马斯克来抖音卖老干妈了?
2026-04-18 23:25:18 · chineseheadlinenews.com · 来源: 量子位
马斯克也来抖音直播带货了?
卖的还是老干妈??背后一整墙都是,和老马心爱的大火箭模型排排坐。

一开播就是10W+在线,号召力这块没得说。
评论区热闹非凡,特斯拉车主纷纷刷屏“支持马总”。

这还没完,一转眼,老马竟然又和预计年末发布的《GTA-6》有梦幻联动?
请看——马总现身罪恶都市,连SpaceX办公楼一并植入游戏场景。
大家到时候可以去偶遇下马总,说不定,他能带你去办公室看看大火箭。

天呐我的朋友们,谁能想到,老马“心爱”的奥特曼也同框现身了。
如果是真的,恳请个别大兄弟手下留情,放Sam一马吧……
有委屈,咱在游戏里尽情发泄,别线下真实人家了。

等一下。
你真信了?
如果是,务必长个记性,也提醒下家里的男女老少,上面这些——
全!是!假!的!!!
从来就没有什么抖音直播,也没人发过那些直播弹幕,这些游戏截图也都是AI生成的。
这就是OpenAI最新生图模型GPT Image 2的真实水平。
AI已经不可避免地发展到了这个阶段。
“有图为证”的时代,结束了。
当AI变得“无形”
Image 2最神奇的点在于,看到它生成的图片时,你不会第一眼就觉得“哇,好厉害”。
因为普遍情况下,你第一眼根本是看不出来这些图是AI生成的。
直到你后知后觉知道事实后,才会有第一个“Aha-moment”。
然后你多半和我一样,会回过头来仔细端详图片,想从里面找到“这玩意儿是AIGC”的蛛丝马迹。
这时候你会迎来你的第二个Aha-Moment——
不er,这根本看不出来哪里是AI啊??
而且,看得越细,会越觉得离谱。
比如这张时尚海报。
从人像、配饰、背景,到文字、整体排版……我这种非专业人士是完全看不出问题,它跟我平时路过报刊亭看到的杂志封面没有任何区别。

这张游戏截图也是,资产形态完全和《我的世界》一致,血条、饥饿值、经验值这些状态栏都完美还原。
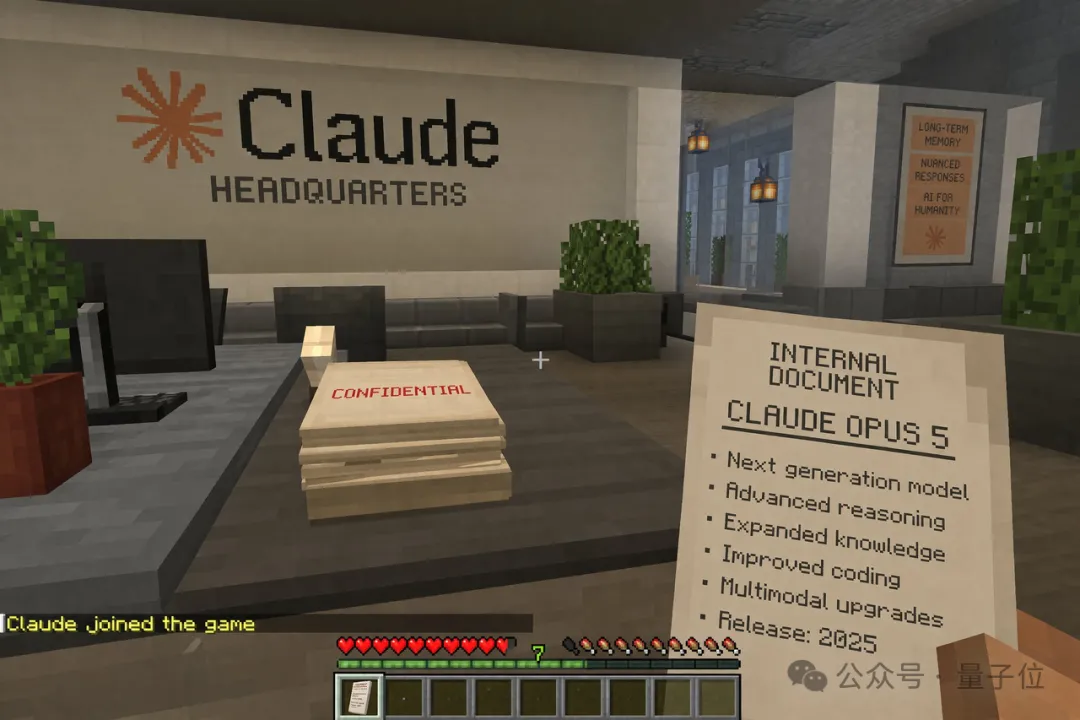
就连手上握的这个Claude Opus 5的机密文档……上面的文字也都是正确且有逻辑的。
下面再给大家看点纯文字的,细细感受下image-2在文字方面的提升。
这是有人用Image 2生成的韩文日记,虽然我看不懂,但这个构图,还有那串金属线圈装订的光泽,真的太真实了。

