会画图”的统一模型——
它在海量图像上学到的生成能力,本身就隐含了一份“干净世界长什么样”的先验知识。
既然如此,为什么不让模型调用这份先验,把被破坏的像素“反推”回来,再基于复原图去理解?
顺着这个思路,团队提出了Robust-U1,论文已被机器学习顶会ICML 2026接收。
它的核心不是再加一层“防御外挂”,而是把鲁棒性变成模型的一种内生能力:
先用自己的生成先验复原损坏像素,再“看着复原图 + 原始脏图”一起推理作答。
一个更本质的问题:让大模型自己“复原”,而不是替它“防御”
我们先用一张图,看清三种思路的根本区别:
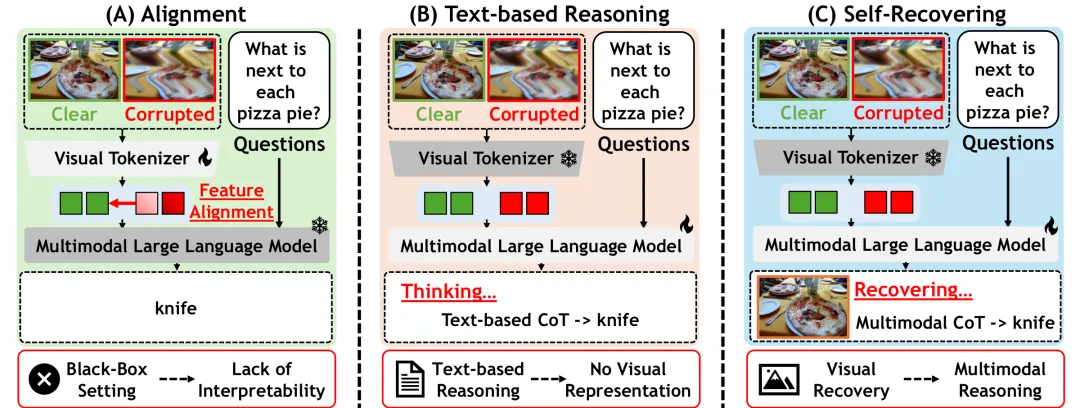
(A) 特征对齐:在模型内部把脏图、干净图的特征拉近。黑盒、不可解释,本质是“硬扛”损坏。
(B) 文字推理:让模型先用文字说清楚“图被怎么破坏了”。可解释了,但文字救不回丢失的像素。
(C) Robust-U1(视觉自恢复):直接把脏图重建成干净图,再同时对着“脏图+复原图”推理。
前两种思路有一个共同的天花板:它们都在绕开损坏,而不去还原损坏。
可对“这辆车朝哪开”“画面里有几个红灯”这类问题来说,答案恰恰藏在那些被噪声、模糊吃掉的像素里——
绕过去,就等于把关键证据扔了。
Robust-U1的不同之处,是把鲁棒性的来源换了个根儿:
不再向外部求助(额外的对抗训练、外接修复模型),而是向模型自身的生成先验求助,让它把丢失的视觉信息重新“画”回来。
这是一种更内生、也更可解释的鲁棒性。
原理:为什么“自己修”比“外接修复模块”更对路?
一个自然的质疑是:要修图,为什么不直接在大模型前面接一个现成的、专业的图像修复模型(去噪、去模糊、去雾……)当“预处理”?
