UCB颠覆认知:LLM靠“自信爆表”学会推理
2025-05-31 03:25:49 · chineseheadlinenews.com · 来源: 新智元
就在刚刚,UC伯克利CS博士后Xuandong Zhao,分享出来自己“今年参与的最鼓舞人心的工作”。
他和同事们发现,在没有外部奖励的情况下,LLM竟然只靠“自信爆棚”,就学会了复杂推理?

LLM靠自信心,竟能学会复杂推理
LLM不靠外部奖励,就能自己学会复杂推理,这个结论实在很出乎意料。
团队之所以能做出这个结果,是源于两个关键的观察。
在考试中,人们往往对自己有信心的问题,回答得更准确。这种“信心≈正确性”的模型,对LLM是否也适用呢?
在测试时推理中,长CoT或并行扩展技术(如多数投票)很常见。但在面对代码生成这样的开放式任务时,我们该如何在多样化的输出中做出选择呢?
为此,他们探讨了如何有效扩展“n选一最优”的选择策略。
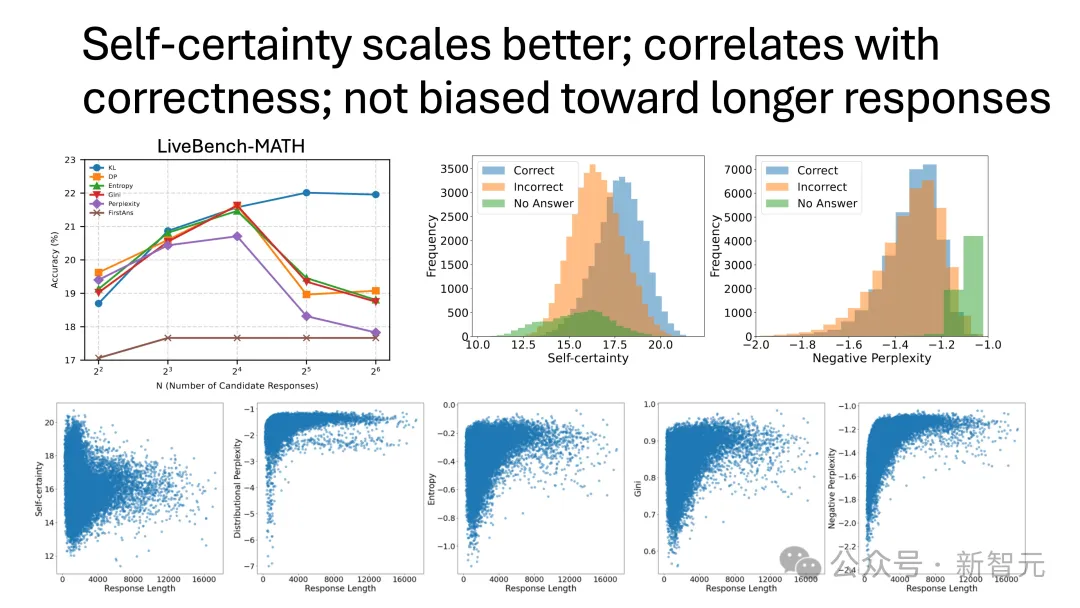
现有的一些启发式方法,比如熵和困惑度都存在不少问题:比如对输出长度敏感、有偏差,而且在样本数量增加时效果变差。
然后,他们就得出了一个关键的洞察:衡量每个token的分布距离均匀分布有多远。KL散度KL(U‖P) ,可以量化模型在预测每个token时的“自信程度”。可以将这一度量称为“自我确定性”。
而它,正是熵的反面——不是覆盖多种可能,而是倾向于聚焦在最可能的结果上。
他们发现,自我确定性是一个非常有效的信号——
当答案已知时,它通过加权投票的方式表现优于多数投票。
当答案未知时,它仍然可以随着n的增加而稳健地扩展。
由此,在今年二月份,他们发表了第一篇论文。

不过,他们的探究并未止步于此。一个后续问题自然而然出现了:如果“自我确定性”是一个良好的评估信号,它是否也可以用作训练模型的奖励?
也就是说,如果人类可以通过探索和反思建立起自己的信心,那LLM也能做到同样的事吗?
