攻克强化学习“最慢一环”
2025-09-13 08:25:24 · chineseheadlinenews.com · 来源: 量子位
强化学习的训练效率,实在是太低了!
随着DeepSeek、GPT-4o、Gemini等模型的激烈角逐,大模型“深度思考”能力的背后,强化学习(RL)无疑是那把最关键的密钥。
然而,这场竞赛的背后,一个巨大的瓶颈正悄然限制着所有玩家的速度——相较于预训练和推理,RL训练更像一个效率低下的“手工作坊”,投入巨大但产出缓慢。
其中,占据超过80%时间的Rollout(响应生成)阶段,由于其内存带宽限制和自回归特性,成为了整个AI基础设施中公认的阿喀琉斯之踵。
如何攻克这块AI基建的最后高地?现在,上海交通大学与字节跳动研究团队给出了一个全新的答案。
该团队联手推出的RhymeRL,从一个被忽视的现象入手,巧妙地将历史数据变废为宝,在不牺牲精度的前提下,将RL训练吞吐量提升了2.6倍。
模型生成的答案存在两大“历史相似性”
该研究团队深入分析了大量RL训练过程,发现在相邻的两个训练周期中,尽管模型权重已经更新,但对于同一个问题(Prompt),模型生成的答案(Rollout)存在两大“历史相似性”:
第一,序列相似性。
新答案“继承”了旧答案的思路,高达95%的历史Token都可以直接复用。
第二,长度分布相似性。
上一轮里,哪些问题让模型“思来想去”,这一轮大概率依旧如此。响应长度的排序惊人地稳定。
该研究团队认为,这种相似性,主要源于PPO/GRPO等主流RL算法为了保证训练稳定而采用的梯度裁剪(Clipping)机制,它让模型的进化变得平滑而有迹可循。
这就好比一个学生,虽然每天都在进步,但他解决同一类型问题的思考路径和草稿篇幅,在短期内是高度相似的。
既然如此,历史的旧草稿能否成为新一轮学习的模版?
针对Rollout阶段的低效现状,提出新框架RhymeRL
基于这一洞察,RhymeRL框架应运而生。
针对Rollout阶段的低效现状,它包含两大核心利器:
HistoSpec和HistoPipe。
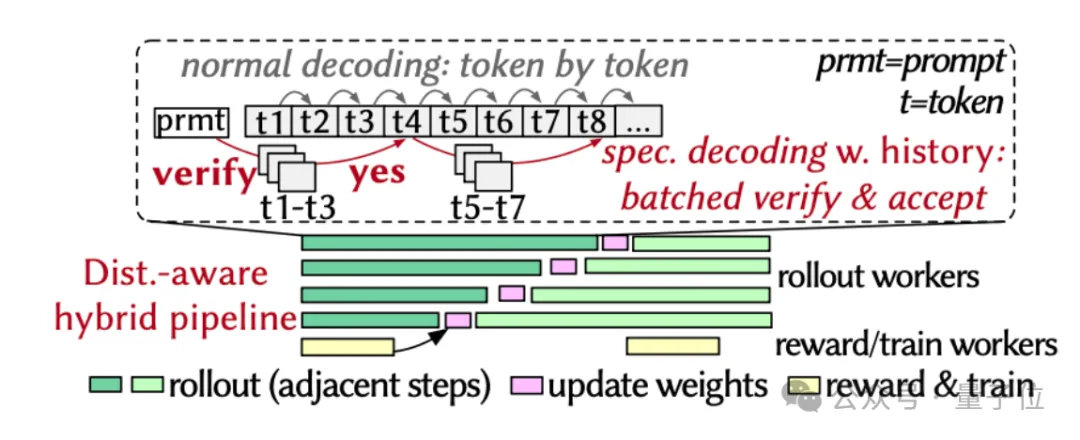
△RhymeRL的核心设计示意图
HistoSpec
传统的Rollout,是一个Token一个Token往外蹦的自回归过程,速度慢且GPU利用率较低。
而HistoSpec独创性地将投机解码(Speculative Decoding)技术引入RL,它不再需要一个额外的小模型来“猜”草稿,而是直接把上一轮的历史响应作为“最佳剧本”。
