“计算胜于知识”的传奇——强化学习之父Sutton
2026-01-17 20:25:24 · chineseheadlinenews.com · 来源: Antonio的AI笔记
“AI研究70年历史给我们的最大教训是:利用计算的通用方法最终总是最有效的。”
—— Rich Sutton, 《The Bitter Lesson》
? 引言:他是谁?为什么我们应该了解他?
在人工智能的星空中,有些名字如同北极星一般,为整个领域指引方向。Richard S. Sutton(人们通常亲切地称呼他为“Rich Sutton”)就是这样一位奠基性人物。
如果你曾经接触过任何与 强化学习(Reinforcement Learning) 相关的内容,无论是 AlphaGo 击败围棋世界冠军、ChatGPT 的 RLHF 训练,还是自动驾驶中的决策算法,你都在使用着 Rich Sutton 奠定的理论基础。
他被誉为“强化学习之父”,这个称号绝非浪得虚名。让我们用一组数据来直观感受他的学术影响力:
? 指标 数值
论文总数 200+ 篇
总引用量 174K+ 次
h-index 100
代表作引用 《Reinforcement Learning: An Introduction》89K+ 次
这些数字背后,是他四十余年如一日对强化学习领域的深耕与坚守。

? 教育背景:从心理学到计算机科学的跨界之旅
Rich Sutton 的学术之路充满了跨学科的色彩,这也许正是他能够创造出如此独特理论体系的原因之一。
本科阶段:心理学的启蒙
Sutton 最初的学术兴趣并非计算机科学,而是心理学。这一背景对他后来的研究产生了深远影响——强化学习的核心概念“奖励”和“惩罚”正是源自心理学中对动物行为学习的研究。
博士阶段:马萨诸塞大学阿默斯特分校
Sutton 在 马萨诸塞大学阿默斯特分校(University of Massachusetts Amherst) 完成了他的博士学位,师从另一位强化学习领域的重要人物 Andrew Barto。
他们的师生关系后来演变为长期的学术合作伙伴关系,共同撰写了那本改变整个领域的经典教科书。
? 有趣的事实:Sutton 的博士论文就是关于时间差分学习(Temporal Difference Learning)的研究,这一主题成为了他毕生研究的核心。
? 职业生涯:从学术殿堂到工业前沿
学术之路:阿尔伯塔大学
Rich Sutton 长期在 加拿大阿尔伯塔大学(University of Alberta) 担任计算机科学教授。在那里,他建立了世界领先的强化学习研究团队,培养了众多该领域的顶尖人才。
阿尔伯塔大学因为 Sutton 的存在,成为了全球强化学习研究的圣地之一。无数学生慕名而来,希望能够在他的指导下学习和研究。
工业实践:DeepMind
除了学术研究,Sutton 还积极参与工业界的AI研究。他曾加入 DeepMind,这家被谷歌收购的人工智能公司以创造出击败人类围棋冠军的 AlphaGo 而闻名世界。
在 DeepMind,Sutton 继续推动强化学习技术的前沿发展,将学术研究与工程实践紧密结合。
Alberta Machine Intelligence Institute(AMII)
Sutton 还是 AMII(阿尔伯塔机器智能研究所) 的核心成员。AMII 是加拿大三大人工智能研究中心之一,与多伦多的 Vector Institute 和蒙特利尔的 Mila 齐名。
? 学术贡献:奠定强化学习的理论基石
? 一、时间差分学习(TD Learning)—— 最具影响力的发明
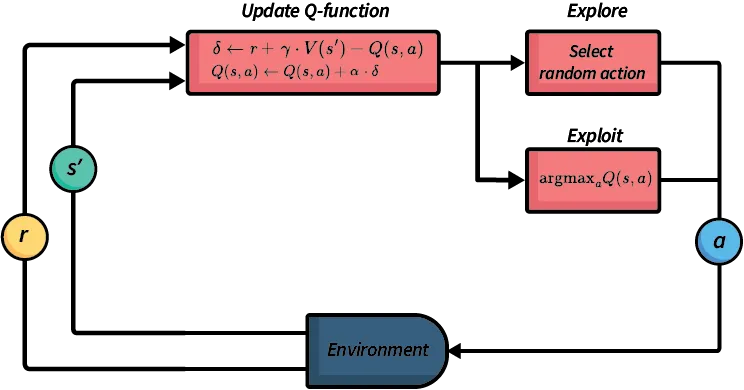
如果只能用一个词来概括 Rich Sutton 对 AI 领域的贡献,那一定是 “时间差分学习”(Temporal Difference Learning,简称 TD Learning)。
什么是时间差分学习?
