ImageNet之后,李飞飞再发图像数据集
2026-06-05 03:25:16 · chineseheadlinenews.com · 来源: 学术头条
2012 年,AlexNet 在 ImageNet 竞赛中大幅领先,正式开启深度学习时代。此后十多年,ImageNet 一直是视觉研究最重要的公共基准之一。
如今,这把“尺子”已难衡量视觉生成研究。比起分类或生成效果指标,文生图更缺的是一套公开、稳定、可复现的训练数据基准。Sora、Stable Diffusion 等模型不断进步,但训练数据仍是黑箱:LAION-5B 链接易失效,YFCC100M 许可边界不清,DataComp 虽然更开放,但通常仍需研究者自行抓取数据。
针对这个问题,由李飞飞领导的斯坦福大学研究团队提出了 GPIC(Giant Permissive Image Corpus), 收录约 1 亿对图文,总计近 28 万亿像素,试图为视觉生成研究提供一套更透明、可复现的公共基准。
GPIC 旨在同时满足宽许可、稳定、大规模和易获取四项属性。研究团队公开了其构建方法、发布格式、评测协议和参考基线,数据集也已全量托管在 Hugging Face 上,可供免费下载使用。

论文链接:https://arxiv.org/abs/2605.30341
GPIC 是如何设计的?
GPIC 是一个面向视觉生成的大规模宽许可图像数据集,其构建流程包括数据源筛选、图像过滤、去重和字幕生成。最终,GPIC 被整理为约 12.9TB、8000 个分片,并提供 100 万、1000 万和 1 亿样本三个嵌套规模,分别对应 GPIC-Nano、GPIC-Lite 和 GPIC-Full,可直接流式传输,用于大规模分布式训练。
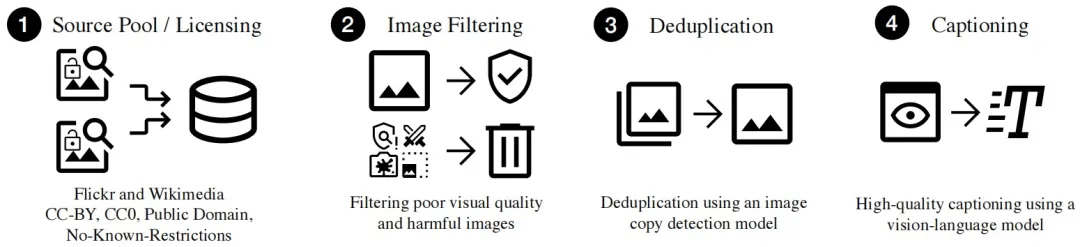
图|数据集构建流程
数据源筛选:研究团队仅从 Flickr 和 Wikimedia 两个平台收集图片,并严格限定在 CC BY、CC0、公有领域和无已知限制这四类授权范围内。研究初始收集到的图片约 1.11 亿张,公开元数据包括来源标识、分辨率、检索时间戳、许可证及归因信息,但不包含原始 URL。GPIC 整体以 MIT 协议发布,单张图像仍遵循原始许可和署名要求。
图像过滤:研究团队先去掉尺寸太小、长宽比异常,或最长边不到 256 像素的图像,再用视觉语言模型Qwen3-VL-4B-Instruct 去除近白、近黑、严重模糊、过曝和欠曝等低质量图像,并筛除潜在不安全内容。

图|因分辨率过低和视觉质量较差而被过滤掉的示例图像。
去重:研究团队先用 SSCD 提取图片特征,再结合 FAISS 找出可能重复的图片。在此基础上,研究团队根据图片相似度和重复簇大小设定去重规则,仅保留每组中分辨率最高的一张。最终共保留约 1.013 亿张图片,并通过 SHA-256 确认其中不存在完全相同的重复文件。