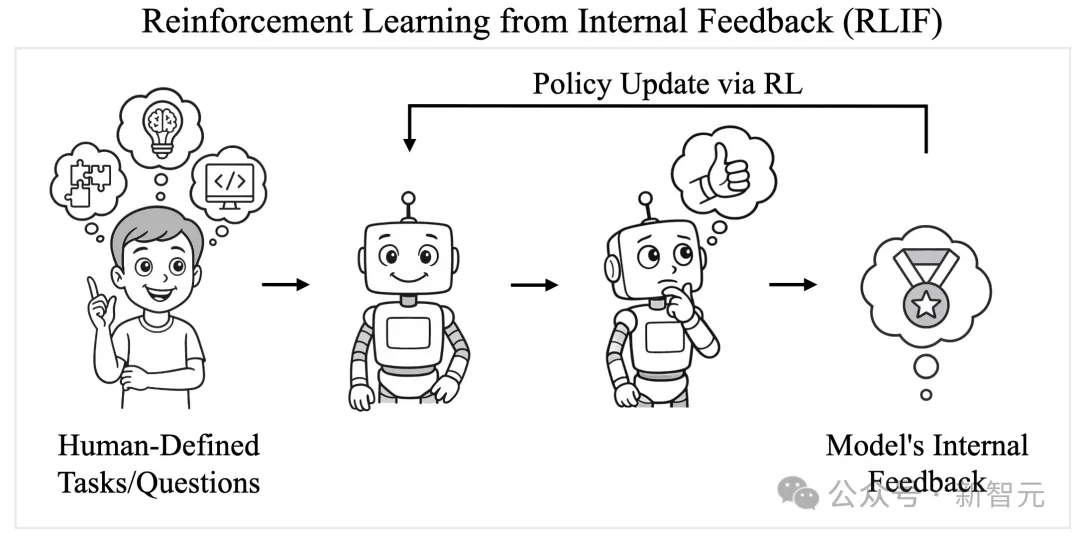
这就启发了研究者们的新范式——RLIF。
他们采用的新方法,使用自我确定性作为强化学习的奖励信号,而不需要外部监督。
结果,这种方法果然奏效了!
它在数学任务中的表现,可与使用规则奖励的GRPO相媲美,在代码生成任务中甚至有更好的泛化能力。
它能学习结构化推理——提前规划、分解问题,甚至能够遵循指令,而这一切都来自于内部反馈(内在奖励)。
Xuandong Zhao表示,这个项目给了自己很大信心,尤其看到一些同期研究(TTRL、基于熵的强化学习、语义熵+答案等)时。
很明显,RLIF是一个很有前景的方向。很显然,目前的探索才刚刚触及了表面。
展望未来,RLIF还提出了许多开放性问题。
它为什么会有效?哪些任务最受益?
它能否扩展到更大的模型?它与幻觉或记忆有何关系?
RLIF能否在现实世界的部署中补充RLHF或RLVR?
它在智能体任务中的表现如何?
RLIF登场,打破根本局限
强化学习(RL)已经成为提升大语言模型能力的一个重要工具。
早期主要是基于人类反馈的强化学习(RLHF)上。
最近,基于可验证奖励的强化学习(RLVR)取得了进展,它用可自动验证的信号(如数学题解中精确匹配的答案)取代了传统的学习型奖励模型,并在DeepSeek-R1等模型上展现出了更强的推理能力。
尽管取得了不少成功,RLHF和RLVR仍然面临一些根本性的局限。
RLHF需要大量的人工标注,成本高且容易存在偏见。
而RLVR则需要特定领域的验证器与标准答案。例如,在数学领域需要专家标注的解;代码生成任务中,需要全面的测试用例和执行环境。
