DeepSeek上线后回看:一场架构“豪赌”
2025-08-21 19:25:29 · chineseheadlinenews.com · 来源: 腾讯科技
8月19日DeepSeek上线全新的V3.1版本。新模型融合思考与非思考模式,大幅提升编程和智能体能力,成本显著降低。但这种激进的模型融合策略也引发争议,部分用户反馈幻觉重现,商业API的无预警更替更引发稳定性质疑。
8月19日晚间,DeepSeek官方悄然上线了全新的V3.1版本。
官方公告强调了上下文长度拓展至128k,但随着社区的深入挖掘和实测,这次“小包新”之下其实有着更多模型架构的变革和模型重点能力的微调,在编程能力上的提升也可圈可点,成本优势重回显著。
然而,模型融合的技术路线也引发激烈争论,部分用户反馈旧版模型的“顽疾”复现,对这次更新的评价呈现出两极分化的态势。
发布两天后,DeepSeek官方在公众号上发布了相关消息。
此时,正适合我们回看V3.1,更细致地拆解这次“小包新”。
架构之变:V3.1吞掉R1,减轻部署复杂度
尽管DeepSeek官方在更新通知中将“上下文长度拓展至128k”作为核心亮点,但此前的V3版本早已支持128K上下文,只是官方API接口此前仅开放至64K。