这就像开卷考试,你提前拿到了去年的标准答案作为参考。
起草(Draft):直接从历史响应中巧妙地总结出树状草稿。
验证(Verify):将整段草稿一次性扔给大模型,通过单次前向传播,并行验证所有Token的正确性,然后“接收”所有匹配的部分。
由于历史序列的超高相似性,草稿的接受率极高。
这使得计算过程从逐字生成变成了“批量验证”,计算密度飙升,打破了内存带宽的枷锁,让单个响应的生成速度实现了质的飞跃。
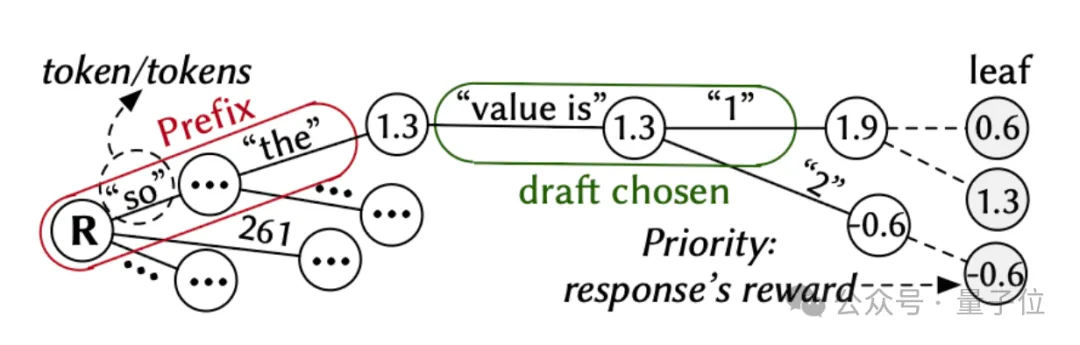
△HistoSpec采用的基于树的历史响应管理,实现了草稿的高速、准确生成
HistoPipe
仅仅让单个响应变快还不够。
在批处理中,不同任务的响应长度不一,短任务总要等待长任务,导致大量GPU资源被闲置,产生了巨大的“空泡”(Bubble)。
HistoPipe是一位具有前瞻性的调度大师,它的目标是:
榨干每一滴GPU算力,实现无空泡的完美流水线。
基于“长度分布相似性”的洞察,HistoPipe不再强求单一步内实现负载均衡,而是玩起了“跨步互补”——在奇数步,让所有GPU由短到长处理任务;在偶数步,则反过来,由长到短处理。
这样一来,上一步因为处理长任务而拖慢的GPU,在下一步会优先处理短任务,完美填补了时间差。
通过这种巧妙的削峰填谷,HistoPipe将整个集群的资源浪费降至最低。
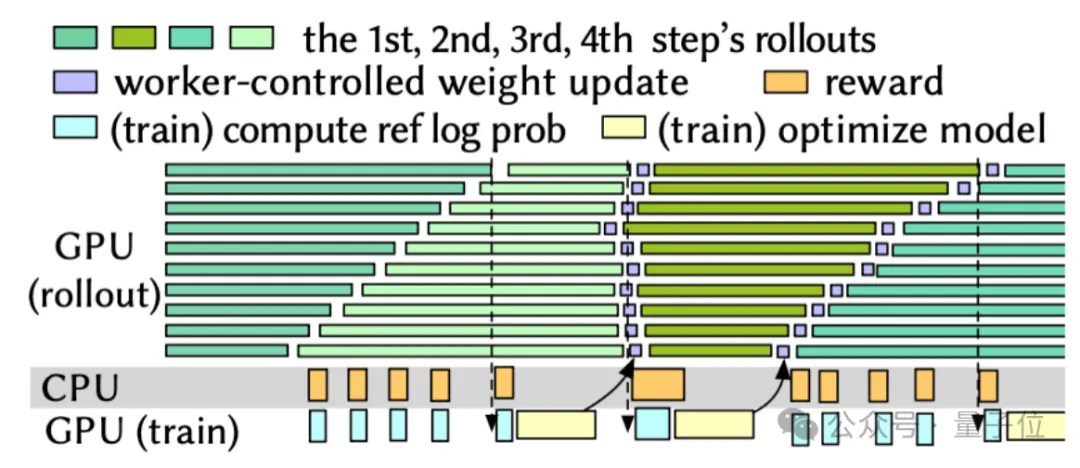
△HistoPipe的流水线设计,通过跨步互补调度实现了无空泡调度
2.6倍加速,精度无损
当模板HistoSpec遇上调度大师HistoPipe,产生反应是惊人的——实验结果表明,在数学、代码等任务上,RhymeRL相比于基础系统取得了大幅性能提升,端到端训练吞吐量提升高达2.61倍。
这意味着,研究者和企业可以用更少的资源、在更短的时间内,完成更强大的模型训练,极大地加速了AI技术迭代的步伐。
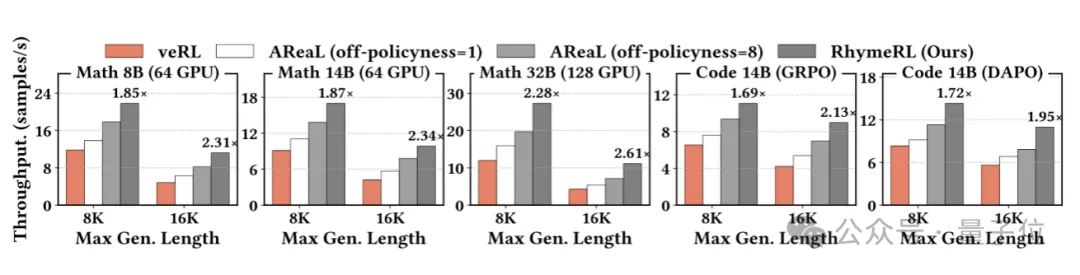
△RhymeRL在不同模型大小和不同响应长度下都取得了显著加速效果
RhymeRL的重要意义在于,它提出了一种新的强化学习范式——基于历史信息来端到端地加速强化学习效率。
强化学习不是简单的推理与训练的拼接,通过深入剖析其任务特性,RhymeRL能够充分发挥系统统筹调度能力与底层硬件的算力资源,同时无损地适配各种已有的训练算法。