MSRA首测AI从零建仓库:能写、能跑,但不一定对
2026-04-16 08:25:10 · chineseheadlinenews.com · 来源: 量子位
大模型写代码这件事,越来越像“既能写片段,又离真实工程差一截”。
HumanEval、SWE-Bench、ClassEval…… 榜单很多,但多数仍在考函数、类,或在既有仓库里打补丁。
真正让人头疼的 0 到 1,往往是读完一份需求文档,把一整套可部署的代码仓库搭出来:目录怎么拆、依赖怎么对齐、多个文件之间的接口与错误处理怎么一致。

微软亚洲研究院(MSRA)的最近这项工作,把考点直接搬到了这条链路上。论文已被 ACL 2026 高分录用。它不设花哨的“全自动科研”叙事,而是把一个更清晰的问题说透:只给你 README 式的需求说明,AI 能不能从零生成完整仓库,并且过黑盒测试、能部署。
这就是 RepoGenesis:首个面向多语言、仓库级、端到端 Web 微服务生成的基准。
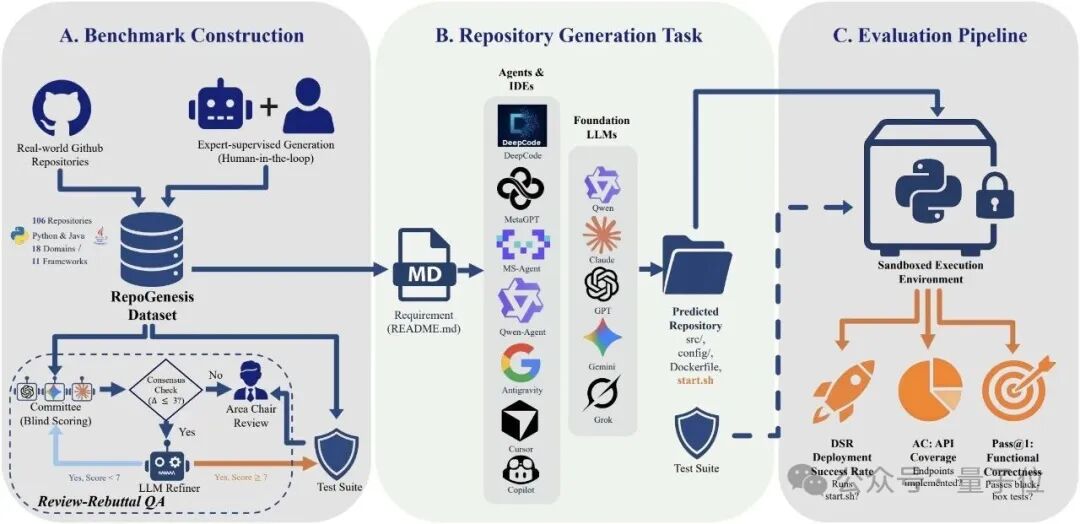
和现有基准比,RepoGenesis 的差异可以用一张“能力矩阵”来理解:不止于函数级或改代码库,而是 Repo-Level、NL2Repo、并且锁定微服务场景;语言上同时覆盖 Python 与 Java。论文里的对比表把这条边界画得很清楚。
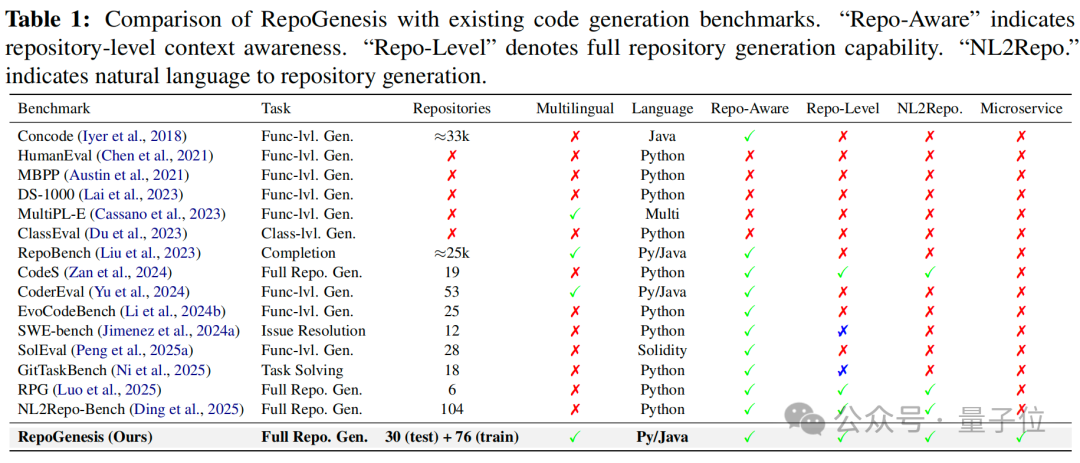
△ RepoGenesis 与主流代码生成基准对比表