因此,这次更新的真正核心并非上下文长度,而是模型底层的架构演进。
根据官方最新发布的公众号内容,确认了V3.1为混合推理架构,即使用一个模型同时支持思考模式与非思考模式。
目前在DeepSeek的官方网页和APP上,即使用户开启“深度思考”模式,模型的标识也已从过去的“R1”变为了统一的“V3”。
用户通过API调用推理模型时,模型也明确“告知”自己是V3模型。
不过这里和GPT-5自动路由不同,是否打开思考模式,依然是用户控制,而非通过自动的模型路由判断。
在过往的经验中,这种混合模型可能会导致非推理任务,如创意写作和情商表达等能力的下降。不过,根据社区内用户分析,这种混合可以简化部署和运维,提高算力利用效率。
能力优化:编程再提升,成本再下降
除了架构改变外,V3.1被首先注意到的是编程能力的大幅提升。
根据社区广泛引用的Aider编程基准测试数据显示,DeepSeek V3.1取得了71.6%的高分,在开源模型中成功“霸榜”。
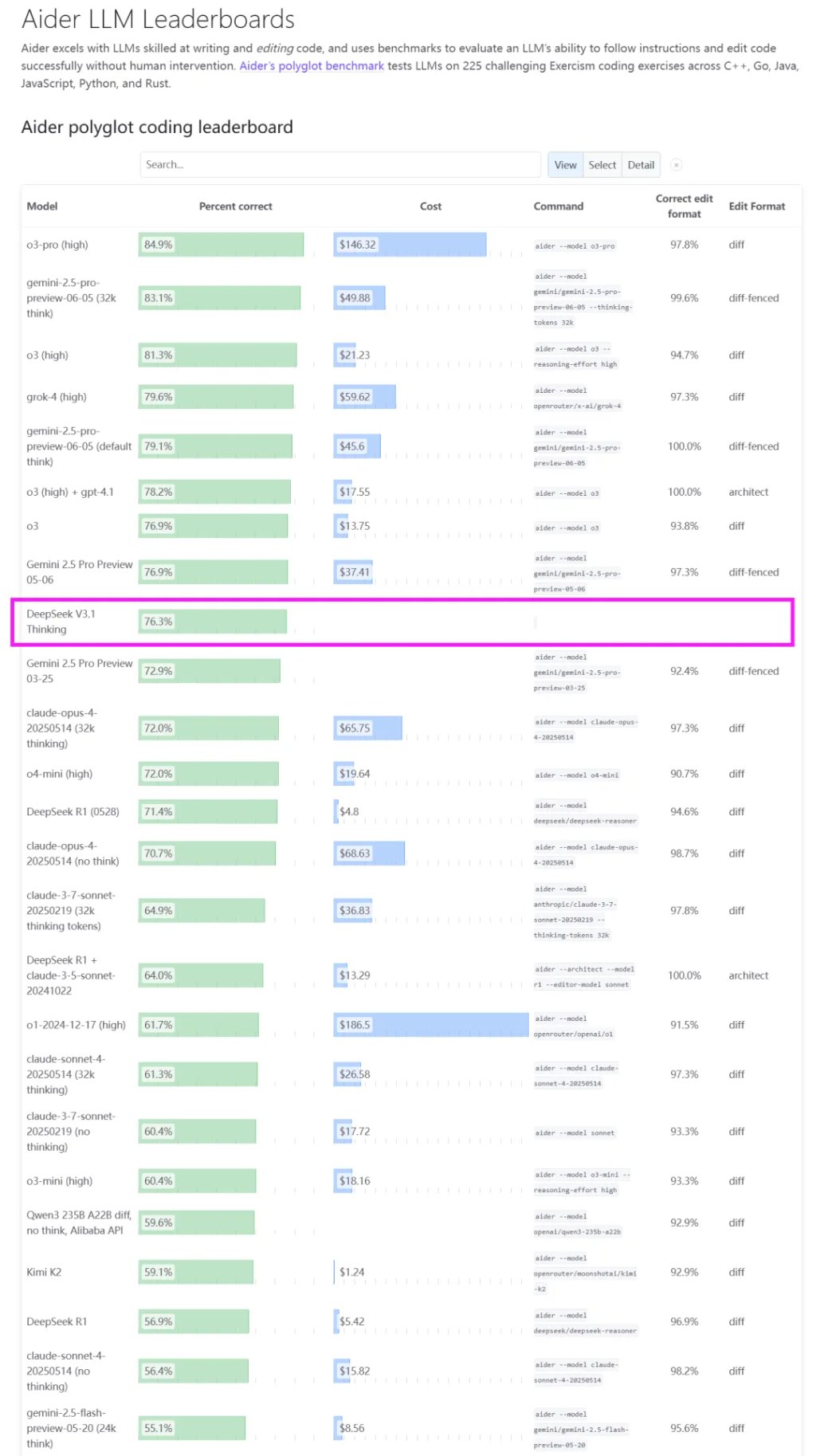
这一成绩不仅超越了此前的DeepSeek R1,甚至击败了强大的闭源模型Claude 4 Opus。
在其他权威基准测试中,V3.1同样表现出色。