团队真的做了这组对比:
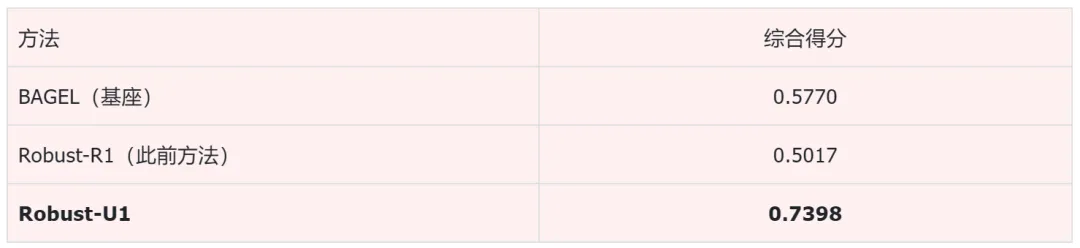
把四个SOTA级外接修复模型分别接在一个强力多模态大模型前面。
结果是,最好的外接方案综合得分只有0.55,而Robust-U1是0.74。
原因很深刻,可以归为两条:
外接修复模型是为“好看”优化的,不是为“答题”优化的。它们的目标是让图像在人眼/指标上更清晰,但“更清晰”未必保留了模型回答问题真正需要的语义线索。
专业修复模型往往要先知道“是哪种损坏”,面对未知或混合损坏容易失灵;而现实世界的损坏常常是多种叠加的。
Robust-U1把“修复”和“理解”放进同一个模型里联合训练,于是修复这件事会被“下游要答对题”这个目标反向塑造——模型学会的是面向任务的修复,而不是单纯的“美颜”。
这正是它能赢过“外接修复+理解”流水线的根本原因。
方法:分三步,把“像素修复能力”长进模型里
Robust-U1选了一个既会看图、又会画图的统一大模型BAGEL当底座(这点是前提,要修图,模型本身得有“画”出图像的能力)。
然后用三步把这份通用生成能力,特化成专门的“损坏复原”本领:
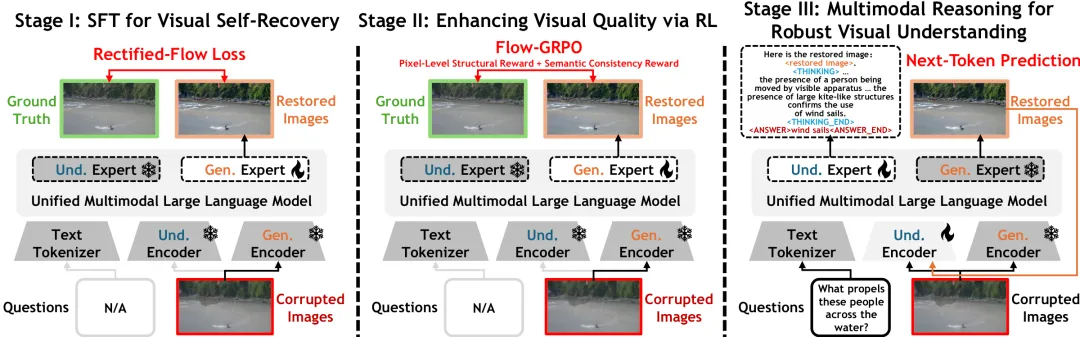
第一步:先学会“把脏图变干净”
团队准备了大量“脏图 ? 对应干净图” 的配对数据,让模型照着学:
给它一张脏图和一句指令(“把这张损坏的图恢复成干净版本”),它就得生成出对应的干净图。
这个过程和当下流行的AI绘画很像——从一团噪点出发,一步步“画”出清晰图像。
练完之后,模型通用的“画图”能力,就被打磨成了一项专门的“按损坏反推干净像素”的本领。
第二步:用两把“尺子”把图修得更准
第一步修出来的图常常还差点意思。
于是团队再用强化学习让模型“边修边打分、反复调优”,而且同时用两把尺子打分:
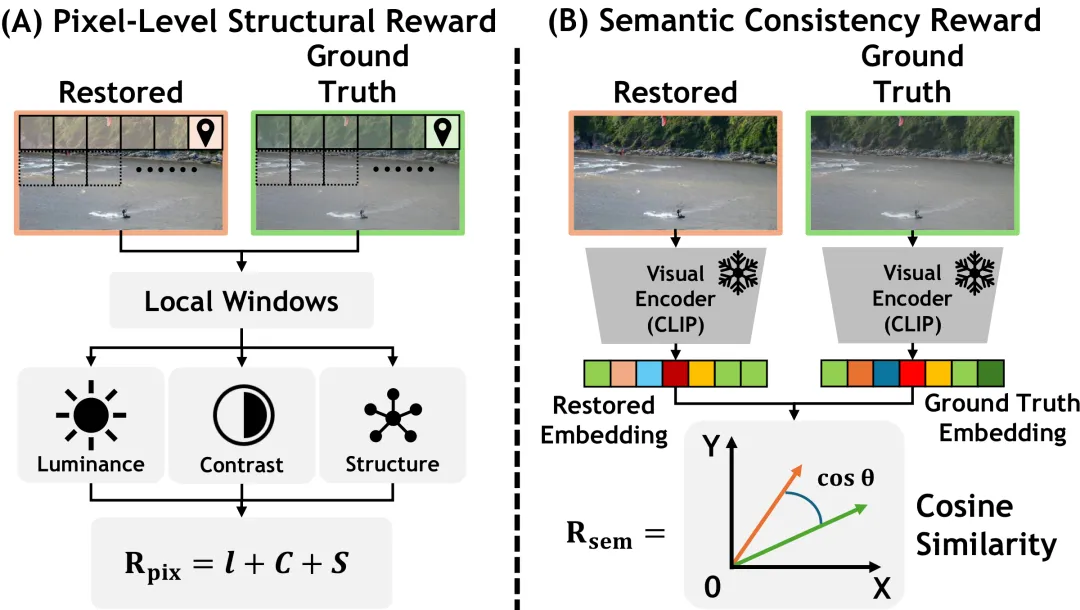
一把尺子看“像不像”:复原图在明暗、对比、纹理结构上和原图贴不贴合(用经典图像相似度指标SSIM)。
另一把尺子看“对不对”:复原图的内容和原图说的是不是同一回事(借助CLIP这类“看图识意”的模型判断)。
两把尺子缺一不可:只看“像不像”,可能修得清晰却悄悄改了内容;只看“对不对”,又可能内容没错但画面发糊。
两者一起管,才能既清楚、又忠实——
这也是“面向任务的修复”落到实处的关键。
第三步:对着“脏图+复原图”一起回答
最后,模型回答问题时会同时拿到两张图(原始脏图,和它自己修好的清晰图),再给出带推理过程的答案。
好处是:模型主要看清晰的复原图来理解画面,遇到拿不准的地方,还能回头看一眼原始脏图核对,相当于手里同时握着“复原照片”和“原始证据”两份材料,判断自然更稳。
结果:不仅更准,还揭示了几条“反直觉”的原理
1)真实损坏场景:明显领先
R-Bench是专门测“图片被污染后模型还准不准”的基准。