把“工程上真实的一单活”拆成可测的流水线
RepoGenesis 的输入非常贴近实际:一份写清功能、API、模式、约束的需求文档(README.md)。模型或 Agent 的输出则是一整套仓库:源码、配置、依赖声明,最后要扛住黑盒测试。
数据规模上,论文给出 106 个仓库(60 Python、46 Java),横跨 18 个领域、11 套框架,共 1258 个 API、2335 条测试。评测子集 Verified 为 30 个仓库(6 个来自可部署的真?GitHub 项目 + 24 个专家监督构造),并另有 76 个仓库构成 Train 子集用于训练与轨迹蒸馏,二者分工在文中写得很明确,避免“既当教练又当裁判”。
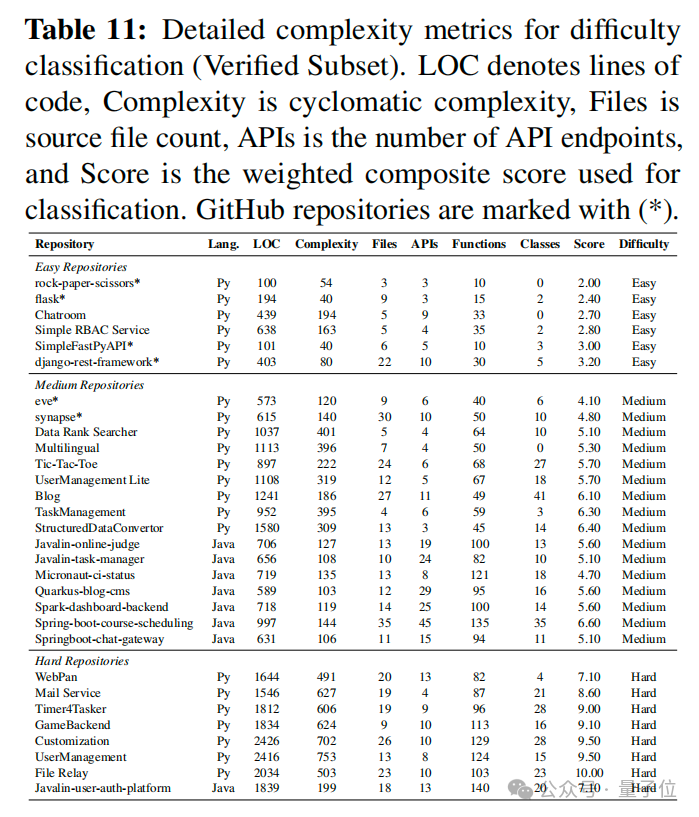
△ Benchmark 构造与 difficulty 分布或数据集统计表骨架
测试怎么信?他们用了很“学术会议”的一套 review-rebuttal 质控:多模型盲评、分歧大时人工 Area Chair 介入、迭代 refined,直到达到约定门槛;Verified 部分还报告了评分者可重复性从近乎随机提升到 Krippendorff’s α≈0.69 这类量化结果。大意只有一个:这不是用几条手写样例糊弄一下,而是尽量让测试本身站得住。
评测不止“过没过”:三根柱子一起看
如果只报准确率,会掩盖“写得像那么回事,但起不来服务”这类工程常态。RepoGenesis 用三个维度同时打分明细:
