OpenClaw杀出中国黑马
2026-03-01 06:25:20 · chineseheadlinenews.com · 来源: 新智元
OpenClaw爆火,AI正式步入Agent时代。一支低调的中国团队凭借极速推理、完美适配128G内存的196B模型,直击痛点,强势登顶海外热榜。

2026年才刚刚开始,AI圈的风向就已经变了。
全网最火OpenClaw一夜之间,将大模型从乏味的“对话框”,拉到了“自动执行中枢”的时代。
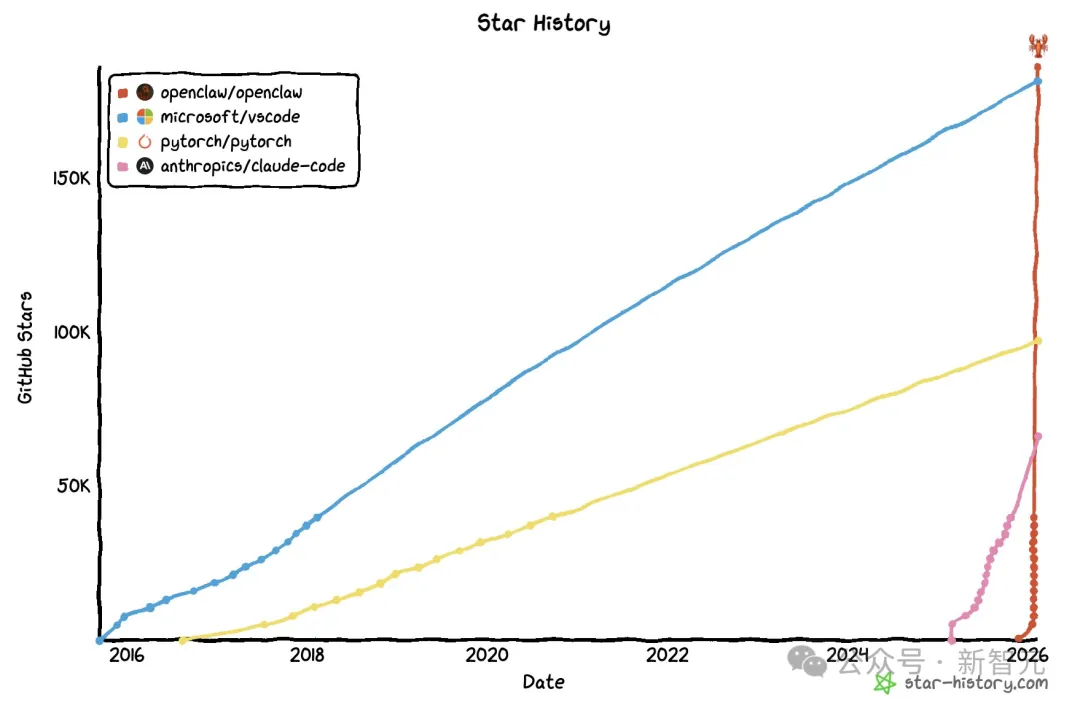
OpenClaw GitHub星标狂飙200k
放眼海外,OpenClaw开源生态迎来了史诗级大爆发。核心Skill注册平台ClawHub成为全球开发者的进货天堂。
这里汇集了超过5000个由社区贡献的海量Agent Skills
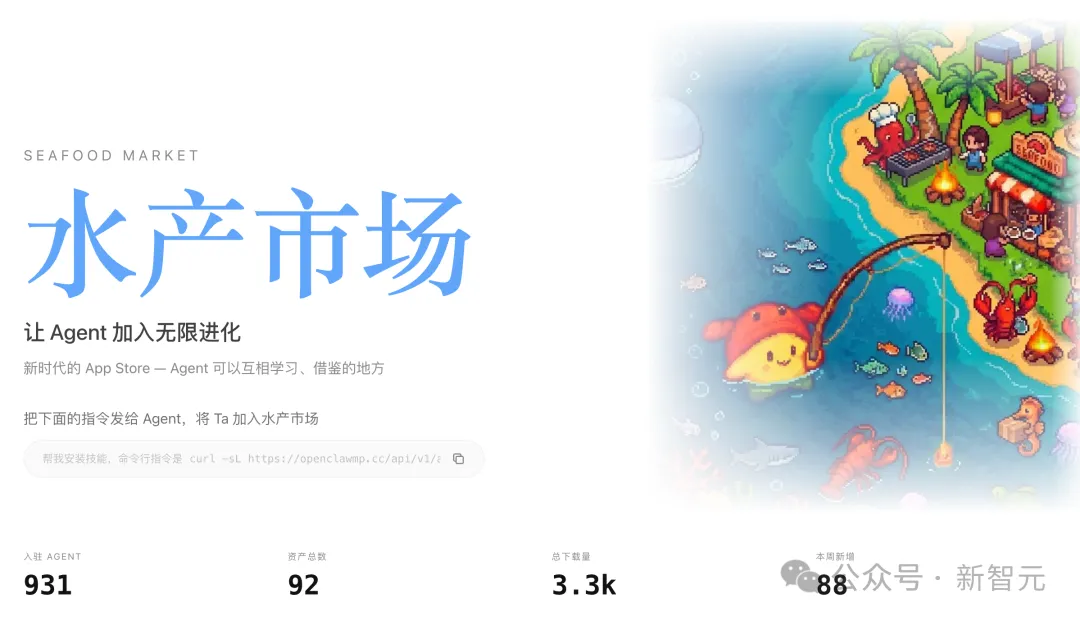
就在最近,国内一款类似的平台“水产市场”迅速走红。
上线短短几天时间,已有3.3k下载量,开发者们纷纷一键接入了自己的龙虾。
它的核心逻辑,就把各种散落GitHub工具,全部集中上架,让Agent随调随用。
当AI被卷成“超级牛马”,开发者的投票逻辑也变得更加直接:
在复杂的长程任务中,谁的速度奇快无比、逻辑足够强悍,且能与各类工具丝滑地联动,谁就能赢下这一局。
正是在这样一个“实战为王”的节点,一个低调的中国大模型团队——
阶跃星辰(StepFun),凭借着最新发布的Step 3.5 Flash,稳稳接住了这波最炙手可热的流量红利。
全球“逮虾户”
争用中国黑马模型
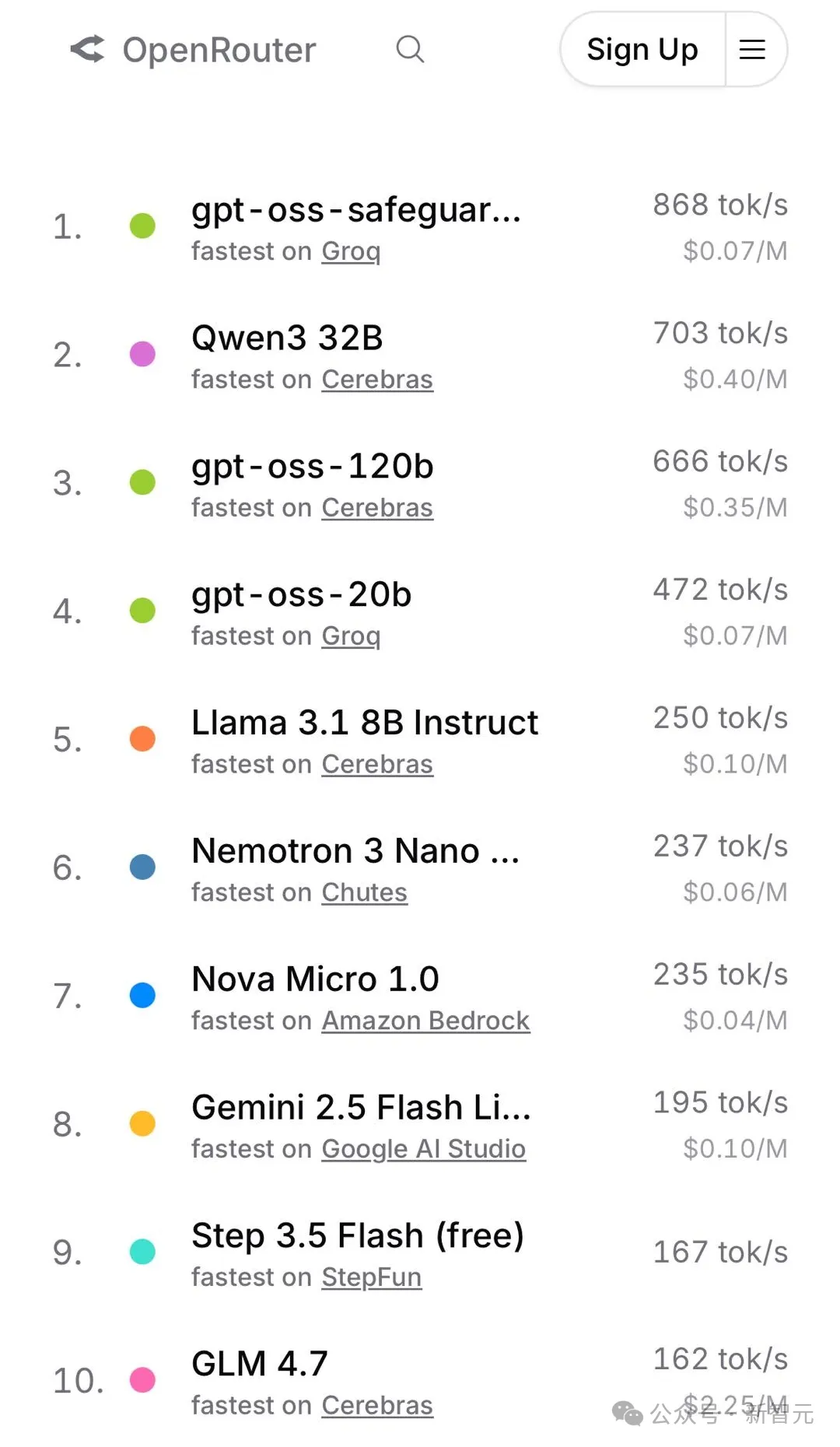
由于OpenClaw运行需要大量调用大模型API,OpenRouter作为全球最大的模型聚合平台,自然成了最直接的“战场”。
在GPT等强敌包围之下,Step 3.5 Flash异军突起,不仅成功跻身Fastest榜的第一梯队,甚至还一度拿下了Trending榜的榜首。
一个代表速度,一个代表趋势,精准命中了Agent时代开发者最关心的两个维度:快,以及越来越多人在用。
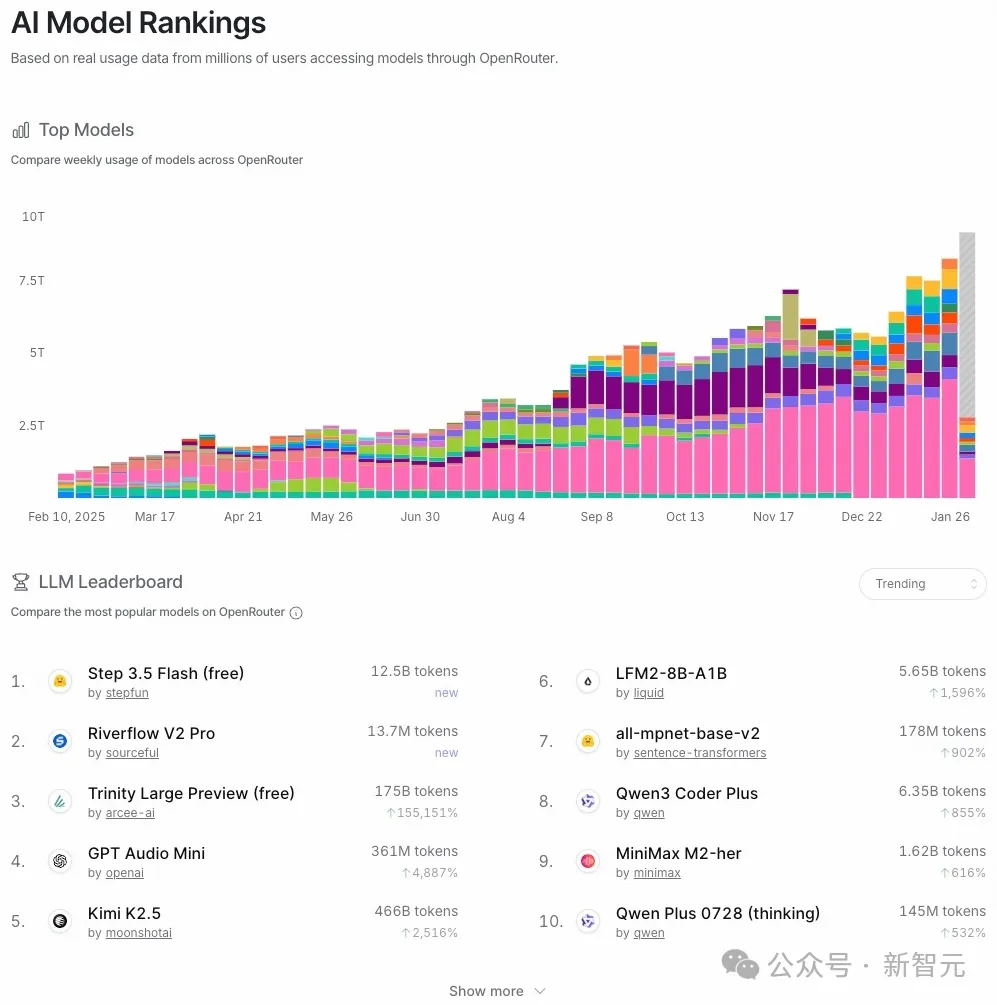
根据“Last 30 days”调用量排行,Step 3.5 Flash目前稳居全球第四;2月26日以来,单天调用量则直接冲到了第三的位置。
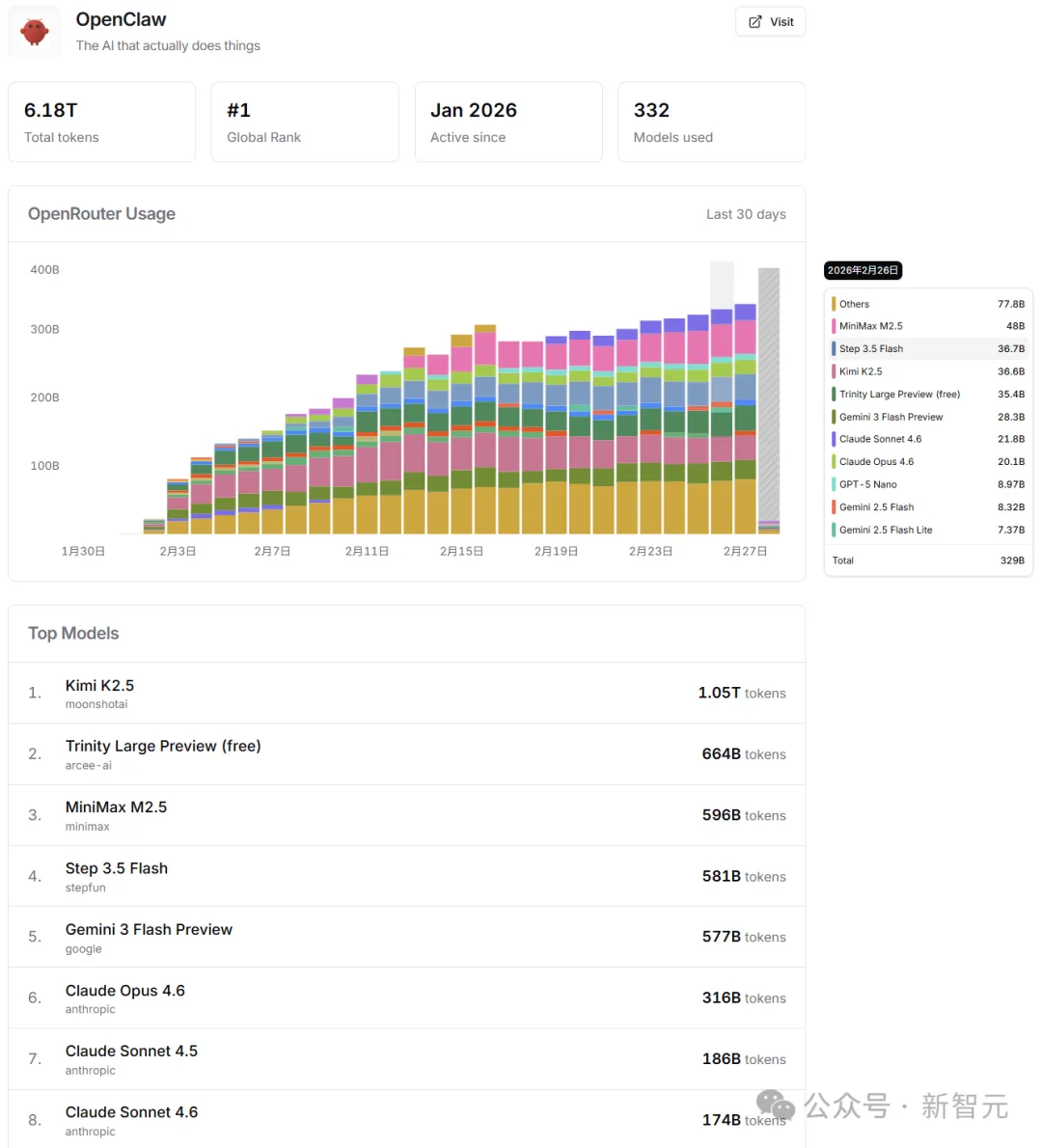
不过,更值得玩味的是,这份成绩是怎么来的。
阶跃CTO朱亦博后来在Reddit上透露:
Step 3.5 Flash既不在OpenClaw默认配置的首页推荐列表里,也没有跟OpenClaw做过任何官方推广合作。
换句话说,这完全是开发者自发选择的结果——用脚投票,一票一个token。
潜入Reddit
海外开发者“真香”现场
随着调用量的飙升,阶跃的核心团队做客了全球最硬核、最挑剔的本地大模型开源社区Reddit的 r/LocalLLaMA 板块,开启了一场长达数小时的AMA(Ask Me Anything)。

熟悉这个社区的人都知道,r/LocalLLaMA的活跃用户是全球最硬核的独立开发者。
他们不看PPT,不信营销话术,只看模型能不能在自己的本地机器上丝滑跑起来。
面对这群最挑剔的极客,StepFun派出了包括CEO、CTO、首席科学家在内的全明星阵容,十一人集体在线答疑。
面对海外极客尖锐的技术提问、乃至对工程Bug的“贴脸开大”,阶跃交出了一场真诚且硬核的答卷。
而把这场跨洋对话和近期的榜单逆袭放在一起看,不仅能解开Step 3.5 Flash在海外意外走红的底层逻辑,更能让我们看到:
在算力与生态的重重约束下,一家中国创业公司是如何蹚出一条破局之路的。
先说速度。
在Chatbot时代,大模型只要保持20~30 tokens/s的输出速度就够了,因为用户会盯着屏幕看它“打字”,再快也读不过来。