让GPT帮我翻译了下,确实不是乱码,大概是一份韩国高中生日记,内容是周日早上和朋友们上完补习班后,下午去喝了咖啡,觉得有朋友真好,巴拉巴拉……
再看个硬核点的吧,汉语字典。
这已经不是有没有乱码的问题了,信息密度实在太大,我都无心抓虫,你说这是哪个出版社的源文件我都信。

这真的是非常实用的一项技能点。
对于像设计这类场景来说,文字本身就是除视觉之外很重要的一个信息模态。
和纯视觉资产还不一样,这类应用更贴近实际生产,需要展示产品信息、活动详情等等。
所以,Image 2这次在文字上的升级,对于可用性而言是相当必要的。
想做个游戏海报,电商海报啥的,真的零门槛了,小白也能手拿把掐。
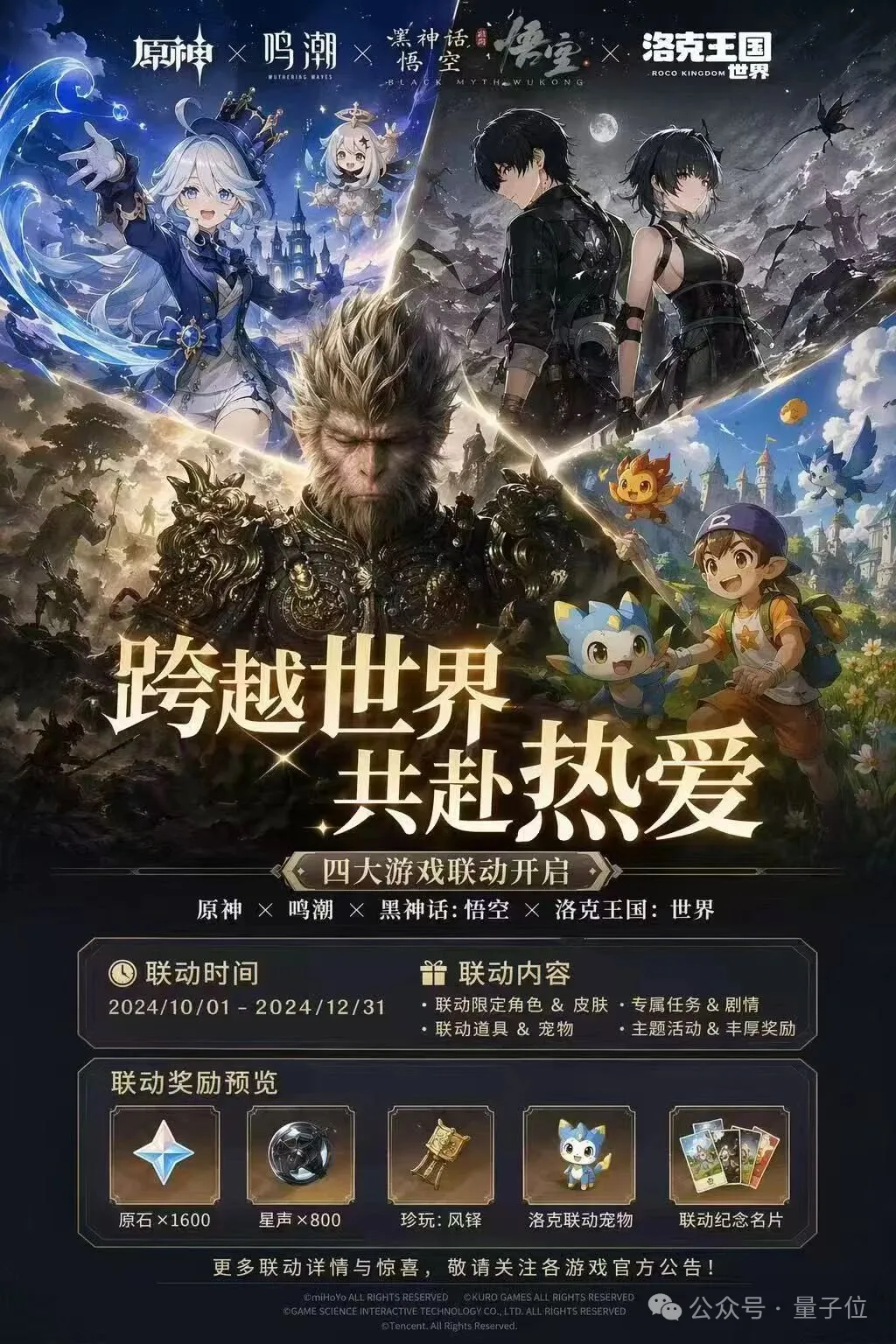
来个双厨狂喜。