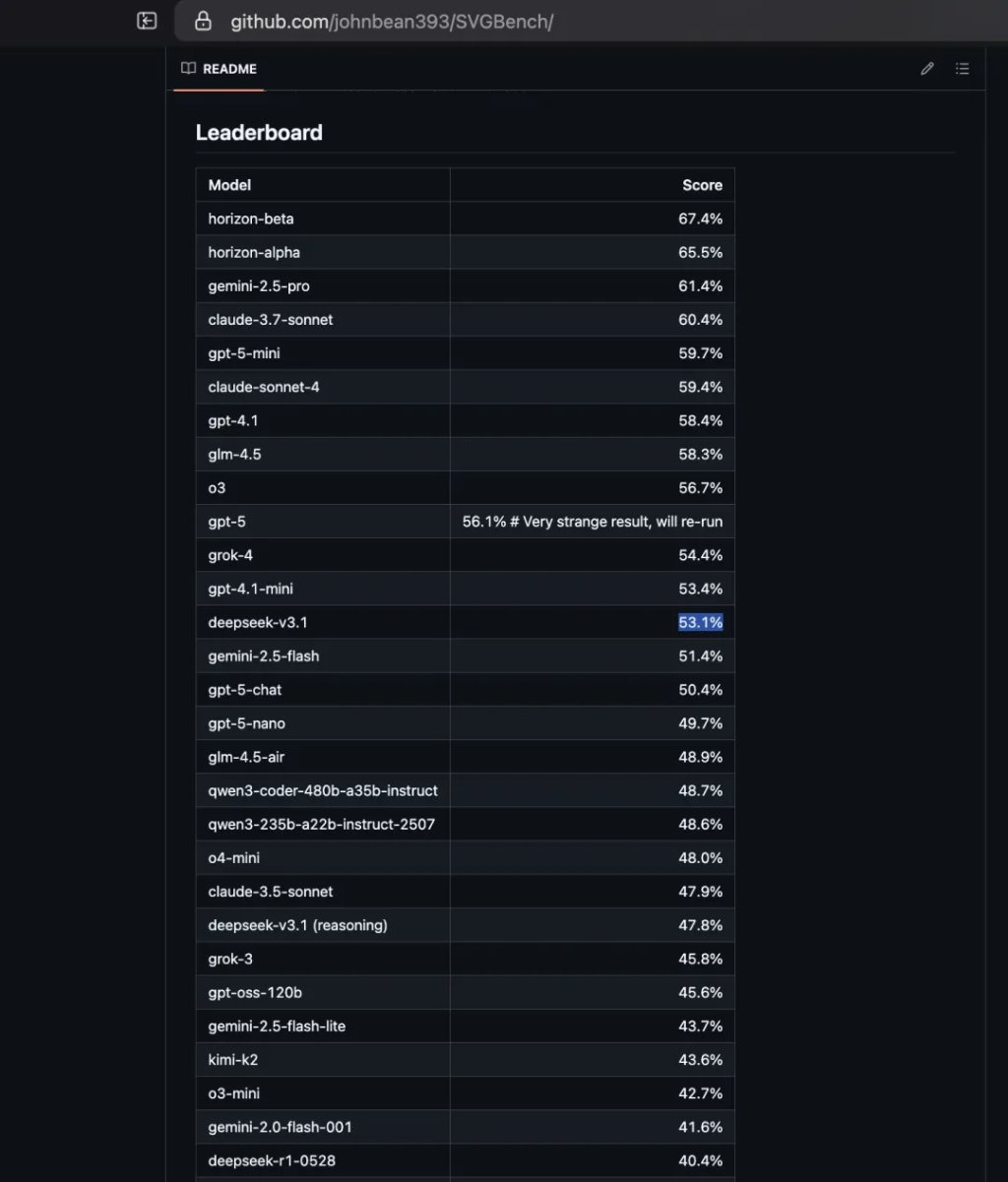
SVGBench:实力仅次于GPT-4.1-mini,远超前代DeepSeek R1。
MMLU:在多任务语言理解方面,V3.1的表现毫不逊色于GPT-5,得分达到88.5%。
不过,在研究生级别问答(GPQA)和软件工程(SWE-Bench verified)等领域,V3.1与GPT-5相比仍存在一定差距。
在V3.1备受瞩目的编程能力实战中,其表现可圈可点但并非完美。
在新智元生成一个“黑客帝国风格”的three.js动态世界的任务里,V3.1成功满足了基本的功能要求,但对于画面风格和颜色变换等细节的实现不够精准,最终效果被测评者评为“80分”。

黑客帝国风格动态世界
在DeepSeek的传统强项——成本效益上,V3.1的进化也颇为可观。
在社区用户的测试下,完成同样一次完整的编程任务,V3.1的成本仅需约1.01美元,远低于Claude 4 Opus(便宜68倍)。从推特网友整理的各主流模型性价比来看,DeepSeek V3的性价比名列前茅。
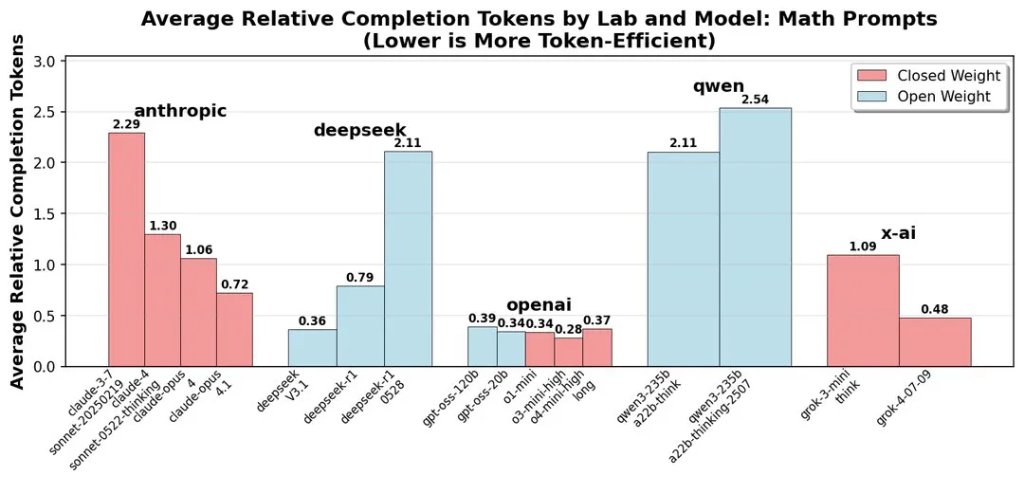
这里的数值越低越好