TD Learning 是一种结合了蒙特卡洛方法和动态规划优点的学习算法。它允许智能体在不需要完整经验序列的情况下,通过逐步更新来学习价值函数。
用一个通俗的比喻:
? 想象你是一名股票交易员
蒙特卡洛方法:等到年底才统计全年收益,然后调整策略
动态规划:需要知道市场的完整运作规律(在现实中不可能)
TD Learning:每天收盘后,根据当天的涨跌和对未来的预期,立即更新你的投资策略
TD Learning 的核心公式优雅而简洁:
V(s) ← V(s) + α[r + γV(s') - V(s)]
这个看似简单的公式,改变了整个机器学习领域的发展方向。
TD Learning 的划时代意义
效率革命:不需要等待完整episode就能学习
在线学习:能够实时更新,适应动态环境
理论基础:为后来的 Q-Learning、SARSA、Actor-Critic 等算法奠定基础
神经科学验证:TD 误差信号与大脑多巴胺神经元的活动模式高度吻合!
? 跨学科影响:神经科学家后来发现,人类大脑中的多巴胺系统正是通过类似 TD Learning 的机制来编码奖励预测误差。这一发现不仅验证了 Sutton 理论的正确性,还为理解大脑学习机制提供了新的视角。
? 二、《Reinforcement Learning: An Introduction》—— 强化学习圣经
89K+ 次引用,这是什么概念?
在学术界,一篇论文如果能够获得 1,000 次引用,就已经可以被视为该领域的“经典”。而 Rich Sutton 与 Andrew Barto 合著的《Reinforcement Learning: An Introduction》获得了超过 40,000 次引用,堪称人工智能领域引用量最高的著作之一。
为什么这本书如此重要?
特点 说明
系统性 首次系统性地整理和呈现强化学习的理论框架
可读性 语言清晰,数学推导严谨但不晦涩
完整性 从基础芭念到高级算法,一书涵盖
前瞻性 提出的很多问题至今仍是研究热点
免费开放 第二版可在网上免费下载,体现学术开放精神
这本书已经成为全球计算机科学、人工智能、机器人学等专业的必读教材。无数研究者正是通过这本书入门强化学习,并在此基础上做出自己的贡献。
? 致敬经典:如果你想进入强化学习领域,这本书是你的第一站。它不仅教授知识,更传递一种思考问题的方式。

? 三、Dyna 架构 —— 模型 + 无模型的完美融合
在强化学习发展的早期,“model-based”和“model-free”方法之间存在明显的分野。
Rich Sutton 提出的 Dyna 架构 优雅地将两者结合在一起:
┌─────────────────┐
│ Environment │
└────────┬────────┘
│ real experience
▼
┌─────────────┐ ┌───────────────┐ ┌─────────────┐
│ Model │ ?─── │ Agent │ ───? │ Policy │
│ (learned) │ │ │ │ (learned) │
└──────┬──────┘ └───────────────┘ └─────────────┘
│ ▲
│ simulated │
│ experience │
└─────────────────────┘
Dyna 的核心思想是:
真实经验学习:从与环境的真实交互中学习
模型学习:同时学习环境的模型