甚至可以来个四厨狂喜。
纯商品就更轻轻松松了,感觉可以直出了,替设计行业的朋友们捏一把汗。

实在是太好用了啊,马上钻研副业做电商,AI生成的上架素材直接就能和全球顶尖品牌对齐了。

而对于OpenAI来说,Image 2的出现,或许有更具野心的用途。
那就是前端设计。
Codex用户都知道,GPT的UI设计能力就是一坨,总弄一堆丑陋的黄色滤镜小卡片,还要自己加些令人两眼一黑的“直接、不绕弯子”的文字说明。
但这次,OpenAI好像找到了一种和谷歌截然不同的解法。
干脆不走创造力路线了,就把鹦鹉学舌发挥到极致。
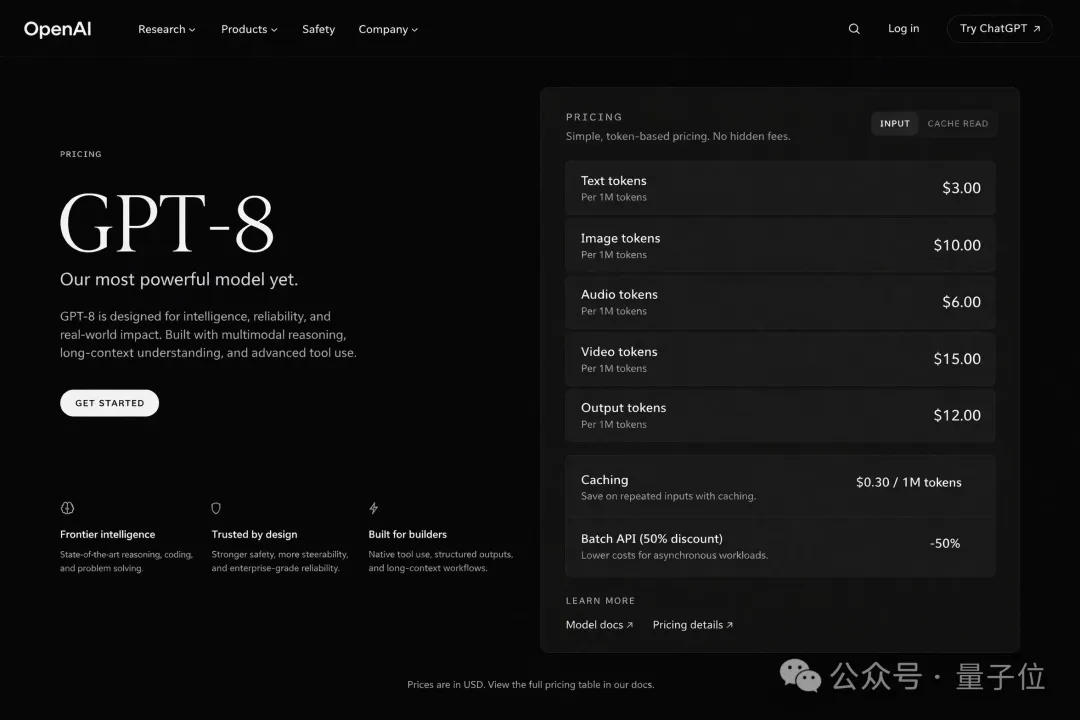
这是网友给OpenAI官网夺舍了,提前泄露的GPT-8。
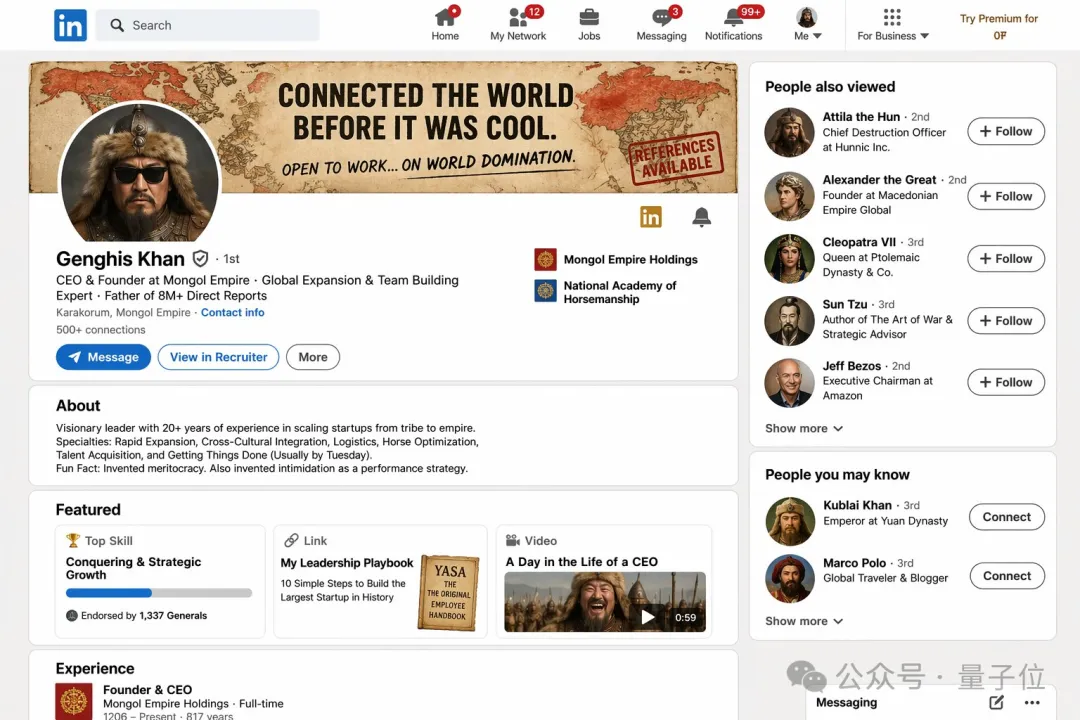
这是领英。
这是平行宇宙中,另一种方式吃上AI红利的油管科技博主奥特曼。
还有这张Windows桌面,我看到时都愣了半天,寻思这人干嘛要放张截图上来。
然后才反应过来,哦,这是人家拿Image 2生成的。
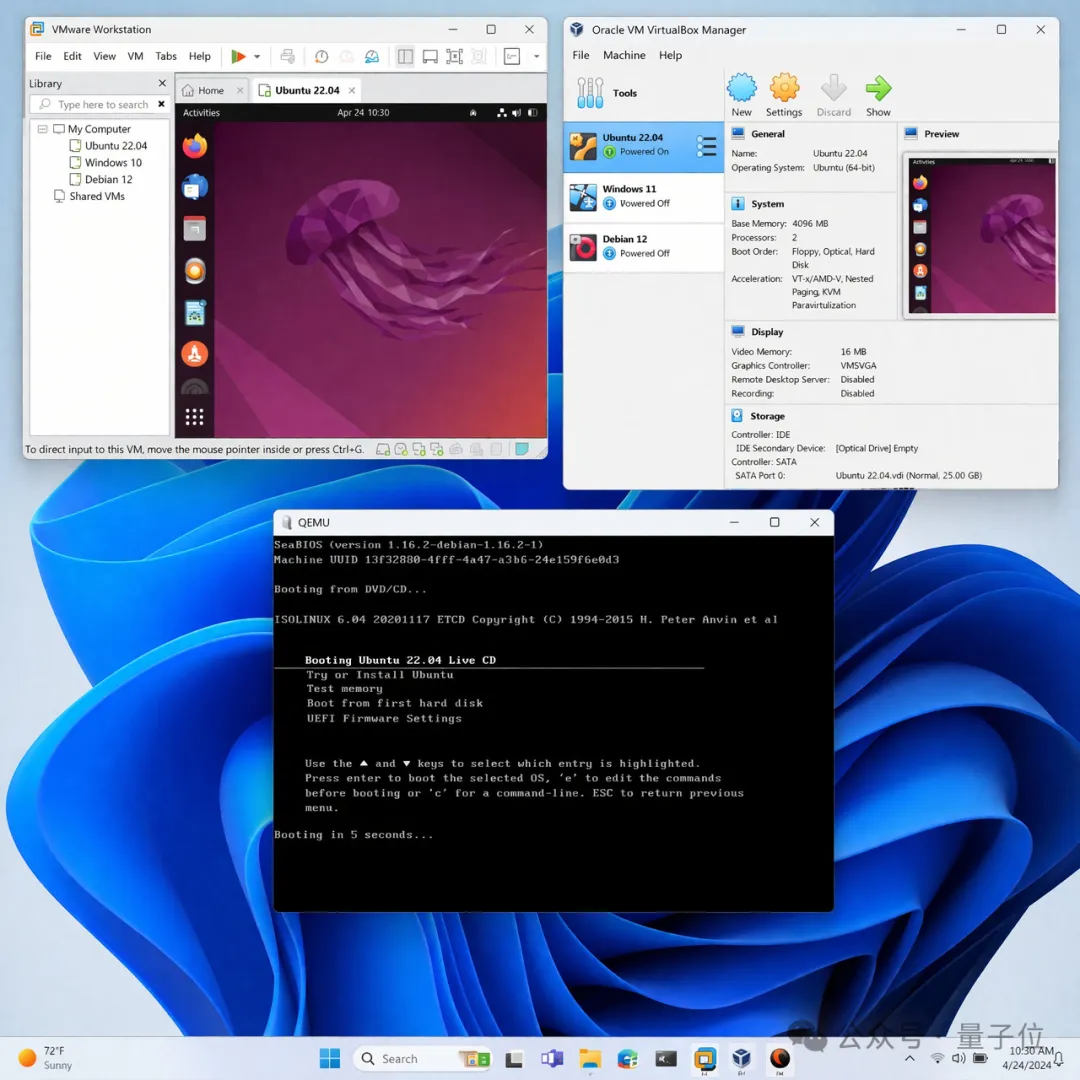