根据DeepSeek官方宣布的最新V3.1价格表,其输入价格为,0.5元/百万 tokens (缓存命中) ,4元 /百万 tokens (缓存未命中) 。输出价格为12元 /百万 tokens ,该价格于2025 年 9月6日 00:00 起生效。

根据官方解释,成本下降主要来自于思维链压缩训练。通过减少无意义的思维链输出,V3.1-Think在输出token数减少20%-50%的情况下,各项任务的平均表现与R1-0528持平。
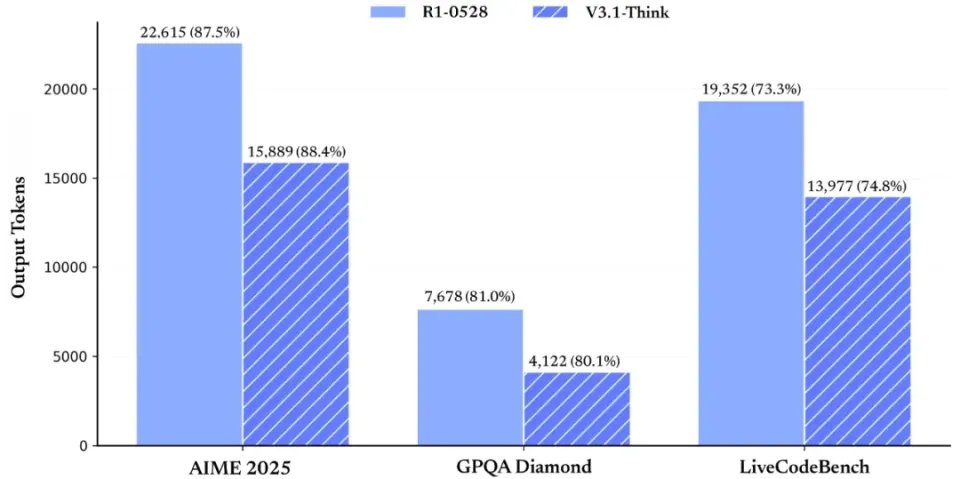
这一技术改进不光带来成本的下降,也让生成速度显著提升。社区用户的第一印象都是V3.1比R1速度快了很多。
最大的升级:智能体能力跃迁
在前几天讨论中,DeepSeek V3.1的Agent能力的显著增强并没有得到太大注意。
因为这一能力是底层的搜索和工具调用能力的提升,从外部看我们只能看到具体能力,如编程等能力的提升。
在8月21日正式的发布中,DeepSeek官方特意强调了这一点。通过专门的Post-Training(后训练)优化,新模型在工具使用与智能体任务中有巨大提升。
此次升级在复杂的软件工程和终端控制任务上表现得尤为突出,几乎实现了跨越式的进步。