规划(Planning):利用学到的模型进行“脑内模拟”,生成额外的学习经验
这种架构的优势显而易见——它能够充分利用每一次真实交互的数据,同时通过规划来加速学习过程。
? 现实应用:AlphaGo 和 MuZero 的成功很大程度上就是基于类似 Dyna 的思想——结合真实游戏经验和蒙特卡洛树搜索(一种规划方法)来训练强大的策略网络。
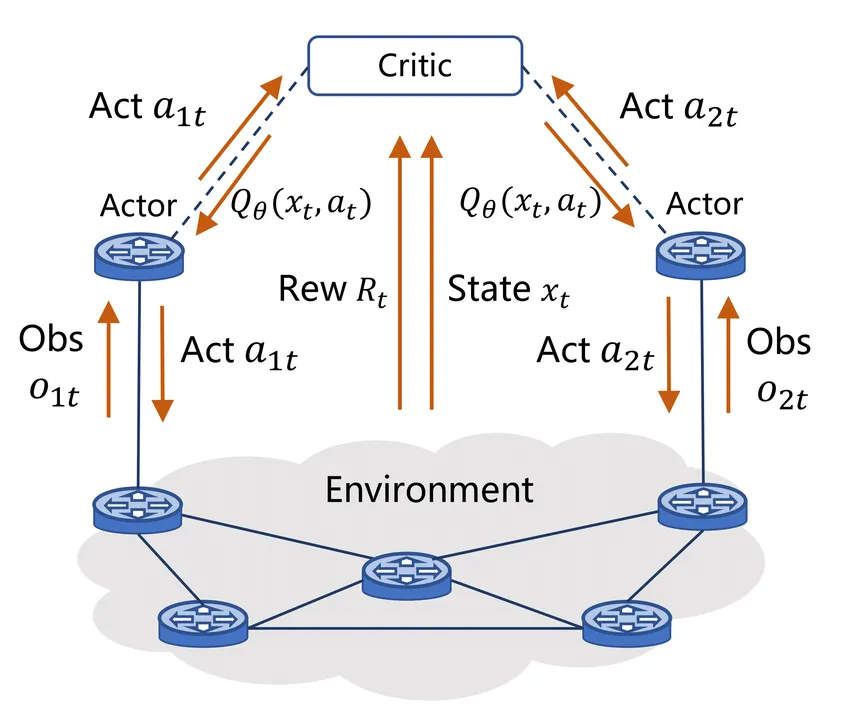
? 四、Actor-Critic 方法 —— 现代深度强化学习的基石
如果你关注过近年来深度强化学习的进展,你一定听说过这些名字:
A3C(Asynchronous Advantage Actor-Critic)
PPO(Proximal Policy Optimization)
SAC(Soft Actor-Critic)
这些当今最流行的深度强化学习算法,都属于 Actor-Critic 方法家族。而这一方法论的系统化阐述,正是来自 Rich Sutton 的研究。
Actor-Critic 的核心思想是同时学习两个组件:
组件作用
Actor(策略) 决定在给定状态下采取什么行动
Critic(价值函数) 评估当前状态的好坏,指导 Actor 改进
这种架构兼具 策略梯度方法 的稳定性和 价值函数方法 的低方差,成为现代深度强化学习的主流范式。
? 五、Policy Gradient Methods —— 策略梯度方法
Sutton 在 1999 年发表的论文《Policy Gradient Methods for Reinforcement Learning with Function Approximation》是另一篇里程碑式的工作。
这篇论文:
首次严格证明了策略梯度定理
建立了策略优化的理论基础
为后来的 TRPO、PPO 等算法奠定了数学根基
正是这些理论工作,使得我们今天能够用深度神经网络来表示策略,并用梯度下降来优化它们。
? 六、Options Framework —— 时间抽象的艺术
人类在解决问题时,往往不会考虑每一个细微的动作,而是在更高的抽象层次上进行规划。比如,当你决定“去厨房倒杯水”时,你不会逐一考虑每一步该迈多长、手臂该如何摆动。
Sutton 提出的 Options Framework 正是为了赋予强化学习智能体这种“时间抽象”能力:
Option = (初始状态集合, 终止条件, 内部策略)
通过 Options,智能体可以学习和使用“技能”级别的行为,而不是原子级别的动作。这大大提高了学习效率和可扩展性。
? 七、“Reward is Enough”—— 一个大胆的科学假说
2021 年,Rich Sutton 与 DeepMind 的同事们在顶级期刊上发表了一篇震动 AI 学术界的论文:《Reward is Enough》。
这篇论文提出了一个极具争议性但发人深省的假说:
? 核心假说:智能的各个方面——包括感知、语言、社会智能等——都可以被理解为最大化奖励的副产品。
换句话说,奖励最大化 可能是实现通用人工智能的充分条件。
这一假说引发了广泛讨论:
支持观点质疑观点
生物进化的本质就是“适应度”最大化人类智能似乎超越了纯粹的奖励追求
简洁性原则:用单一目标解释复杂现象奖励函数的设计本身就需要智能
AlphaGo 等成功案例的启示 内在动机、好奇心难以用奖励解释
无论你是否认同这一假说,它都代表着 Sutton 一贯的风格:敢于提出大胆的、具有根本性的科学问题。
? 《The Bitter Lesson》—— 一篇改变思想的短文