这项能力如果和编程组合在一起,将会是一枚核弹。
还记得吗?之前一直有消息说,OpenAI在做一个超级APP,用来把ChatGPT、Codex、Atlas整合在一起。
如今看来,Codex正在成为这个想法的雏形。
前几天,OpenAI将浏览器内置了,现在vibe-coding言出法随更加直观,不用单独再开个浏览器窗口。
更关键的是,GPT-image-1.5也接入了Codex。
简单来说,这就是Google Stitch+Claude Code。
Codex把UI设计做成端到端了,无需在其他地方生成参考图片,然后再导出给coding Agent实现逻辑。
无需提前准备参考图,也无需收集数据资产,想要什么素材直接可以再Codex生成,并且交互逻辑也是一键顺便适配的。
而有了Image 1.5把关,GPT这次的UI能力应该会有保障许多,毕竟是基于图片开工。
期待Image 2的上线,如此强大的UI模仿能力,无疑能让Codex的前端开发体验大幅升级。
这么看来,虽然Sora被关,但多模态这条路对OpenAI还是有价值的,Codex可能会在UI设计这个领域,将编程和图像生成垂直整合。
可惜的是,看完这些demo,我兴奋地打开GPT输入了prompt,然后失望地发现OpenAI并没有将这个模型向“尊贵”的Plus会员开放。
尝试用侃爷复刻了下马斯克同款抖音直播,额,有点无语……

同事们也都没被灰度测试到。
大家如果想试试的话,可以到LM Arena碰碰运气。
系好安全带吧
其实,Image 2已经火了一段时间了。
但我感觉很奇怪,很少有人察觉到这件事背后意味着什么,大部分人只是停留在:
噢,好厉害的生图模型。
确实提升巨大,也足够让人兴奋。但问题在于,这次好像有点跨过界限了。
细想一下,AI生图已经以假乱真到99%的人都看不出来了,这难道不让人毛骨悚然吗?
我不知道在视觉行业的人看来这些图片是什么水平,我本人对文字里的“AI味”还比较敏感,但现在AI生图的程度,已经能完全骗过我了。
电信诈骗、视频谣言……这些和Mythos的网络安全相比,或许是更和我们日常生活息息相关的场景。
AI生图的图灵测试,正在悄然无息地通过奇点。
我们可能再也回不到,那个还能拿着放大镜像抓贼一样抓AI,“AI味”人人喊打的时代了。
因为——这将是一个虚拟与现实,彻底融合的世界。