GPT-Image-2平替:最强开源生图模型来了
2026-04-30 04:25:56 · chineseheadlinenews.com · 来源: 新智元
GPT Image 2之后,最强开源生图模型来了!SenseNova U1正式开源,原生统一理解和生成。它不仅能看懂图,更能“边想边画”,实现连续图文创作输出。这才是通往AGI的正确姿势。

全球AI生图大战正酣!
上一周,OpenAI正式亮出的GPT Image 2,直接让全网目瞪口呆。
不论是带货的直播间、90年代怀旧照片,还是复杂烧脑的知识图,各种神仙级demo正在刷屏。



别问,问就是AI生图已进化到下一个Level了。
短短几天,国内大厂商汤快速反击,亮出了一张全新的底牌:多模态理解生成模型SenseNova U1。
它把“看懂图”和“生成图”这两件事,塞进了同一个大脑。
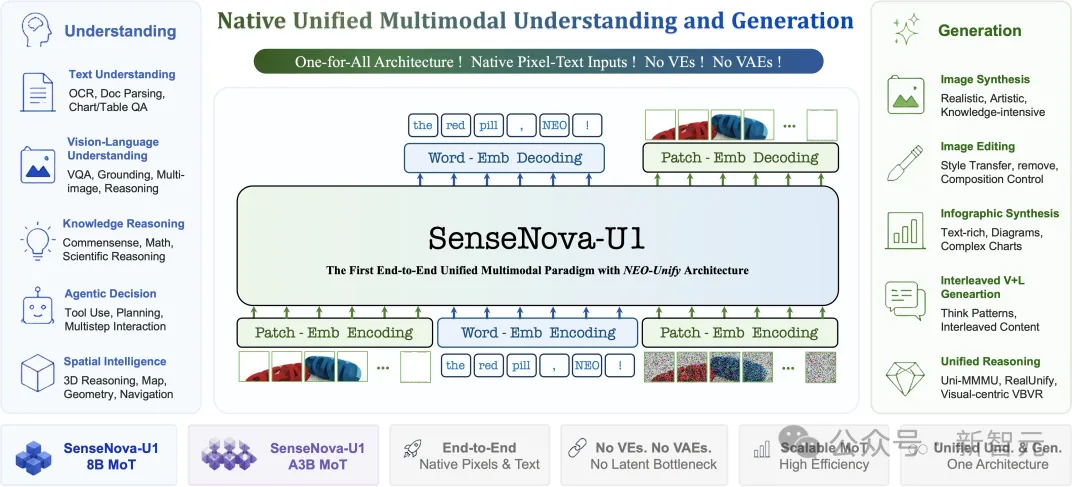
其核心突破便在于,通过自研“单一模型架构”NEO-Unify,实现了理解、推理、生成的统一。
更重磅的是,它没有藏着掖着。
目前,SenseNova U1已在GitHub上全面开源,一大批网友已经开始整花活了。
就连来自Hugging Face、MLS超级智能体实验室等AI大佬纷纷围观和点赞。