在衡量真实世界代码修复能力的SWE-bench Verified基准上,V3.1取得了66.0分,远超前代V3-0324的45.4分和R1-0528的44.6分。而在更具挑战性的Terminal-Bench(终端操作)测试中,V3.1的得分(31.3)更是达到了前代推理模型R1-0528(5.7)的五倍以上,展现了强大的自动化操作潜力。
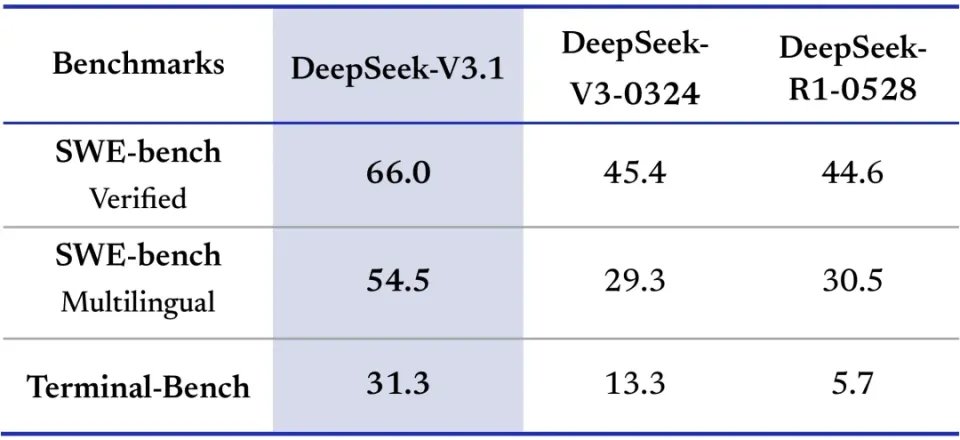
除了在专业领域的突破,V3.1在通用的网页浏览和工具调用能力上也获得了全面增强。在衡量网页自主导航与信息获取能力的Browsecomp测试中,其得分从R1-0528的8.9分飙升至30.0分,提升超过三倍。
同时,在模拟多种工具使用的Seal0基准上,V3.1的得分也从29.7大幅提升至42.6。
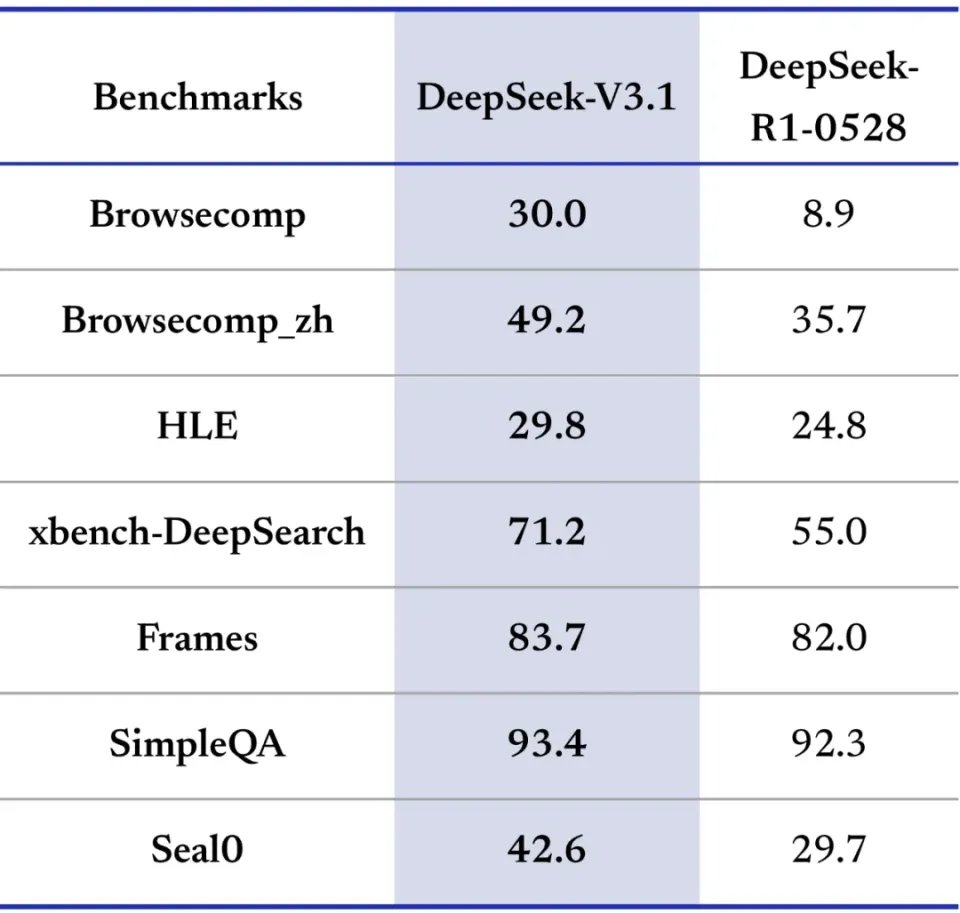
即使和目前最先进的模型对比,DeepSeek V3.1的Agent能力也不怯场。
比如SWE-bench Verified这一测试中,Anthropic的最新模型Claude Opus 4.1 在此基准上更是达到了74.5%的先进水平。而DeepSeek V3.1最新得分为66.0%,高于排名第三的GLM 4.5。