那么,大语言模型能够否仅靠自身生成的内在信号来提升推理能力?
于是本文的研究者们提出、探索了一种新范式:基于内部反馈的强化学习(Reinforcement Learning from Internal Feedback,RLIF)。
在这种新范式下,模型通过优化自身的内部反馈来提升性能,从而无需外部奖励或监督。
RLIF不仅适用于当前的场景,还延伸到了未来——当模型的发展超出人类能力,人类难以直接评估其表现时,模型只能通过内在机制实现自我改进。
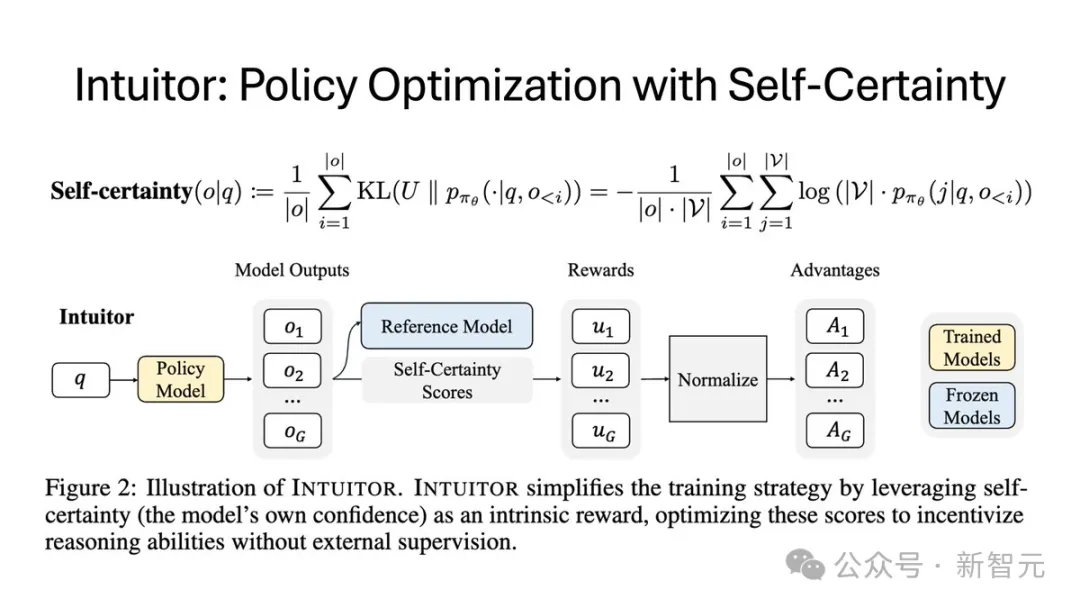
在RLIF范式下,研究团队提出了INTUITOR,这是一种新的强化学习方法,利用模型自身的置信度作为一种内在奖励。
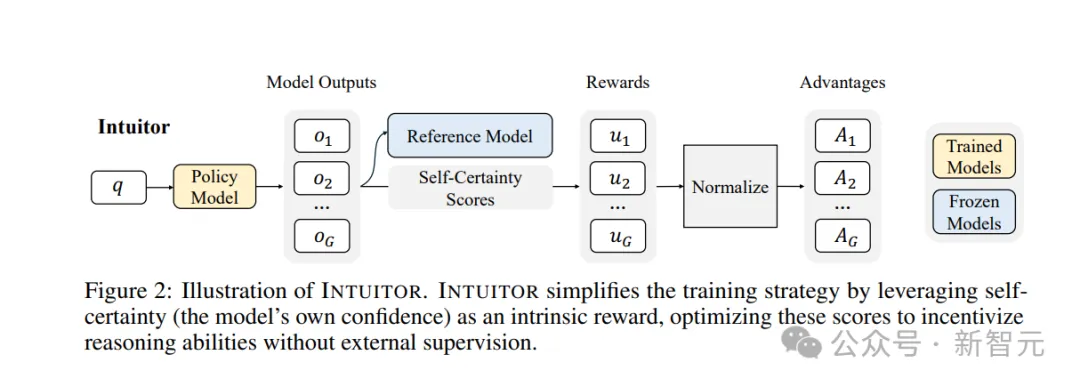
具体来说,团队使用自我确定性作为置信度的衡量标准。自我确定性已被证明可以有效区分高质量和有缺陷的回答。
INTUITOR的实现方式简单、高效且有效:团队用自我确定性得分取代了现有RLVR框架(特别是GRPO)中的可验证奖励信号,并沿用了相同的策略梯度算法。
实验设置
训练设置
GRPO和INTUITOR都使用Open-R1框架在MATH数据集的训练集上进行训练,该数据集包含7,500道题目。
研究者采用Qwen2.5-1.5B和Qwen2.5-3B作为基础模型,全程使用对话式提示格式。
由于这些模型最初在指令遵循能力上较弱,不强制要求它们将中间推理过程与最终答案拆分开。
每次更新处理128道题目,每题生成7个候选解,默认的KL惩罚系数为β=0.005。