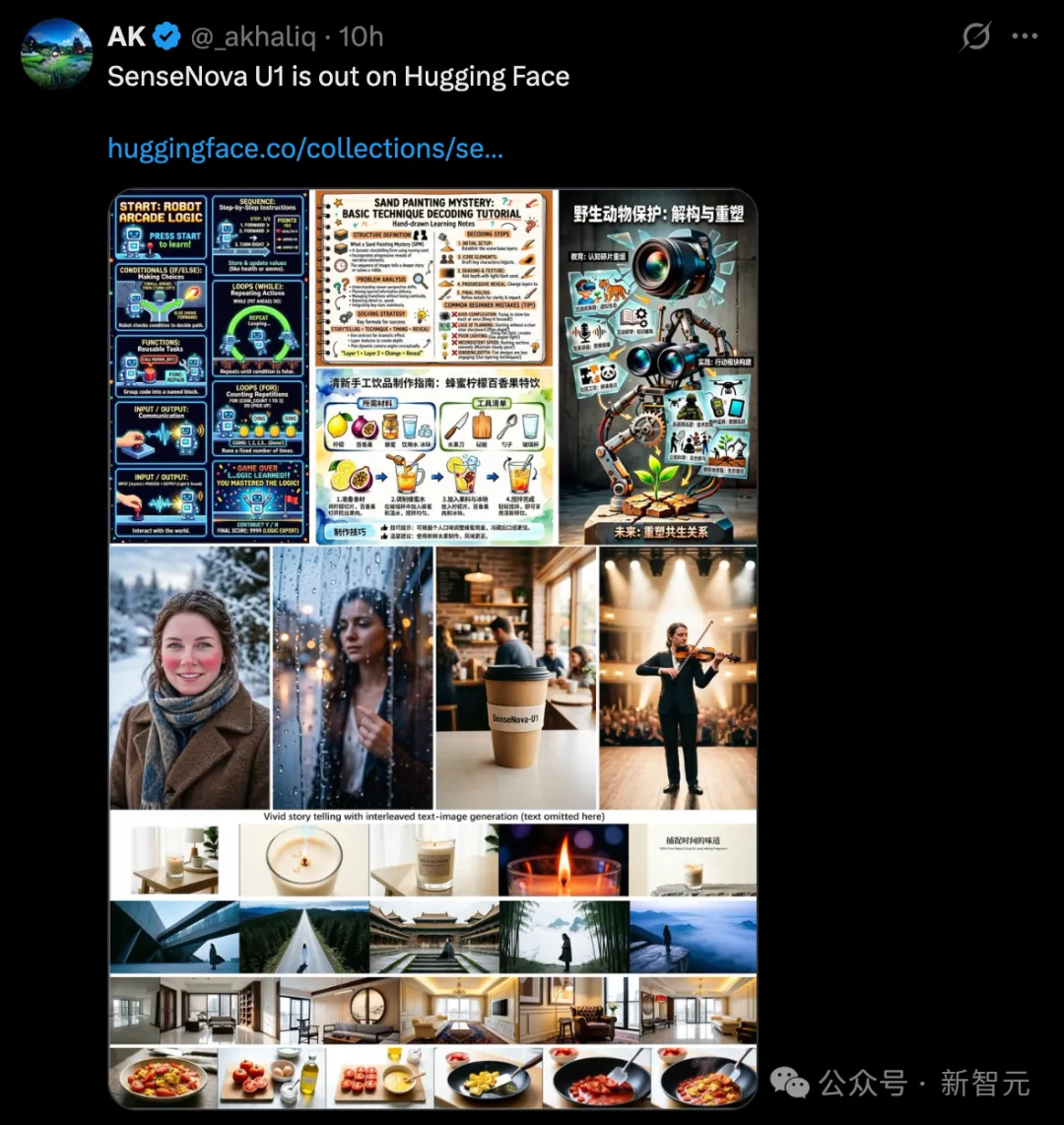

一手实测,信息量巨大
这一次,开源的是SenseNova U1 Lite轻量版系列,一共包含了两个不同规格的模型:
SenseNova-U1-8B-MoT:基于稠密骨干网络
SenseNova-U1-A3B-MoT:基于MoE骨干网络
参数看着“精炼”,但成绩表现远超预期。
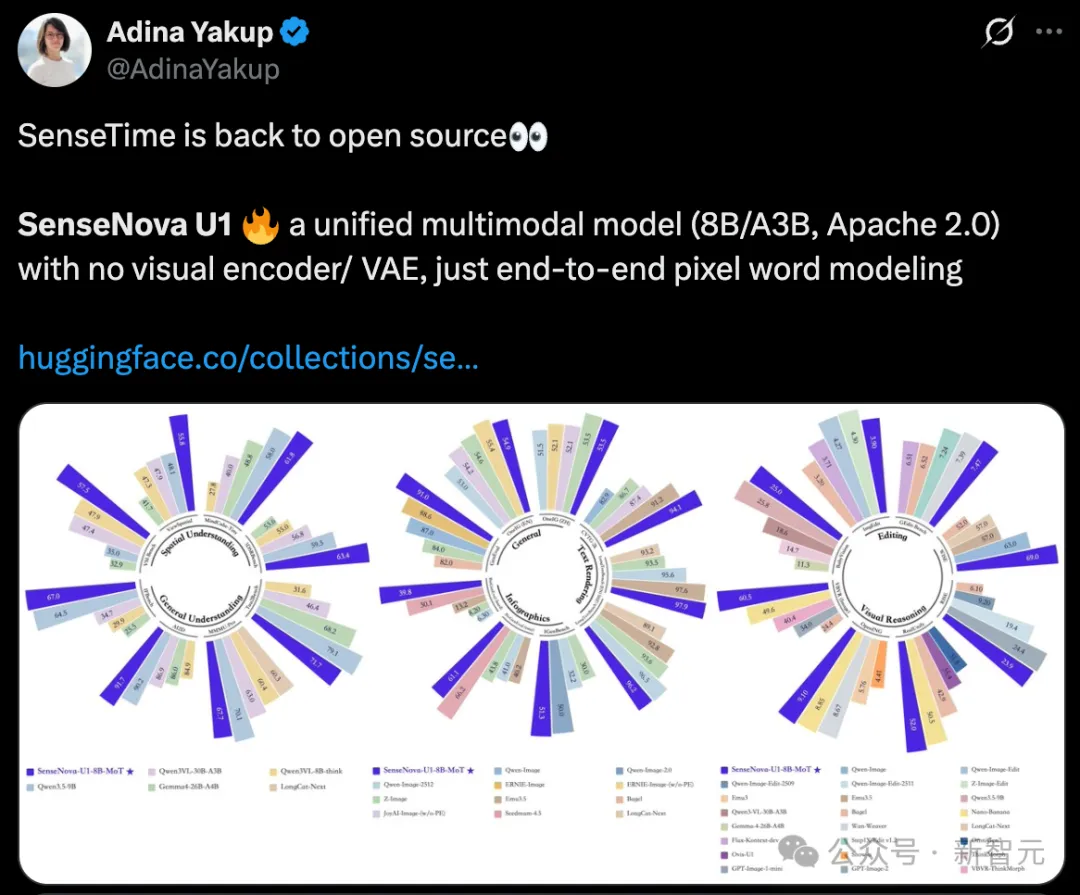
多项基准测试中,U1 Lite爆发出全维度的统治力,达到了同量级开源的SOTA水平。
更令人意外的是,它在多项指标上直逼,甚至超越了部分大型商业闭源模型。
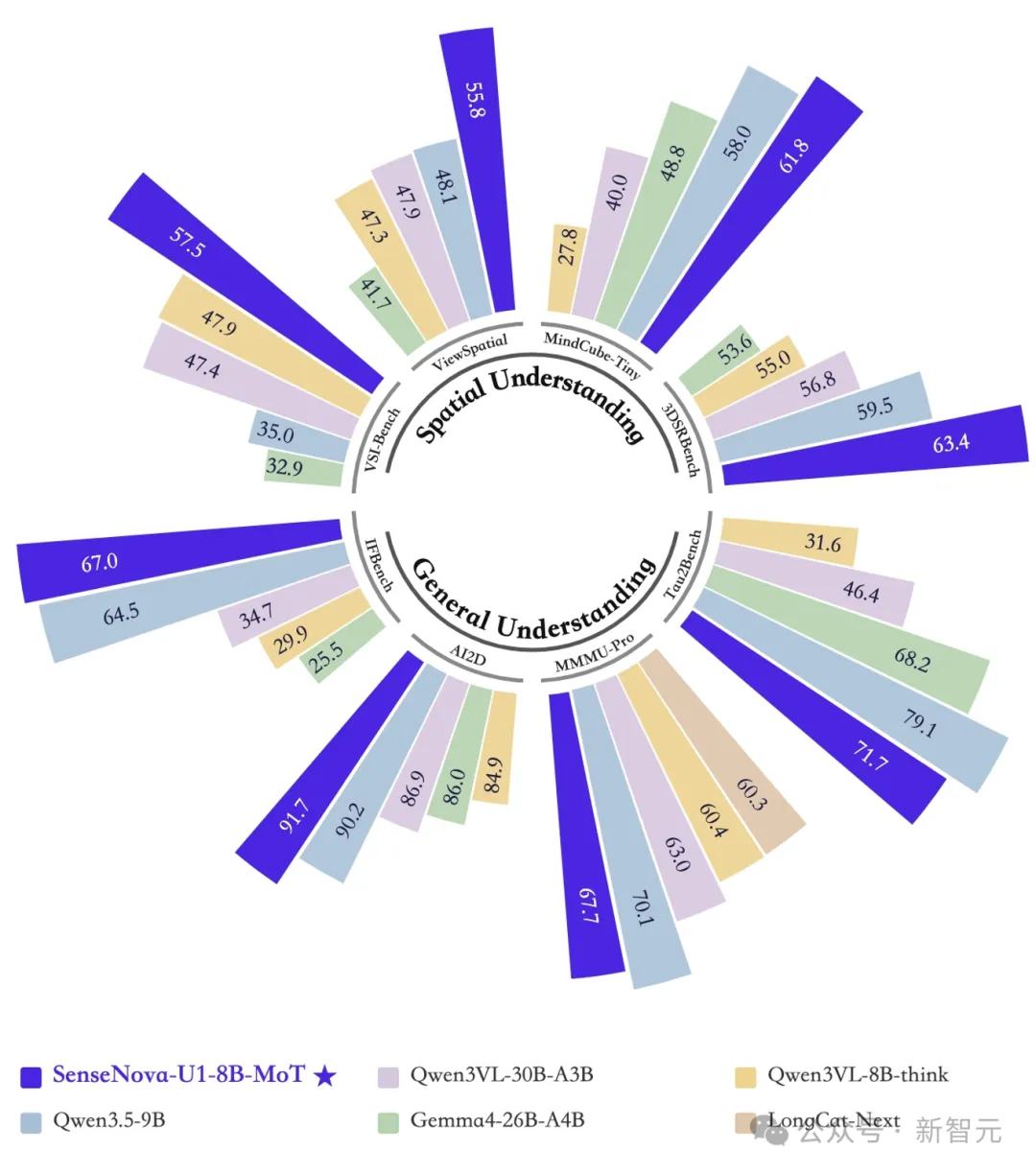
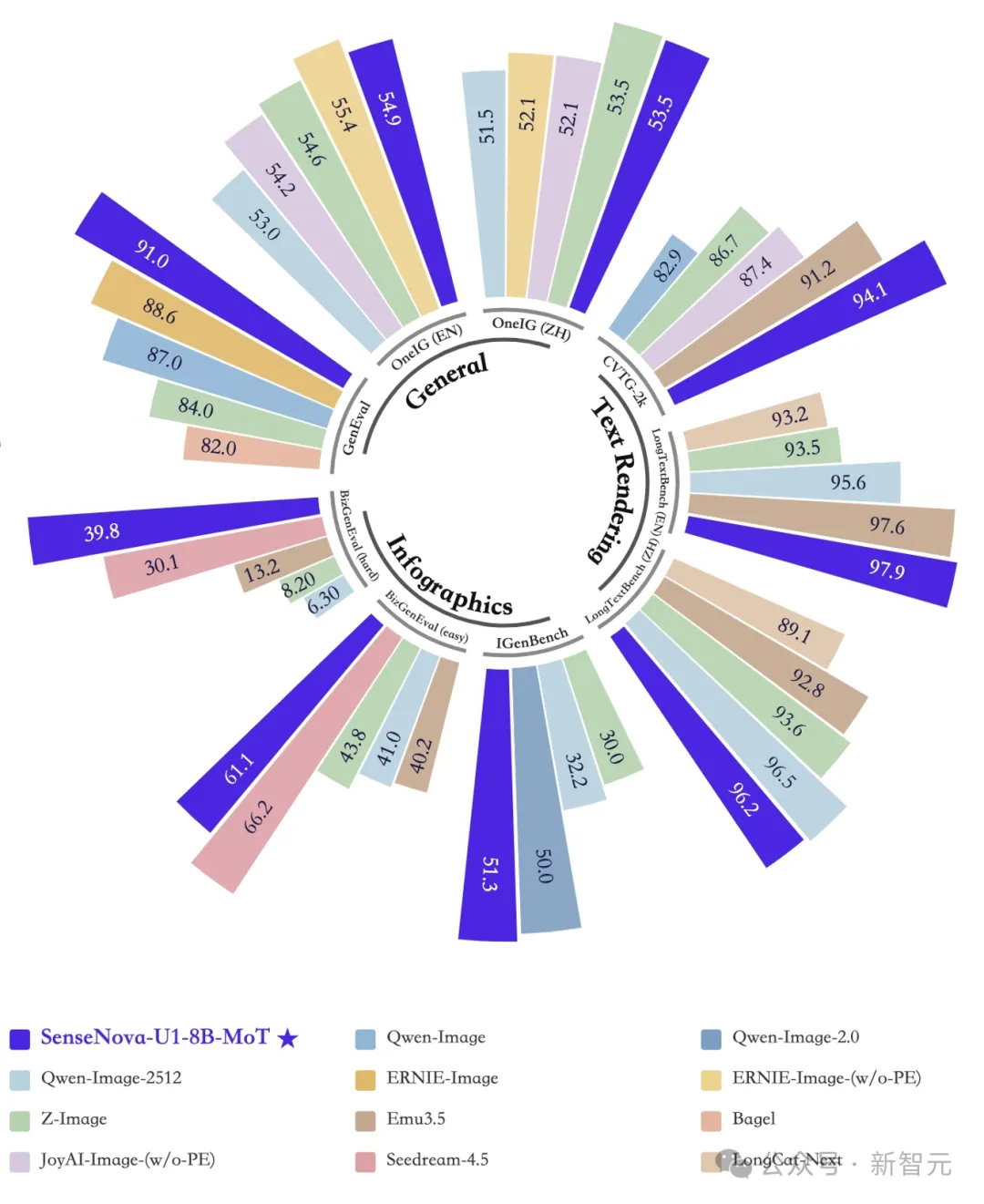
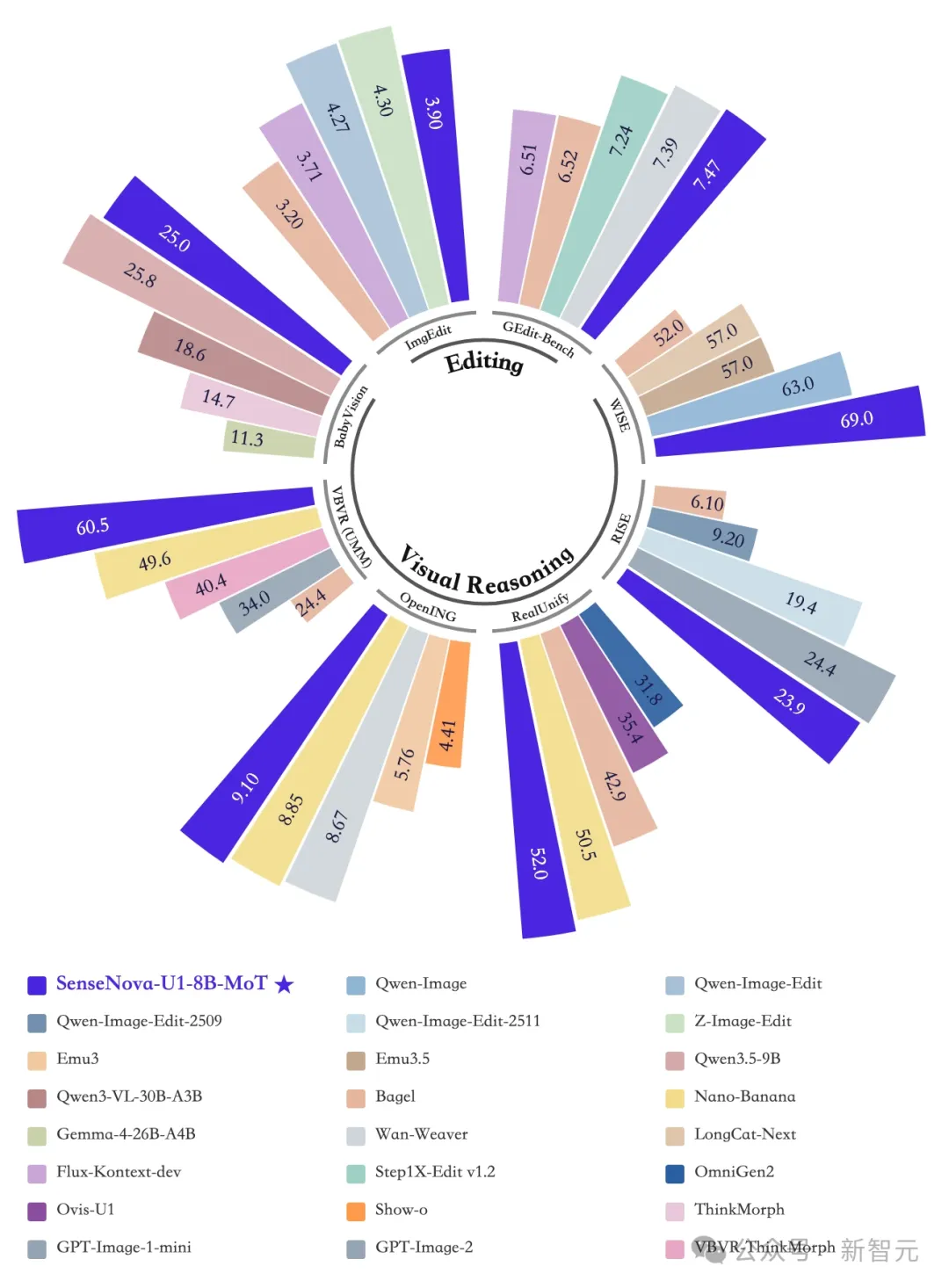
图像理解、图像生成、视觉推理基准测试结果
如今,SenseNova U1上线后,各路大神直呼玩得停不下来。
在正式拆解技术之前,先上真实demo,让你直观感受U1的能力边界。