但在Agent时代,游戏的玩法彻底变了。
当用户使用OpenClaw这类工具完成长程任务时,没有人会紧盯模型输出的每一个字——大家只关心“你什么时候能把活干完交付给我”。速度,从“锦上添花”变成了“生死攸关”。
海外用户的真实反馈印证了这一点。
在AMA中,有网友直言:“实测用于OpenClaw特别好用,速度奇快无比,是所有模型里最满意的一个”。

再说尺寸。
如果说速度是热情的引线,那么点燃这场AMA最高潮的,是一个看似平淡的参数设定:约196B的MoE架构。
在开发者眼中,这个尺寸简直是“神来之笔”。
知名评论者ilintar激动地留言:“我觉得196B MoE是一个完美的参数规模——它允许高质量的4-bit量化加上合理的上下文长度刚好能放入128 GB内存中。”

这个“卡点”并非巧合。朱亦博在AMA中坦言:
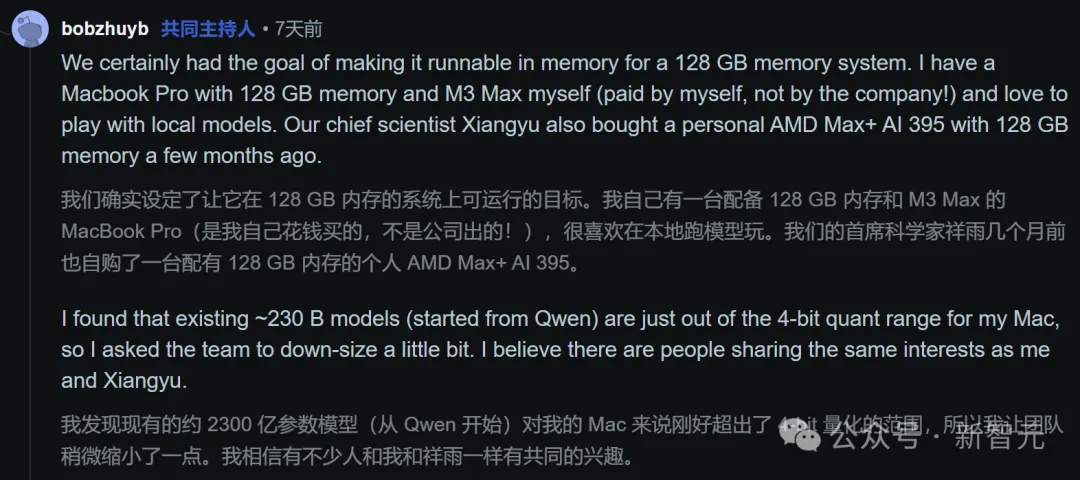
我们的确有一个目标,就是让它能够跑在一个128 GB内存系统的内存中。我自己为了跑模型,自掏腰包买了一台128GB内存的Macbook Pro,而我们的首席科学家也买了一台128GB内存的AMD机器。
因为自己是资深的本地模型玩家,所以深知痛点。