Pass@1:功能是否正确,能否扛住黑盒测试(最硬)。
API Coverage(AC):需求里的接口,实现覆盖了多少。
Deployment Success Rate(DSR):生成物能不能真的部署跑起来。
论文对 DeepCode、MetaGPT、MS-Agent、Qwen-Agent 等开源 Agent,以及 Antigravity、Cursor、Copilot 等商业 IDE 做了一轮系统评测(多模型配置,主文侧重 GPT-5.1、Claude-Sonnet-4.5、Qwen3-30B 等组合,细节见附录)。
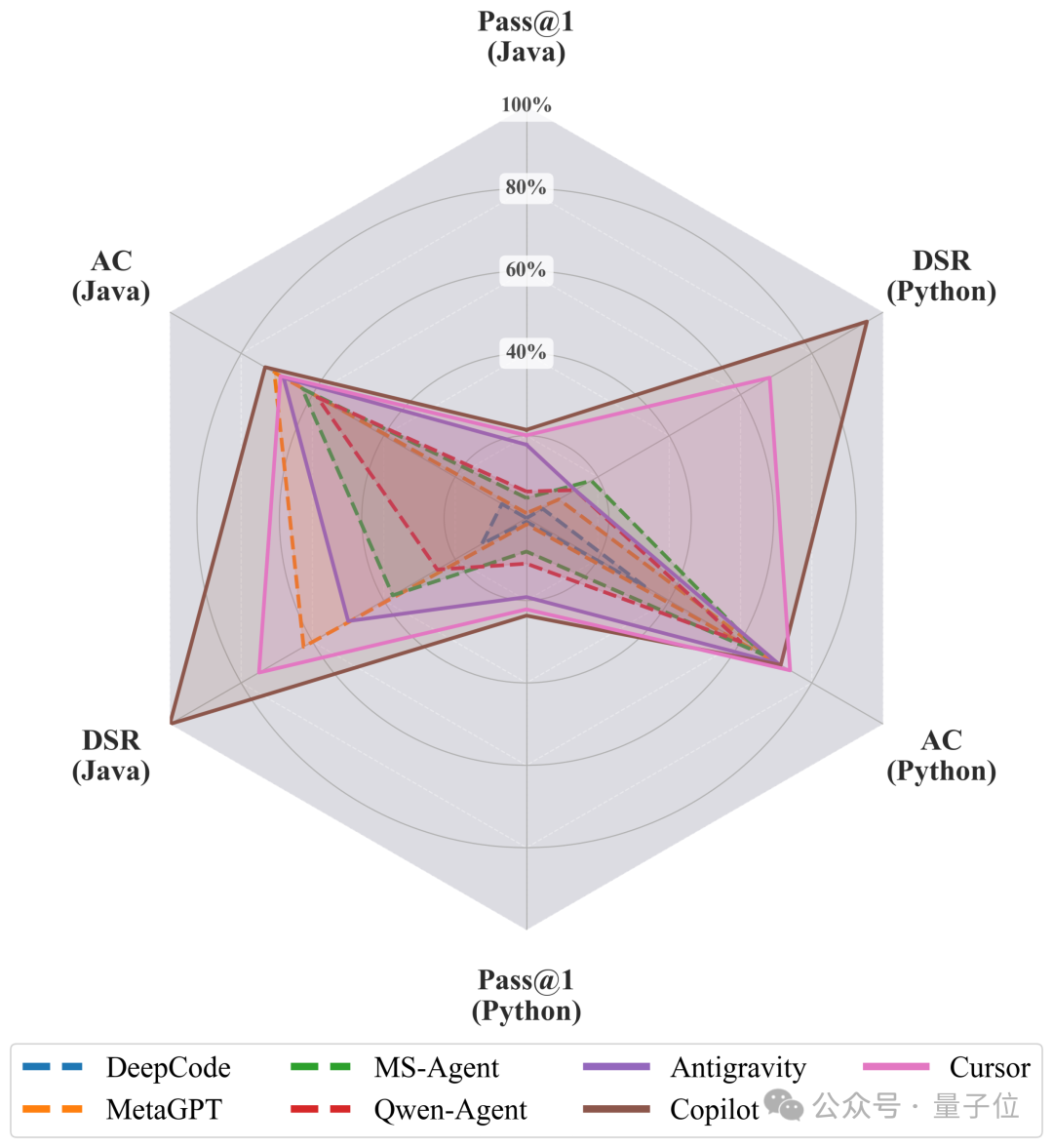
△ 各系统能力雷达
结果里有一组反差很强的数字,几乎可以直接当导语用:接口覆盖率可以冲到很高(摘要中 AC 最高约 73.91%);部署成功率在部分配置下可以非常亮眼(摘要写 DSR 最高可达 100%,与附录中部分 IDE + 模型组合一致)。但即便如此,最强系统的 Pass@1 仍然在 Python 上约 23.67%、Java 上约 21.45%(Copilot+Claude 主表结果)。
翻译成人话:能写、能覆盖接口、甚至能先跑起来,并不等于逻辑全对。架构是否自洽、依赖是否严实、跨文件是否对齐,仍然是瓶颈。
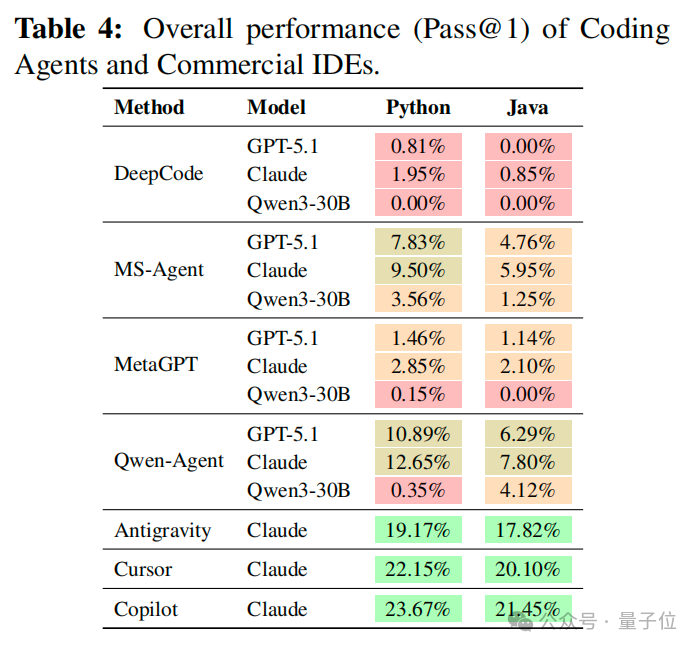
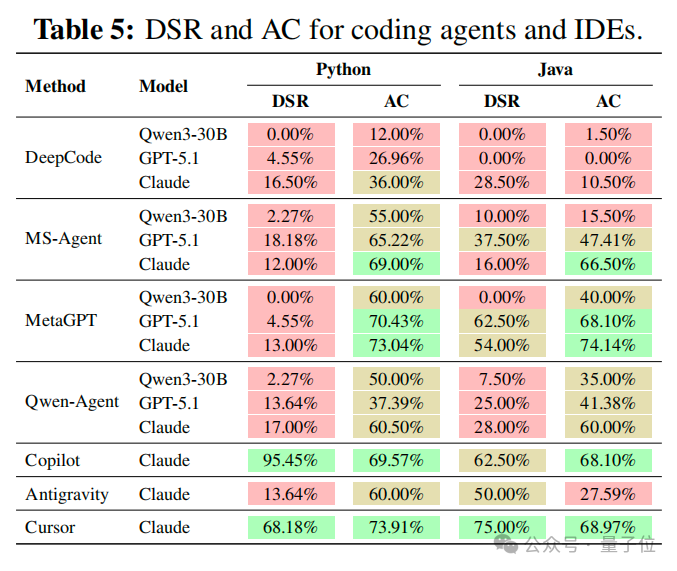