首先,我们来试一下U1的拿手好戏——连续图文创作输出,它依托于商汤首创的图文交错思维链技术。
先来看第一个demo——手绘哥特式大教堂的步骤拆解图。
令人惊艳的是,在思考的过程中,U1将繁复的建筑美学解构得淋漓尽致,更像是一个拥有深度空间思维的“建筑师”。

过去,对于生图AI而言,保持多张图的一致性曾是最大的难题。
但在这个Demo中,从简练轮廓到华丽成品,建筑的主体结构、飞扶壁的数量、甚至玫瑰窗的格栅纹路,都保持了近乎完美的物理对齐。
这种高度的一致性,让它看起来更像是一份真正具备教学意义的连贯教案。
再比如,一句简单的提示:在海边悬崖上设计一栋图书馆,并且实现多角度呈现。
五个视角,五段文字,五张图,严格交替、逻辑递进——从外到内、从结构到氛围、从白天到黄昏,每一步“想”的内容都直接“画”了出来。
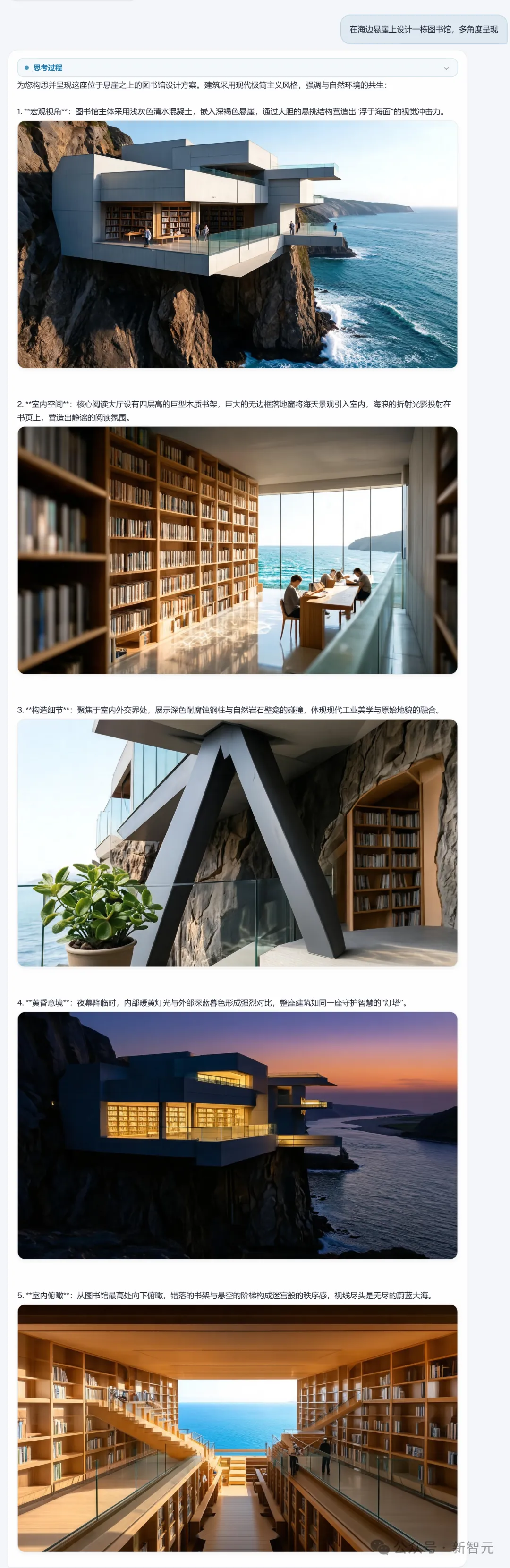
思考和视觉表达同步展开,文字为图像提供设计意图,图像为文字提供视觉验证,二者互为因果。
而且最惊艳的是五张图之间的风格自洽性——建筑形态、材质语言、色彩体系高度统一,明显是在同一个“设计概念”下生成的。
这就是“边想边画”该有的样子。
再来让它生成一段漫画故事,同样是简单几句提示词。