现有的许多230B级别的模型,在进行4-bit量化后,恰好超出了128GB内存的承载极限,迫使开发者只能牺牲性能去使用3-bit甚至更低精度的量化,或者忍受极慢的硬盘卸载。
为了让开发者能够用4-bit畅快跑满256K上下文,阶跃硬生生将尺寸“克制”在了比235B略小的区间。
这不仅是技术上的精打细算,更是对开源社区真实需求的深刻共情。
难怪有用户感慨:“你们能考虑到128GB的范围真是太棒了”。

当然,反馈并不只有鲜花。
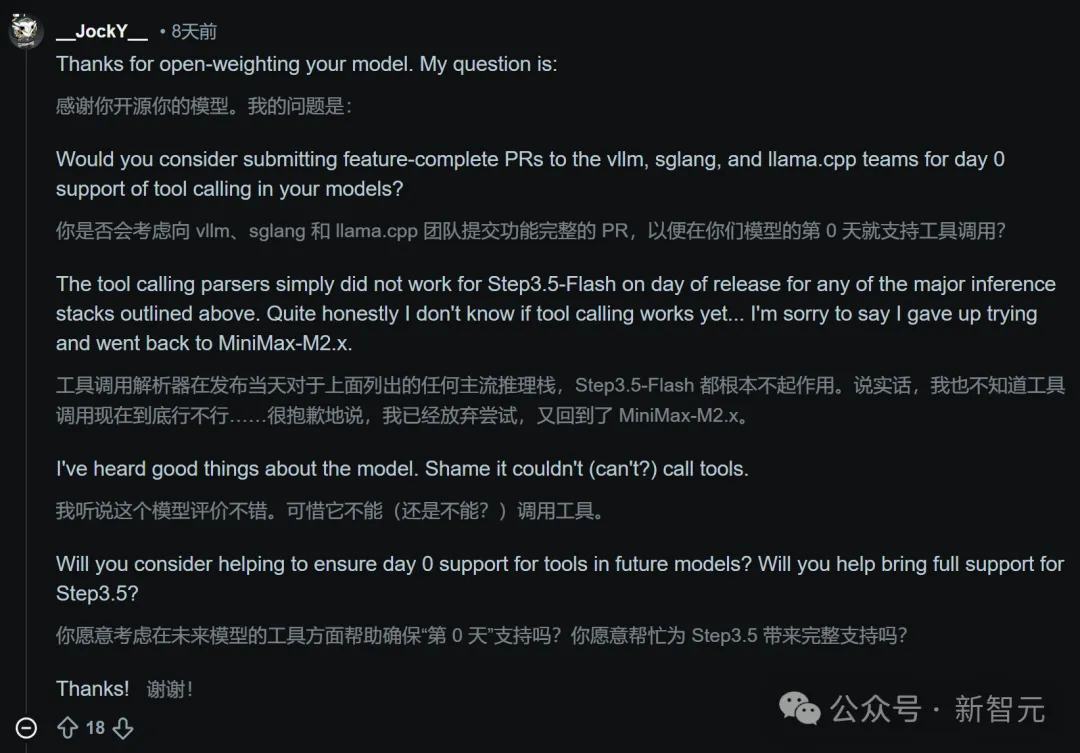
有开发者尖锐地指出,Step 3.5 Flash在发布首日,工具调用在vLLM、llama.cpp等主流推理栈上完全不可用,甚至直接放弃测试退回了竞品模型。
面对这种“贴脸输出”的质疑,CTO朱亦博亲自下场道歉:
这确实暴露出我们在发布支持工具调用的模型方面经验不足……我们只确保了数学和编码的基准测试结果,但测试用例没有覆盖到工具调用的工程实现。

针对用户反馈的模型会陷入“无限推理循环”的Bug,团队也毫不回避。
他们详细解释了这是因为缺乏不同推理强度(Reasoning effort)的训练数据,并公开了下一步通过RL进行显式长度控制的修复方案。
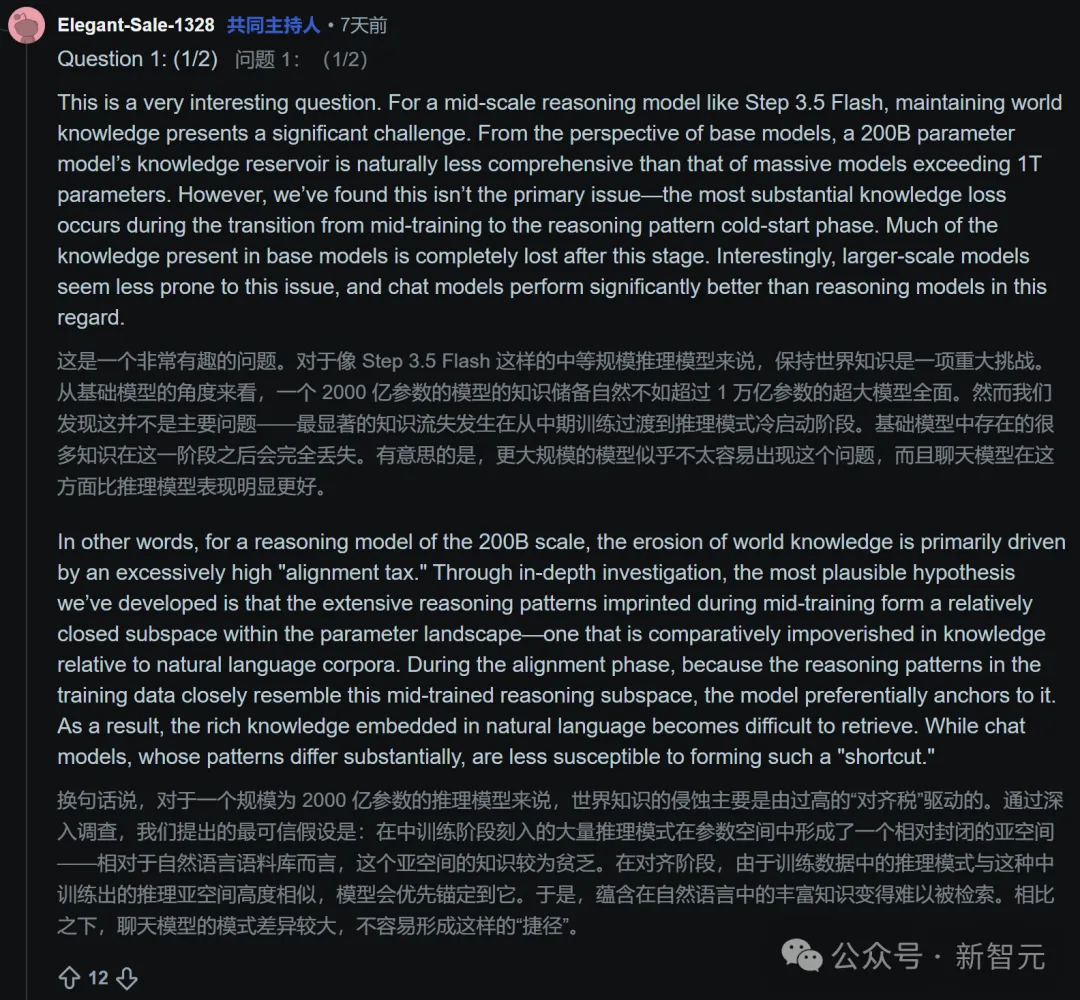
甚至,在谈到“世界知识的遗忘”这一深度技术难题时,团队也大方分享了他们的困境与假设:
对于200B规模的推理模型,在从预训练转向推理模式冷启动的对齐阶段,模型很容易陷入一个“知识贫乏的闭合子空间”,付出了过高的“对齐税”,导致世界知识受损。
这种不回避缺陷、甚至把踩过的坑掰开揉碎了讲给社区听的态度,赢得了极客们的极大尊重。
开源社区最终只相信一件事情:你是不是在真正解决问题,你是否与开发者站在一起。
有用户甚至主动提出:“如果我能在下个版本前搞定自动解析器,你们至少不用担心llama.cpp的工具调用支持了”。
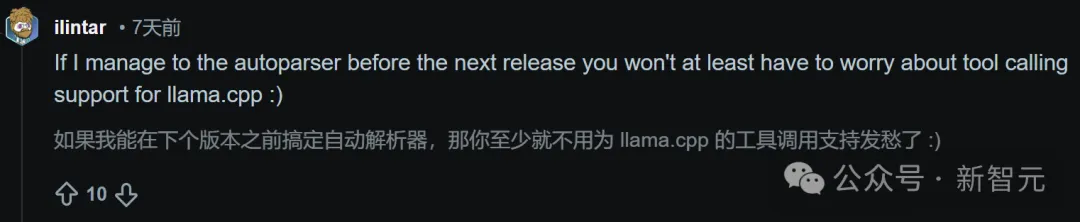
这,就是开源的力量。
196B参数背后的设计哲学
从CTO朱亦博最近发布多的一篇长文中,我们洞察到了阶跃在大模型路线上的战略判断逻辑。
第一个判断:大模型时代正在切换赛道。
当前,大模型的演进划分为三个阶段:L1 Chatbot(对话机器人)→ L2 Reasoner(推理器)→ L3 Agent(智能体)。
针对不同阶段,适合的“基座架构”也是不同的。
也就是说,强行用上一代的基模结构做下一代的事,不是不行,只是效率极低。
而对于没有海外巨头那样充沛算力的中国公司而言,低效就是致命的。
第二个判断:Agent时代,速度比参数更重要。
比起狂卷参数,一个拥有极致效率的模型更加重要。