图|不同 SSCD 相似度区间下相似图像对的定性示例。
字幕生成:传统图片数据集的文字描述质量普遍较差,充斥着“photo.jpg”“未命名”等无意义标注。该数据集将字幕分为标签、短描述、中等描述和长描述四类,其中短描述和中等描述分别占 45%,长描述占 9%,标签占 1%。研究团队基于 1520 张图像的人工核验集对多种方案进行比较后,最终选择 Qwen3-VL-4B-Instruct,处理 1 亿张图像约需 1500 个 H100 GPU 小时。
图|字幕生成模型选择。
视觉生成基准评估
为了让不同模型在 GPIC 上的结果具备可比性,研究团队给出了统一的评测指标,也明确标注了哪些做法可能影响结果,并提供了一个可供对照的参考基线。
评测指标
评测时,研究团队需用固定的 5 万条测试字幕生成图像,并与 GPIC 测试集预先计算好的统计量进行比较。这些统计量来自独立测试集,而非训练集。主指标是 FD-DINOv2,即基于 DINOv2 特征计算的 Fréchet Distance;此外还报告精确率、召回率、密度和覆盖率。研究团队还提供了多个 GPIC 子集相对于 Test-1M 的真实数据参考值,供结果对照。
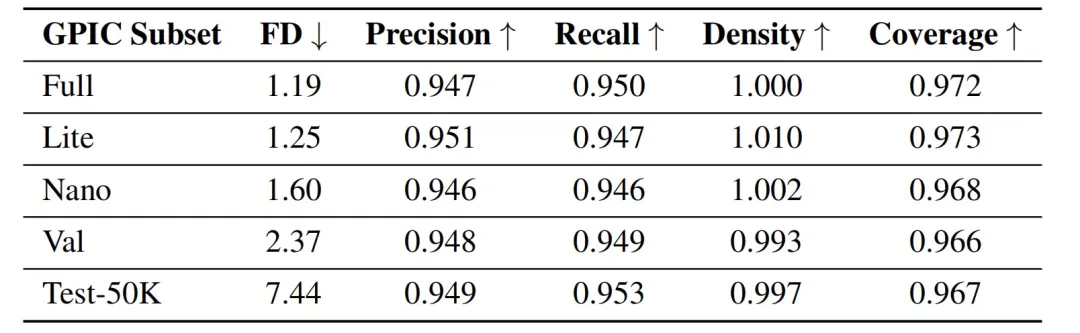
图|基于 DINOv2 特征、以 100 万张 GPIC 测试集为参照评估各个 GPIC 子集得到的 Oracle参考指标
评测边界
不过,研究团队也特别强调,这一基准并不只是“看分数”这么简单。为了避免模型专门针对评测空间进行定向优化,如果训练过程中直接使用 DINOv2 特征、FD-DINOv2 相关损失,或其他专门对齐该评测空间的目标,相关结果都需要单独披露,不纳入标准 GPIC 对比。是否改写评测字幕、是否更换相关模型,以及是否使用更大的辅助模型,也需要在结果中明确说明。
参考基线
在明确评测方式和对比边界之后,研究团队还提供了一个可操作的参考基线,方便后续工作横向比较。具体来说,他们在 GPIC-Full 上训练 JiT-T2I,采用 PixGen-XXL/16,并使用 Qwen3-1.7B 作为文本编码器。该模型在 8 张 H100 上训练 1 个 epoch,耗时约 40 小时;在 CFG=6.25 时取得最佳结果,FD-DINOv2 为 76.25。

图|JiT-T2I 在 GPIC-Full 上训练 1 个 epoch 后的生成样本。
不足和未来方向
目前,GPIC 仍然面临大规模图像语料常见的社会风险,包括模型对训练内容的记忆、平台偏差放大,以及被用于有害生成的潜在风险。研究团队指出,虽然 GPIC 采用冻结 tar 分片形式发布,有助于降低仅依赖 URL 索引分发所带来的链接失效、数据漂移与复现不稳定问题,但残余近重复样本仍难以被彻底消除。未来,如果要进一步提升这类数据集的稳定性与可控性,仍需要持续加强去重、发布审计,并进一步处理偏差与安全风险问题。
与此同时,GPIC 所依赖的合成字幕本身也存在一定误差。尽管这些字幕显著提升了图像语义信息的可用性,但在计数、空间关系和细粒度 OCR 等维度上仍会出现偏差,因此还不能等同于高精度人工标注。研究团队也提示,仍需进一步评估这些误差在全库中的整体分布,以及它们对下游生成模型训练的实际影响。未来,若要继续提升 GPIC 的数据质量,既需要围绕易错类型开展更细粒度的误差分析,并结合更大规模的人工抽检与定向纠错,也需要建立更完整的数据审计、质量评测和安全评估框架。