可以看出,四格分镜的叙事节奏精准到位——从赛博废墟中的孤灯、到机器人围观老人读书的荒诞温情、再到泪落书页的微观特写、最后拉到地平线长队的宏大收束,情绪层层递进。
而且,从第一幅画到最后一幅,人物、场景都保持了比较强的一致性。

这恰恰得益于,SenseNova U1具备的原生图文理解生成的能力,天然把图像和文本底层融合信号完整地保留上下文中。
更值得注意的是,U1连续图文创作输出的深度,在每格之间自发补充了大量叙事细节:“静默之塔”的命名、指尖划过岁月痕迹的动作、晶莹泪珠与泛黄书页的对比——
这些文字本身就构成了一部微型科幻小说,图像则精准地将文字中的情感峰值可视化。
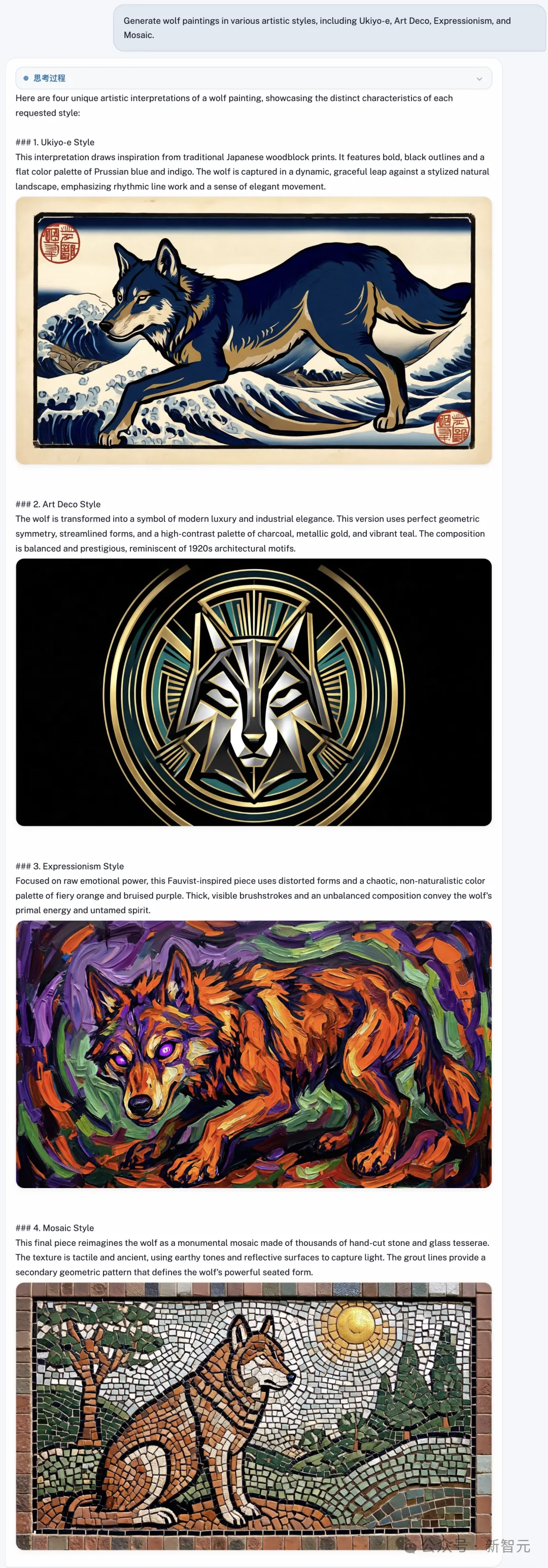
再让U1生成多种艺术风格的绘画,主体就一个狼。
看到结果瞬间被惊艳到了,浮世绘、装饰艺术、表现主义全部呈现。
甚至,U1可以通过连续的图文输出,直出像PPT一样的高维信息图。
它的每一步创作,通过共享上下文实现了统一表征,从而确保了前后环节在结构、细节上的高度一致。


甚至,UI还可以帮你用“图文”方式,解释生活中一些问题,直观又有让人想看下去的欲望。
最后,再来一个抽象、高难度的命题——帮我把“孤独”画出来。要求:画面里绝对不能出现任何人物、表情、文字。
不知,看完之后,你是否感受到了“孤独”?