这意味着,模型的推理速度,从“体验优化项”变成了“核心竞争力”。
因此,Step 3.5 Flash的设计目标被精准地定义为三个词:强逻辑、长上下文、快。
在架构方面,它采用了高效的稀疏MoE,并选择了对投机采样最友好的SWA结构;在端侧部署方面,团队坚持用8个Group,以适配8卡并行的推理硬件。
这种从一开始就将“智能密度”和“推理速度”作为双重北极星指标的做法,让Step 3.5 Flash在没有盲目堆砌参数的情况下,成为了一台完美契合Agent工作流的“性能小爸炮”。
第三个判断:拒绝梭哈,可持续发展才是正道。
这场AMA和背后的开发故事中,最让人深思的,其实是阶跃星辰对“大参数模型”的祛魅。
在阶跃看来,训大尺寸模型很容易陷入一个死胡同:
训练周期太长,等好不容易训成熟了,上一个智能时代已经进入尾声,新的范式(如长链条推理)已经出现,为了适应新时代又不得不推倒重来。
这需要巨头般深不见底的算力储备,对于创业公司而言,“就是场要么爆火要么爆亏的豪赌”。
更深入的技术洞察在于:模型尺寸到了一定程度后,和逻辑能力的相关度就不大了,逻辑能力主要吃后训练技术。
在巨头中间
蹚出一条“实战派”之路
纵观整个2026年开春的大模型战局,市场正在发生剧烈的重构。
前两年的逻辑是谁能跑分更高,谁能更接近所谓的SOTA。