2019 年 3 月,Rich Sutton 在自己的个人网站上发表了一篇名为 《The Bitter Lesson》(苦涩的教训) 的短文。这篇不到 1500 字的文章迅速传遍整个 AI 社区,引发了持续至今的讨论。
核心观点
Sutton 回顾了 AI 发展的 70 年历史,总结出一个“苦涩”的教训:
? “利用计算的通用方法最终总是最有效的,而那些试图编码人类知识的方法最终都会被超越。”
他举了多个例子来支持这一观点:
领域 “人类知识”方法 “利用计算”方法 结果
国际象棋 手工编码策略、开局库深度搜索 + 更多计算深蓝战胜卡斯帕罗夫
围棋 手工特征、专家规则MCTS + 深度学习 + 自我对弈AlphaGo 战胜李世石
计算机视觉 手工设计特征(SIFT、HOG)深度神经网络 + 大数据ImageNet 革命
语音识别 语言学规则、手工模型深度学习 + 大规模数据准确率飙升
自然语言处理 语法规则、知识库Transformer + 预训练GPT 时代的到来
为什么这个教训是“苦涩的”?
Sutton 坦诚地指出,这个教训之所以“苦涩”,是因为:
研究者的自尊心:我们喜欢认为自己的领域知识和洞察力很重要
短期 vs 长期:在计算资源有限时,人类知识确实有帮助
可解释性:基于人类知识的系统更容易理解和调试
工作量的“浪费”:很多精心设计的系统最终被暴力方法取代
这对我们意味着什么?
《The Bitter Lesson》对 AI 研究者和实践者有着深刻的启示:
押注 Scale:投资于可扩展的通用方法
避免 Hard-coding:不要把人类的先验知识硬编码到系统中
让机器学习:相信数据和计算的力量
谦逊地接受:接受人类直觉并不总是对的
? 反思:从 GPT-3 到 GPT-4 的飞跃,从 Stable Diffusion 到 DALL-E 3 的进化,从 AlphaFold 到 AlphaFold 2 的突破——所有这些最近的 AI 里程碑,无一不在验证 Sutton 在 2019 年提出的这个“苦涩的教训”。
? 学术思想的深度剖析
一、“预测”作为智能的核心
在 Sutton 的学术体系中,预测(Prediction) 占据着核心地位。他认为:
“智能本质上就是做出好的预测的能力。”
这一观点体现在他的多项研究中:
TD Learning:学习预测未来的累积奖励
Horde 架构:同时学习大量关于世界的预测
GVF(General Value Functions):用价值函数来表示各种预测
二、“在线学习”的坚持
与许多现代深度学习方法依赖大规模批量训练不同,Sutton 一直强调 在线学习(Online Learning) 的重要性。
他认为真正的智能系统应该能够:
实时适应:环境变化时立即更新
持续学习:不断从新经验中学习
保留旧知识:在学习新知识的同时不忘记旧知识
这种观点在他最近关于 Continual Learning(持续学习) 的研究中得到了延续。
三、简洁性原则
Sutton 的研究有一个显著特点:追求简洁性。
TD Learning 的更新规则简洁优雅,Policy Gradient 定理形式简明,“Reward is Enough”假说用一个目标统一所有智能——这些都体现了他对简洁性的追求。
正如他在一次演讲中所说:
“如果你的解决方案需要很多复杂的组件,那你可能还没有真正理解问题。”
? 独特的学术品格
一、敢于坚持不流行的观点