接着,测一下U1的一键生成信息图。
给它一个简单的提示词:制作一张手冲咖啡的步骤图。
SenseNova U1会先思考,再搜索需要的信息,最后把这句简单的提示词扩写。
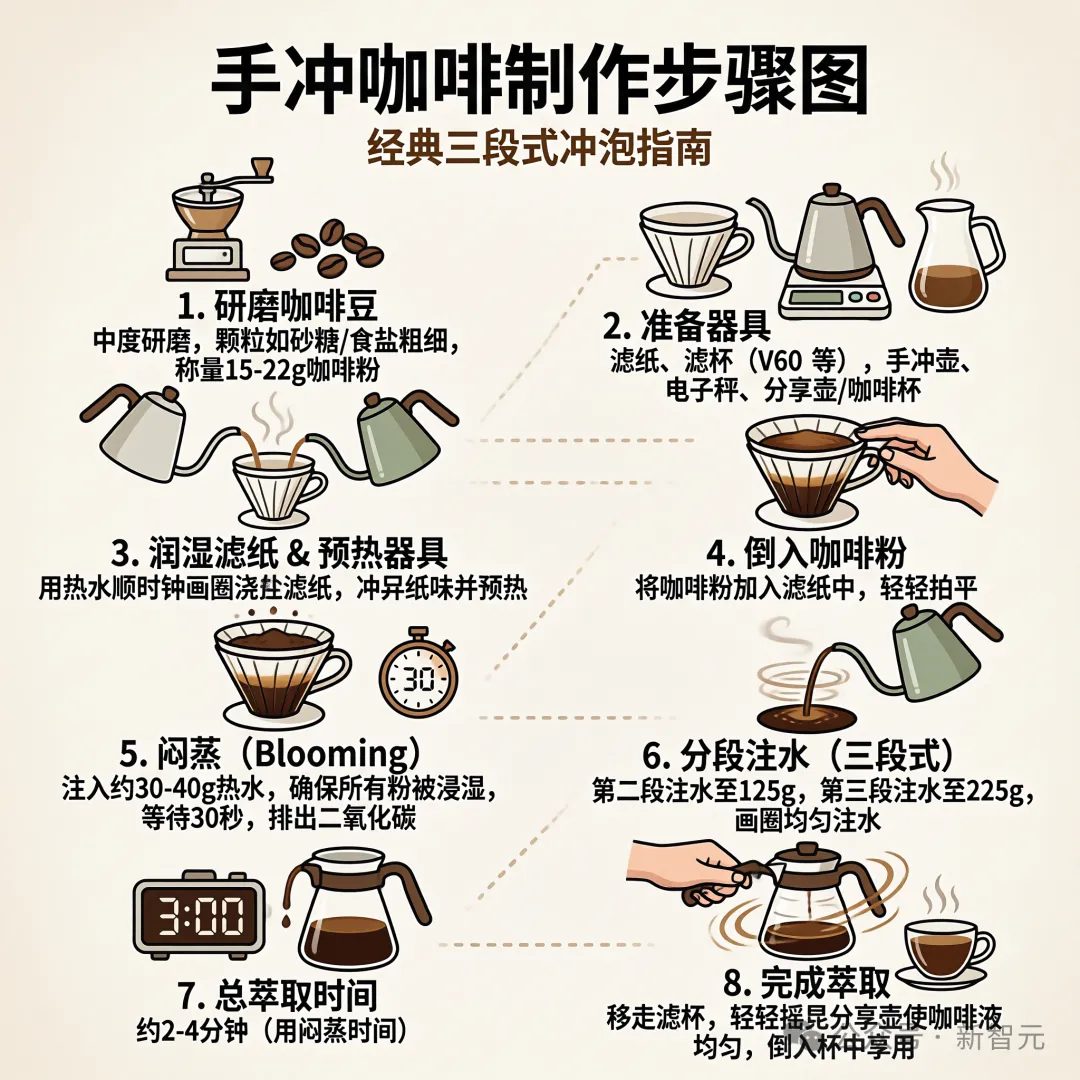
一顿操作之后,生成的信息图内容丰富、详实多了。
这张详细的手冲咖啡步骤图堪称典范,八个步骤环环相扣。
它精准还原了从最初研磨咖啡,到最后完成萃取的全过程。
科学知识的科普,一张图就能搞定。
下面这个demo中,简单一句话:水循环的奇妙旅程。U1在思考的过程中,开始搜索、汇总相关信息。
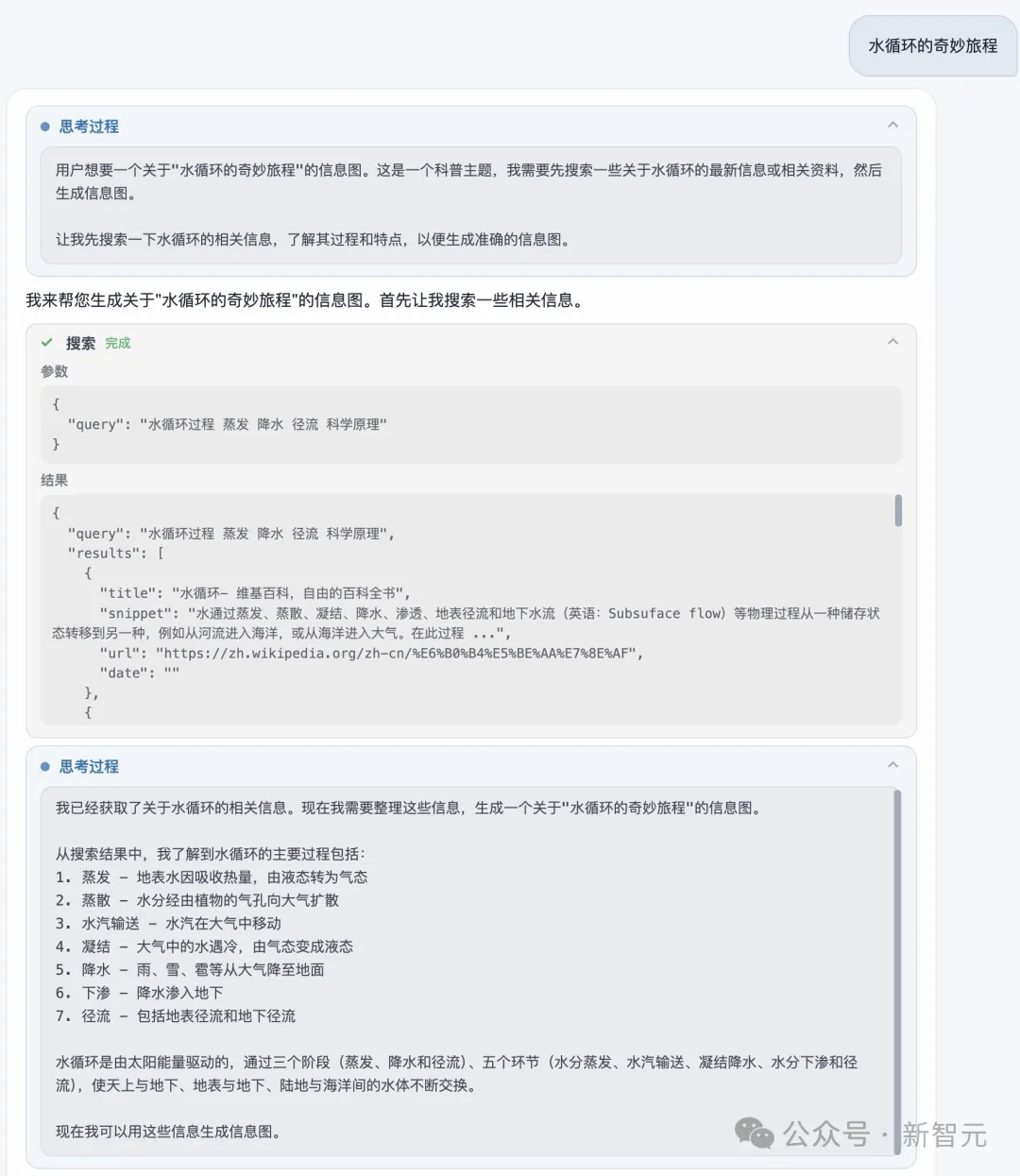
由此,就得到了一张2K超清的一张水循环的奥秘图。
它再次证明了U1在处理复杂、高密度信息的强大能力,复刻了地理学上的所有关键节点——太阳辐射、蒸发、凝结、输送、降水、径流。