△ Pass@1/DSR-AC 主表
失败长什么样?论文把失败病例粗分成三类,大致占比是:跨文件一致性问题合计约 50.2%,架构连贯性约 26.0%,依赖管理约 23.8%。Java 里依赖相关失败占比更高(表中 44.7%),这也和语言与构建链路的“硬”是一致的。
另一条线:数据能不能把模型“喂上去”?
团队在 MS-Agent 之上扩展了面向微服务仓库生成的 GenesisAgent,用成功轨迹蒸馏出 16,396 条高质量指令微调样本,在 Qwen3-8B 上微调得到 GenesisAgent-8B。在 Verified 上,它与 GPT-5 mini 多指标互有往来、整体同梯队(文中 Table 给出 DSR、AC、Pass@1 的并列对比)。这至少说明一件事:这份基准是值得继续挖的训练信号,而不是一次性榜单。
当然,边界也很坦诚
RepoGenesis 主要覆盖 REST 式 Web 微服务,语言集中在 Python/Java;输入是结构化较好的 README,真实世界里“需求含糊、反复改稿”还没完全模拟;测评以过测为主,可读性、长期可维护性、工程规范仍未系统量化。这些在论文 Limitations 里都写得直白。
结语
RepoGenesis 的意义,未必是把代码生成再吹成一个全能故事,而是把行业里大家每天在做的那一步:从文档到仓库,变成可复现、可对比、可改进的考场。当 ACL 2026 给这类“贴工程”的硬评测一页版面时,讨论或许会少一些口号,多一些能落地的下一代模型与 Agent。