在 AI 研究经历多次“寒冬”的年代,当神经网络被主流学术界冷落时,Sutton 依然坚持研究强化学习和神经网络的结合。这种坚持最终在深度强化学习时代得到了回报。
二、开放与分享
Sutton 坚持学术开放:
《Reinforcement Learning: An Introduction》免费在线提供
在个人网站上分享研究想法和代码
积极参与学术社区讨论
三、跨学科思维
从心理学到计算机科学,从神经科学到控制论,Sutton 的研究始终保持着跨学科的视野。这使他能够从不同角度审视问题,提出独特的解决方案。
? 对 AI 发展的深远影响
对学术研究的影响
Rich Sutton 的工作直接或间接地催生了无数后续研究:
DQN(Deep Q-Network):将深度学习与 Q-Learning 结合,开启深度强化学习时代
AlphaGo / AlphaZero / MuZero:将强化学习推向新高度
ChatGPT 的 RLHF:用强化学习来对齐大语言模型
机器人控制:从模拟到真实世界的迁移
对工业界的影响
强化学习已经在多个领域落地:
领域应用
游戏 AlphaGo、OpenAI Five、Dota 2 AI
推荐系统 个性化推荐、广告投放优化
自动驾驶 决策规划、仿真训练
机器人 机械臂控制、行走平衡
芯片设计 Google 的芯片布局优化
数据中心 DeepMind 为谷歌节省 40% 制冷能耗
? 我的观点与分析
为什么 Sutton 的贡献如此持久?
回顾 AI 发展史,很多技术都是“各领风骚三五年”,但 Sutton 的核心贡献——TD Learning、Policy Gradient、强化学习的基本框架——历经数十年仍然是该领域的基石。
我认为原因在于:
瞄准根本问题:Sutton 研究的是智能的“学习”本质,而不是特定任务
数学优雅:他的理论有着扎实的数学基础,经得起时间检验
通用性:他的方法不依赖于特定领域的知识
与时俱进:他不断更新自己的想法,拥抱新的计算范式
对当下 AI 研究者的启示
关注基础问题:不要只追求在特定任务上的 SOTA,要思考更根本的问题
保持简洁:复杂的方法往往只是过渡方案
相信 Scale:计算和数据的力量可能超乎想象
跨学科思考:从其他领域汲取灵感
敢于坚持:如果你相信一个方向,就坚持下去
对 AI 未来发展的思考
如果 “Reward is Enough”假说是正确的,那么 AGI(通用人工智能)的实现可能比我们想象的更近。
但这也带来了新的问题:
如何设计正确的奖励函数?
如何确保 AI 的目标与人类价值观对齐?
如何在追求能力的同时保证安全?
这些问题的回答,将决定 AI 时代的走向。
? 结语:站在巨人的肩膀上
Rich Sutton 用四十多年的研究生涯,为强化学习这一领域奠定了坚实的理论基础。他的工作不仅推动了学术进步,更直接影响了从 AlphaGo 到 ChatGPT 的技术革命。
他的故事告诉我们:
? 真正的学术贡献,不在于发表了多少论文,而在于提出了什么样的问题,以及给出了什么样的回答。
在这个 AI 飞速发展的时代,每一位研究者、工程师、创业者,都在某种程度上受益于 Sutton 的工作。
当我们使用 ChatGPT 时,当我们看到机器人学会走路时,当我们被推荐系统精准服务时——我们都应该记住,这一切的背后,有一位叫做 Rich Sutton 的老人,几十年如一日地研究着一个看似简单的问题:
“一个智能体如何通过与环境的交互来学习最优行为?”
这,就是强化学习。 这,就是 Rich Sutton 的毕生追求。