而且,AI还极具匠心在每一步创作中,对前一步结构和细节做了精准延续。
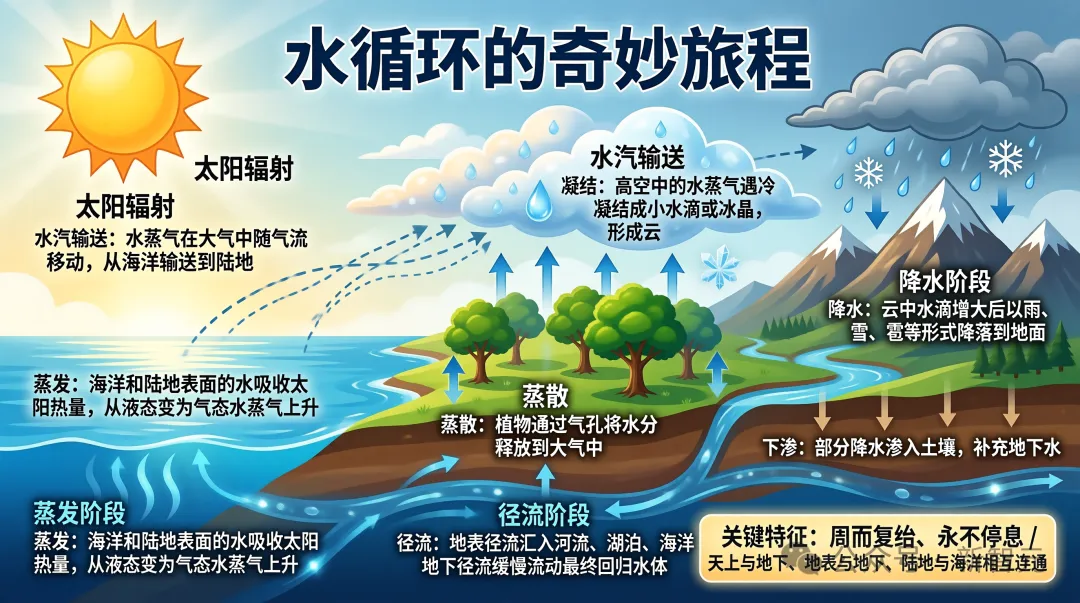
6个字,生成西瓜信息图。
从营养成分、健康益处到食用建议,三大板块的信息密度拉满,直接发到小红书就是完整的推文素材。
六个字的prompt,换来一张可以直接交付的百科信息图。
再比如,U1还能生成这种超复杂,又兼具趣味性的“通勤图鉴”。
它设计的每一个板块都充满了巧思和创意,不仅视觉效果拉满,内涵更是丰富。

U1还可以驾驭不同的艺术风格,比如“波普漫画”。
它可以通过分镜的形式,将信息用独特的视觉语言传递出来,如下便是一个关于职业转型的波普漫画。
这张图简直就是视觉和逻辑的双重炸弹,AI对高密度信息的处理能力在这里得到了极致体现。

估计养毛孩子的打工人,看到下面这张图,都会产生心照不宣的共鸣。