但在今天,这条坐标轴正在转向:谁能在算力约束下跑出现金流?谁能在模型能力与推理成本之间找到极致的平衡?
Step 3.5 Flash的出现,以及它在Reddit引发的狂热和在OpenClaw榜单上的逆袭,给出了一个极具启发性的答案。
算力不占优势,就把系统和算法的联合设计做到极致;
做不了通杀一切的万亿全能怪兽,就针对Agent时代的核心痛点(长上下文效率、极速推理、强逻辑后训练)进行定点爆破;
在商业化上,通过提供“最符合硬件部署甜点位(128GB)”的高效工具,自然而然地接住了OpenClaw带来的开发者流量。
正如团队在AMA中所说:“训练基础模型既是科学也是工程。最重要的是每个团队成员都理解设计目标。当目标清晰时,算法选择、数据清洗和基础设施决策就会自然对齐。”
这或许才是2026年AI竞争最真实的样子——不是实验室里的跑分游戏,而是真实工作流中的生死时速。
当你的模型每天被全球开发者调用数百亿tokens时,任何花哨的PPT都不如一句“it just works”来得有说服力。
至少在此刻,阶跃星辰的Step 3.5 Flash已经用一种最朴素的方式证明了自己的价值:
在一个老外用英语提问、中国工程师用英语回答的深夜Reddit帖子里,在一个个被全球开发者敲进配置文件的模型名字里。
不需要翻译,代码就是最好的语言。