而在Terminal-Bench中,Claude 4 Opus以43.2%的得分在该项目上表现最佳。GLM-4.5(37.5%)和Claude 4 Sonnet(35.5%)紧随其后。DeepSeek V3.1的31.3分超过了GPT-4.1(30.3%)和Gemini 2.5 Pro(25.3%)。
在所有基础模型都重视的Agent能力的背景下,DeepSeek的这次升级追上了时代,也抹掉了短板。
V3.1的隐忧:合并模型,是一场豪赌
尽管V3.1在编程和智能体领域取得了突破,但其核心的“模型融合”策略却在社区引发了巨大争议。
阿里的Qwen模型在尝试过融合推理后,最终在新版本中还是分开发布了Instruct和Thinking两种分离的模型。
而GPT-5的“一体化系统”也则是使用一个智能路由(Router)来调度不同的核心组件,而非直接将模型激进地融合。
这是因为在上一代模型中,很多基础模型的“出厂设置”是一个思考模型,其非思考版本仅仅是关闭了系统给模型设置的思考预算。
但思考模型的训练,尤其是在强化学习(RL)微调阶段,存在一个固有的、难以回避的权衡问题。
为了让模型擅长逻辑、数学和代码等需要严谨推理的任务,强化学习的奖励(Reward)会高度偏向于那些能够展现清晰、正确、分步式解题过程的输出。
这种对“过程正确性”的极致优化,会深刻地改变模型的底层行为模式。
模型在处理那些不需要严密逻辑、更需要创造力、共情能力或常识性理解的通用任务时,可能会显得“水土不服”。
不少用户反馈,V3.1版本重新出现了幻觉严重(如在年报总结问题上关键信息全部出错)和中英夹杂的问题,后者在旧版中几乎不存在。
此外,模型在面对复杂问题时表现出“能省则省”的倾向,在多次尝试无果后会主动“放弃”,而不是继续深度推理,这或许是官方为优化Token使用而做出的权衡。
这些弊端都可能是混合模型带来的。
更令商业API用户不满的是DeepSeek激进的更新策略。DeepSeek倾向于用新模型直接覆盖旧模型,且不提供任何旧版本的API。
这种做法意味着,线上生产业务的API可能在毫无预警的情况下被更改,导致下游工作流崩溃,严重影响了商业应用的稳定性。目前在Hugging Face社区,已有API用户对此表达了强烈不满,要求退款并希望能继续使用稳定的0324版本。
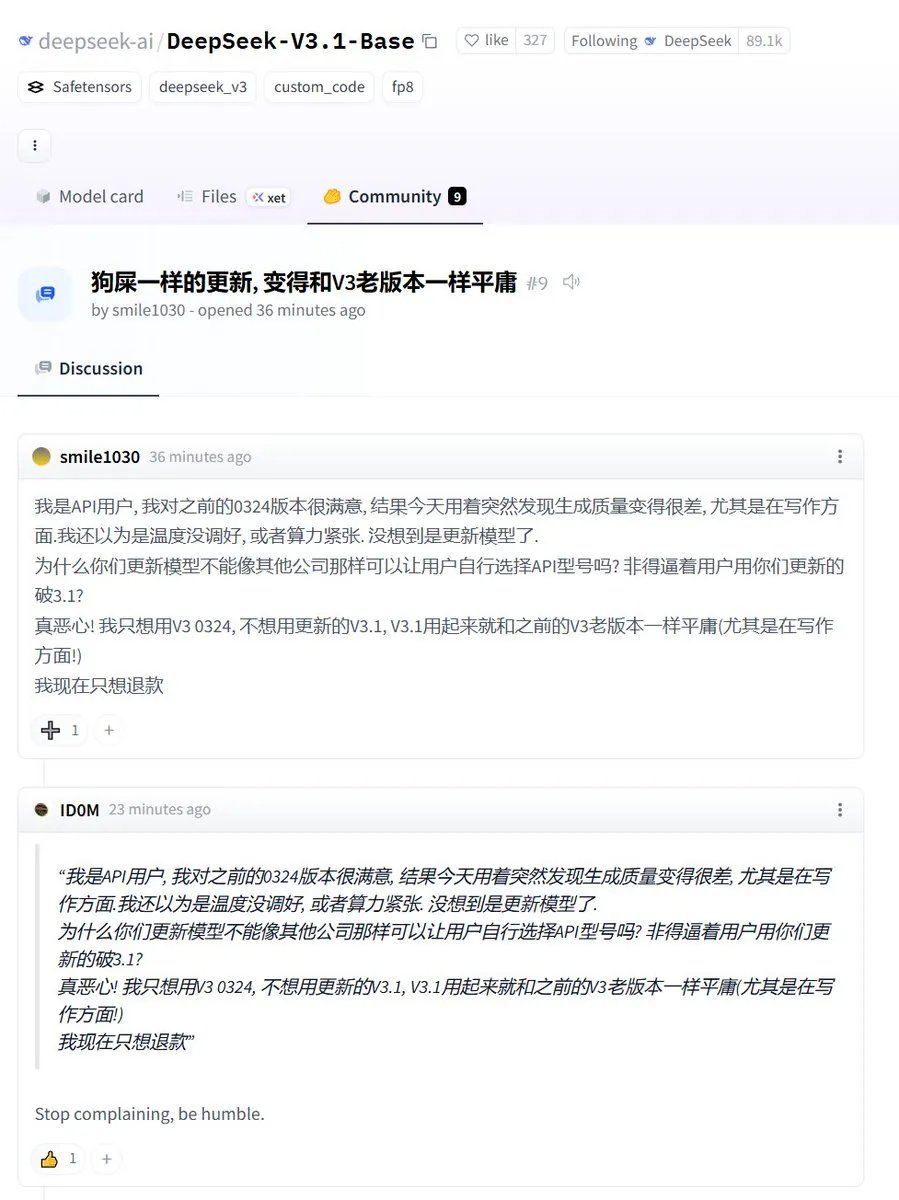
GPT-5 激进更新的前车之鉴,看来 DeepSeek 并未引以为戒。