U1还能瞬间拿捏乐高风格的信息图——
一个是乐高环球早餐图,把每一个国家:日本、墨西哥、英国、土耳其、巴西、印度标志性食物精准还原,并将其重构为乐高积木,有趣还有传播价值。
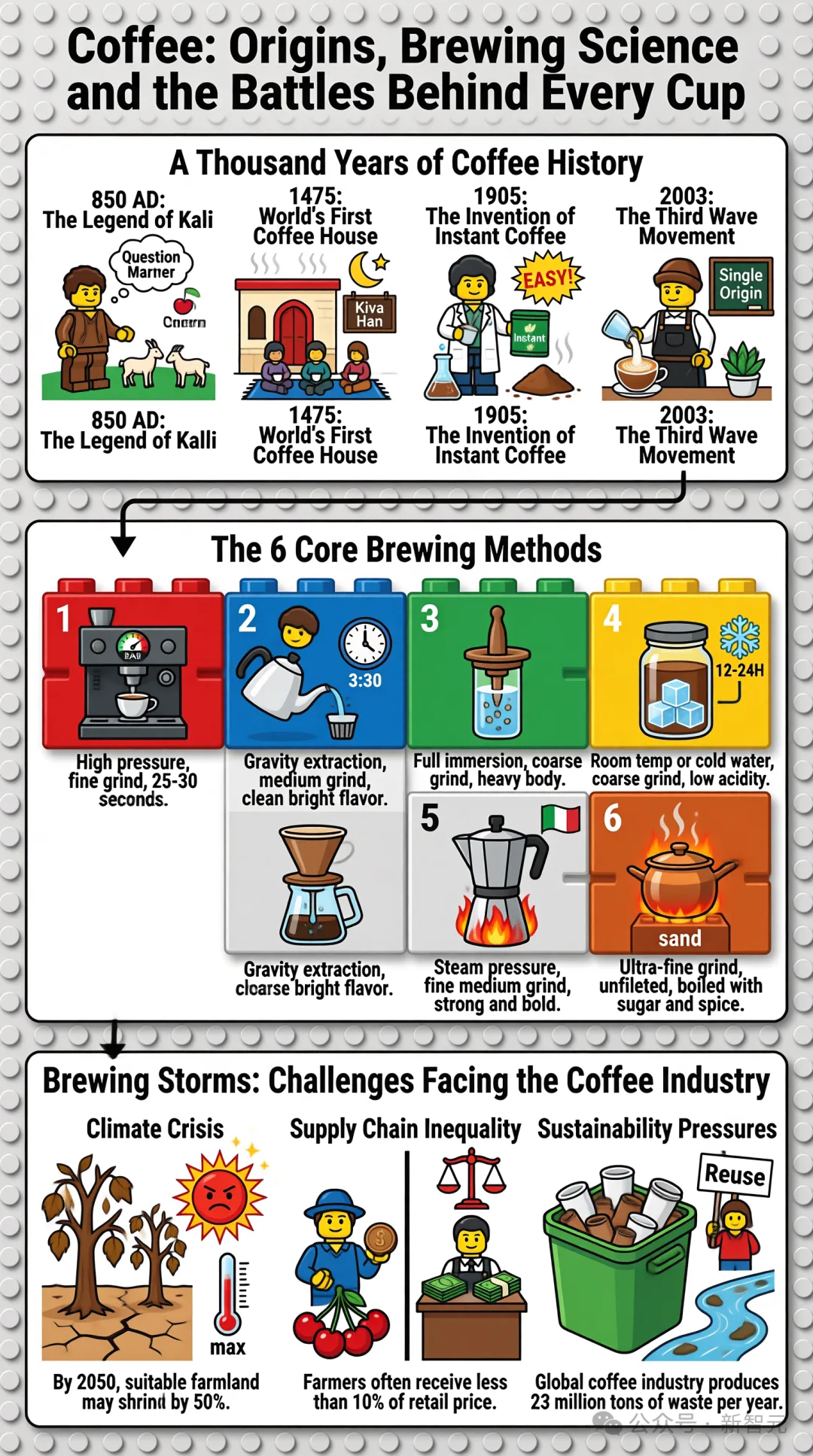
另一个是咖啡百科信息图,从历史发展、冲煮科学、面临挑战,将三大知识板块全部融入了一张图中。

再来一个,以“地球的呼吸碳循环”为主题的垂直分层信息图。

一张羊皮纸,清晰诠释了都市的变化。

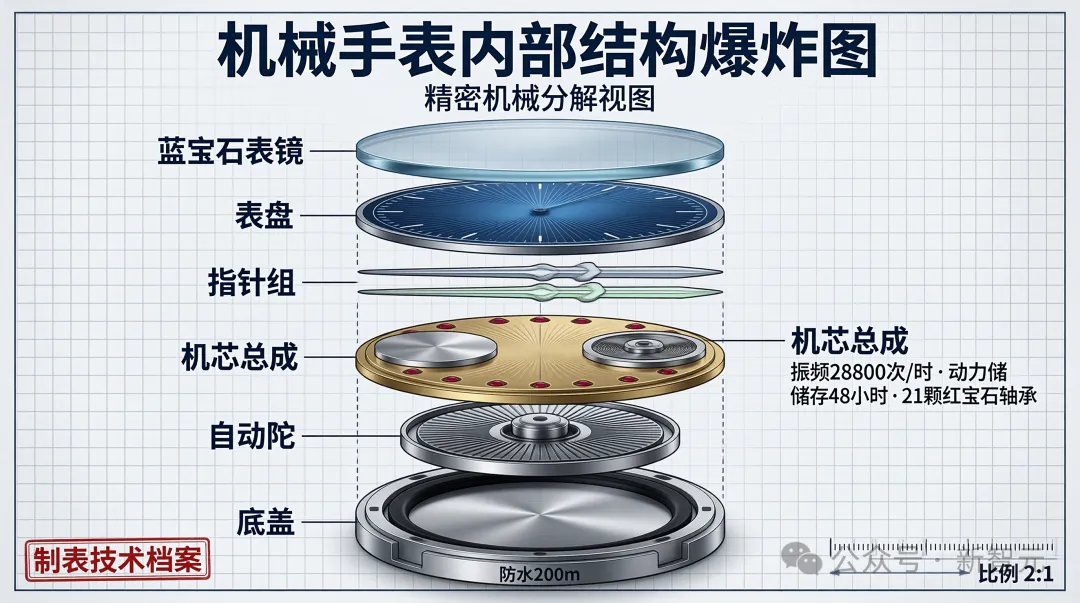
还有经典的结构爆炸图测试,U1也是把细节拆解得丝丝入扣。
原生NEO-Unify架构
最强开源,理解生成一步到位
U1实测表现固然惊艳,但还需回答一个根本问题:为什么一个小参数尺寸的模型能做到这些?