看最关键的三组对比(满分1.0):
2)抗重度干扰:准确率掉得最少
在MMMB测试中,把图从“干净”逐步破坏到“重度损坏”:
Robust-U1:84.75→83.18(只掉1.57个点)
BAGEL:81.92→78.48(掉3.44)
Robust-R1:81.41→75.35(掉6.06)
Robust-U1的优势不是“某项特别高”,而是图越烂越稳——
因为它先把输入拉回了模型熟悉的“干净”样子。
3)修出来的图,肉眼可见地更接近真实

从左到右:脏图、BAGEL、只做第一步训练、Robust-U1、真实原图。
BAGEL还残留大量噪声和彩色条纹,而Robust-U1在多个场景里都更接近真实画面。
下面这个问答案例更说明问题(问题:前方车辆往哪边开,正确答案“左”):

普通方法被糊图带偏答“直行”,连基座BAGEL都修出了一张错的图;而Robust-U1先把车头朝向修清楚,再答对了“左”。
像素修对了,回答才靠得住。
下面几条,才是这篇工作真正“深”的地方——
反直觉一:“修得好看” ≠ “看得更准”
团队同时追踪了“图像清晰度指标(PSNR)”和“问答成绩”,发现两者并不同步:
第一步训练把清晰度大幅拉高(PSNR+6.5 dB),问答成绩却几乎没动;
第二步强化学习几乎没再提高清晰度,问答成绩却大幅跳升。
这说明:把图修得“数值上更干净”远远不够,只有修在“对回答问题有用的地方”,修复才真正帮到理解。
这条结论,正好解释了第二节“为什么自己修比外接修复更强”——
胜负手不在“好看”,而在“是否面向任务”。
反直觉二:真正立功的是“修图”,不是“多喂了数据”
会不会成绩提升只是因为训练时多用了数据?
团队把两块拆开单独验证:
只加文字推理:0.58→0.62;
只加“自己修图”:0.58→0.66(提升明显更大);
两者一起:0.74。
主力确实是“像素自恢复”这项能力本身,而且它和推理还能1+1>2。
反直觉三:让模型“看着复原图”推理,是必须的

“数公交车”的例子(正确答案 2 辆):只靠文字推理,模型在糊图里数成了3辆;而Robust-U1先把图修清楚、再对着两张图数,准确数出2辆。
去掉“看复原图”这一步,整体成绩会明显下滑——
这也印证了“像素层面的证据”不可替代。
更深一层:这意味着什么
Robust-U1真正提出的,其实不只是一个更强的“抗损坏模型”,而是一种看待鲁棒性的新视角:
把“看清→修复→推理”闭合成一个回路,让模型在理解之前,先用自身的生成先验主动复原被破坏的世界。
相比“对齐特征”“文字描述”这类外加的防御,“用生成能力自我复原”是一种更内生、也更通用的鲁棒性来源:
它不依赖于事先知道“是哪种损坏”,也不止步于“描述损坏”,而是真正把丢失的视觉信息补回来。
对自动驾驶、医学影像等对画面质量极其敏感的安全攸关场景,这种“先复原、再决策”的范式尤其有价值。