答案藏在架构层。
当前多模态AI模型的主流做法是“拼积木”:用一个视觉编码器(VE)负责“看”,用一个变分自编码器(VAE)负责“画”,中间再接一个大语言模型负责“想”。
三个模块各自独立训练,然后拼在一起协同工作。
这套范式行之有效,但有一个根本性问题——感知和创造是割裂的。
VE把图像压缩成语义特征时,不可避免地丢失了像素级细节;VAE在生成图像时,又得从语义空间重新“猜”回视觉细节。
理解和生成走的是两条路,模型永远在做“翻译”,而不是真正“理解了再画”。
NEO-Unify做了一件看起来很疯狂的事:把VE和VAE都扔了。
它从第一性原理出发,基于一个核心假设——语言和视觉信息本质上是内在关联的,应该被作为统一复合体直接建模。
打个比方,传统架构像是一个团队里有翻译——视觉信息先被翻译成“语言能懂的格式”,处理完再翻译回“图像能用的格式”。每次翻译都有信息损耗,还增加了沟通成本。
NEO-Unify则像是一个天生双语的人,从一开始就同时用视觉和语言思考,不需要翻译这个中间环节。
技术上,NEO-Unify的实现路径是:
引入近似无损的视觉接口,统一图像的输入与输出表示;
采用原生混合Transformer(MoT)架构,让理解分支和生成分支在同一个骨干网络内协同工作;
文本采用自回归交叉熵目标,视觉通过像素流匹配进行优化,二者在统一学习框架下联合训练。
实验证实了一个关键发现,即使冻结理解分支,独立的生成分支依然能从统一表征中恢复细粒度的视觉细节。
这意味着NEO-Unify的统一表征确实同时保留了语义丰富性和像素级保真度。这在以前,被认为是鱼和熊掌不可兼得的。
团队还公布了一组硬指标:NEO-unify(2B)在初步9万步预训练后,在MS COCO 2017上取得31.56 PSNR和0.85 SSIM,接近Flux VAE的32.65和0.91。
考虑到它完全没有依赖任何预训练的VE或VAE,这个数据相当令人瞩目。
经过刚才的实测,我们已见识到了NEO-unify架构加持下,SenseNova U1连续图文创作输出的杀手级能力。
在多个信息图生成基准上,SenseNova U1的生成质量乱杀其他开源模型,甚至可以媲美Qwen-Image 2.0 Pro、Seedream 4.5等闭源模型,并在推理延迟上有明显优势。
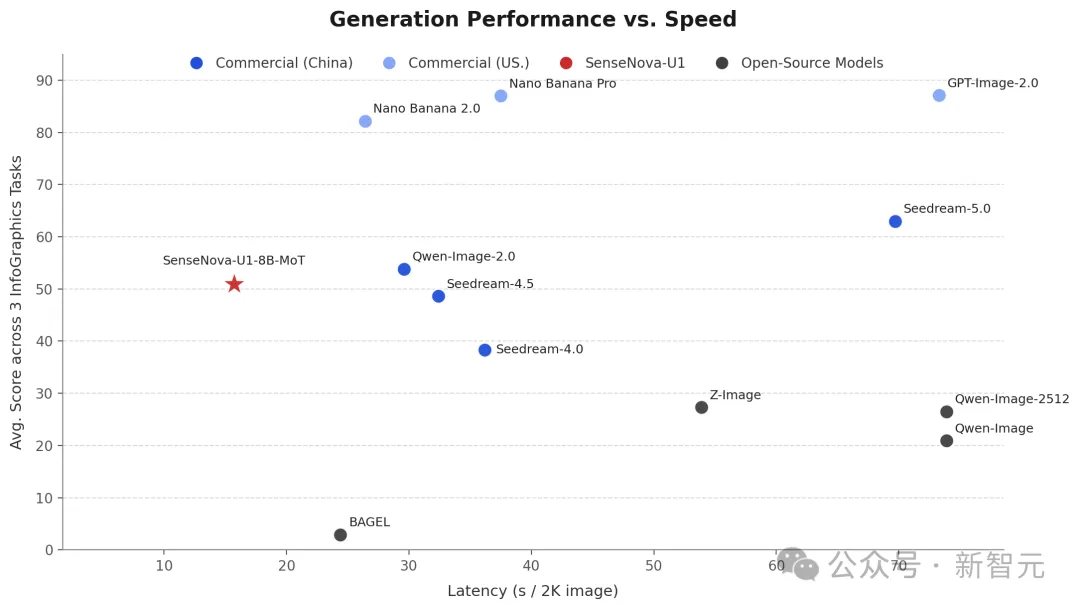
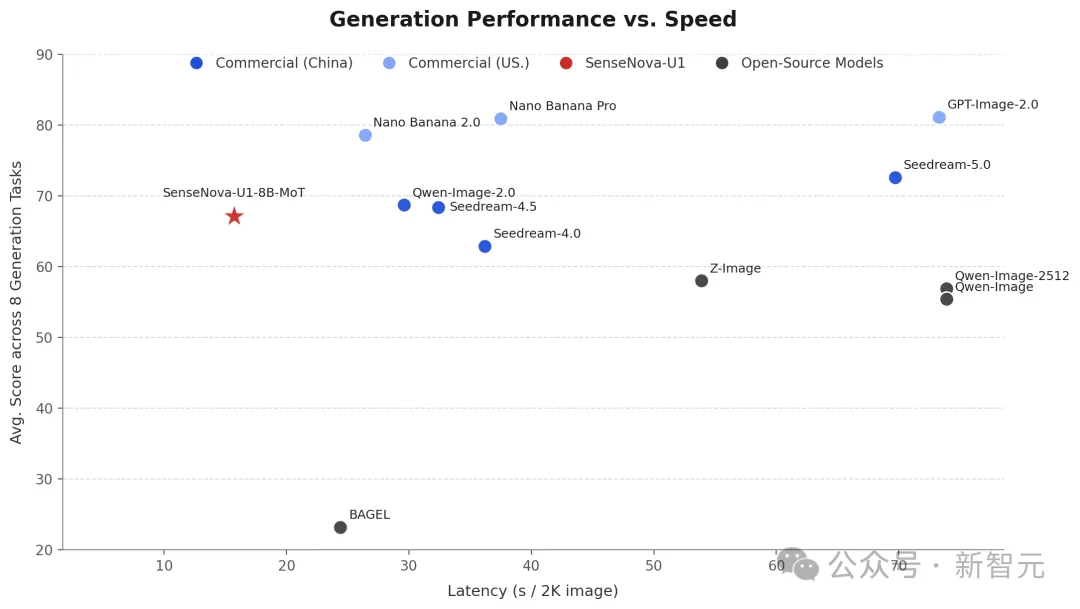
和GPT-Image-2比什么?范式差异才是重点
就在一周前,GPT-Image-2(ChatGPT Images 2.0)横空出世,以近乎完美的文字渲染、多轮编辑和推理驱动的生成。
毫无疑问,GPT-Image-2在创意生图领域树立了新的标杆。
但GPT-Image-2本质上仍然是一个“生图专用模型”,它的核心能力是根狙棠字指令生成高质量图像。
SenseNova U1走的是一条完全不同的路。
它不是“生图模型”,而是一个“原生理解生成统一模型”。
生图只是它能力谱的一部分;它同时具备图像理解、视觉推理、图文交错思考、信息图生成等全维度能力,而且这些能力来自同一个架构、同一次训练、同一个模型。
更关键的,SenseNova U1它不但强,还是开源的。
对于那些需要私有化部署、需要深度定制、需要把多模态能力嵌入自己产品的开发者来说,U1提供了一条GPT-Image-2无法提供的路。
原生统一:通往AGI必经之路
站远一步看,GPT-Image-2引爆的“生图大战”,本质上还是在模态割裂的范式里卷——比谁的文字渲染更准、比谁的分辨率更高、比谁的风格更多样。
这些当然重要,但它们都是“能力增量”,不是“范式变革”。
真正的AGI不会是一堆专用模块的拼接——人类的大脑不是“语言区负责想、视觉区负责看、运动区负责画”三个独立系统的机械组合,而是一个高度统一的认知体。
多模态AI要走向AGI,迟早要走“原生统一”这条路。
NEO-Unify是第一个真正意义上“全扔掉”的原生统一架构,这让它在学术和工程两个维度上都具有独特的坐标价值。
从GitHub和Hugging Face上的早期活跃度来看,NEO-Unify架构本身引发了大量技术讨论,已经有开发者在Apple Silicon上复现了NEO-Unify的toy-scale实验,验证MoT架构在小辨模下的表现。
对于关注多模态统一范式前沿的研究者来说,U1的开源提供了第一个可以实际上手跑的原生统一模型。
8B只是开始
商汤在U1发布时明确表示:当前开源的U1 Lite是轻量版,团队正在沿着NEO-Unify架构继续Scale,更大参数规模的模型将在后续推出。
他们的信念是,基于高效的原生架构,可以用低得多的计算成本达到国际顶尖模型的水平。
这句话的潜台词是:8B已经打到了开源SOTA,当参数量Scale到几十B甚至更大时,NEO-Unify的架构红利会更加显著。
多模态AI正在经历一场“从拼接到统一”的范式迁移。
U1的全球开源,是这条路上的第一步——但从今天的效果来看,这一步已经走得足够扎实。
至于这条路最终通向哪里,答案或许得由全球社区的开发者们一起来写。
代码和权重已经上线了。剩下的,交给你们。