为了公平比较,GRPO与INTUITOR使用完全相同的超参数,未进行额外调参。
INTUITOR在代码生成任务中的应用(INTUITOR-Code)
为评估其在数学推理之外的泛化能力,研究者将INTUITOR应用于Codeforces代码生成数据集。该变体在表1中被标记为INTUITOR-Code。
评估
评估阶段大多采用与训练一致的对话式提示格式。所有生成均采用贪婪解码。
实验在英伟达A100显卡上进行,每张卡具有40GB显存。
在以下基准上,研究者评估了模型性能:
数学推理任务:MATH500和GSM8K,使用lighteval库;
代码推理任务:CRUXEval-O,使用ZeroEval 框架,以及LiveCodeBench v6(LCB);
指令遵循任务:AlpacaEval 2.0,使用长度控制的胜率指标,由GPT-4.1进行评审。
结果与分析
表1展示了主要的评估结果,图3则显示了训练过程中回答长度的变化趋势。
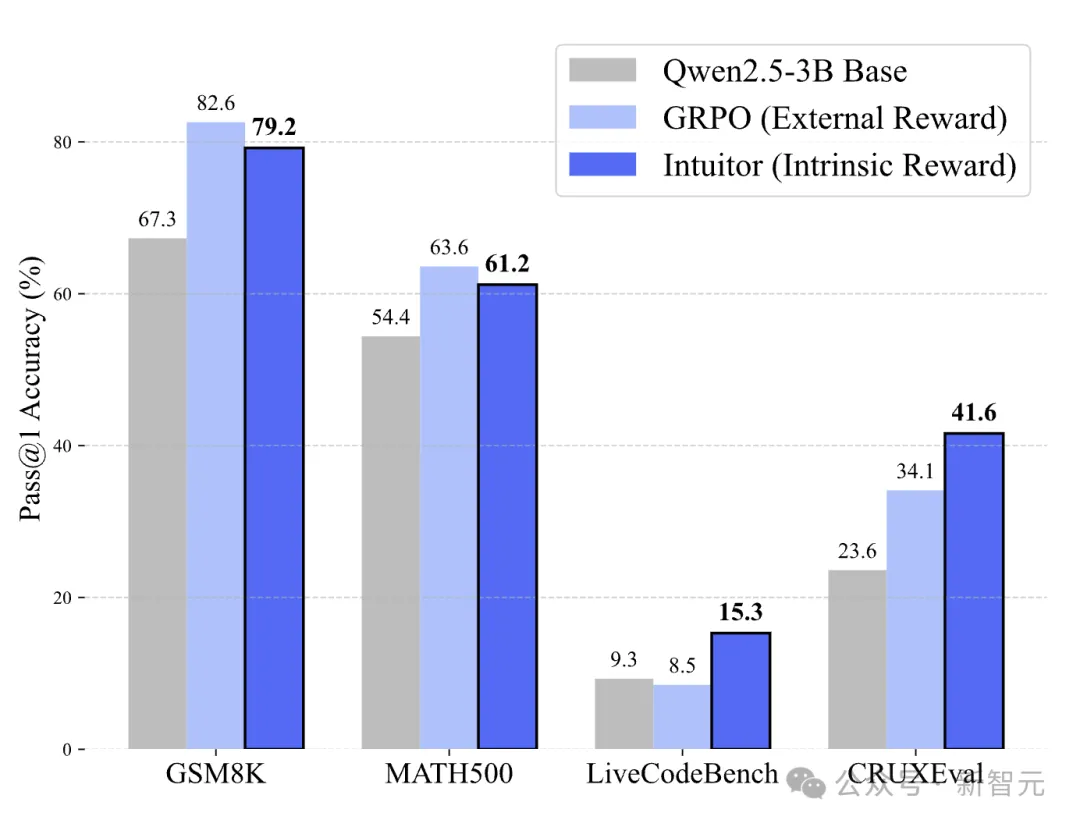
在MATH和GSM8K数据集上,INTUITOR和GRPO-PV(两者都不依赖标准答案)表现出了与GRPO(使用标准答案)相当的性能。
虽然INTUITOR整体表现略逊于GRPO,但在MATH数据集上,它的回答更长,且代码生成能力显著提升,显示出更强的推理能力。
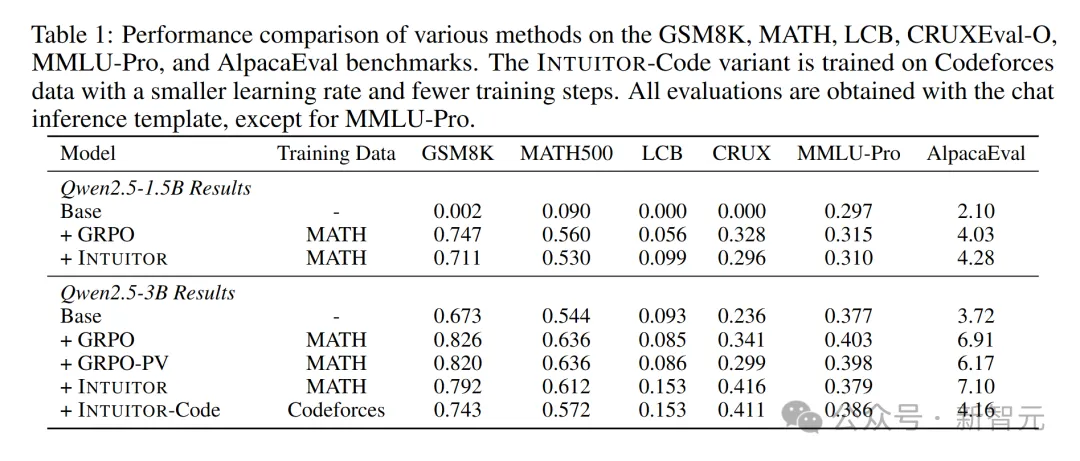
各种方法在GSM8K、MATH、LCB、CRUXEval-O、MMLU-Pro和AlpacaEval基准测试上的性能对比
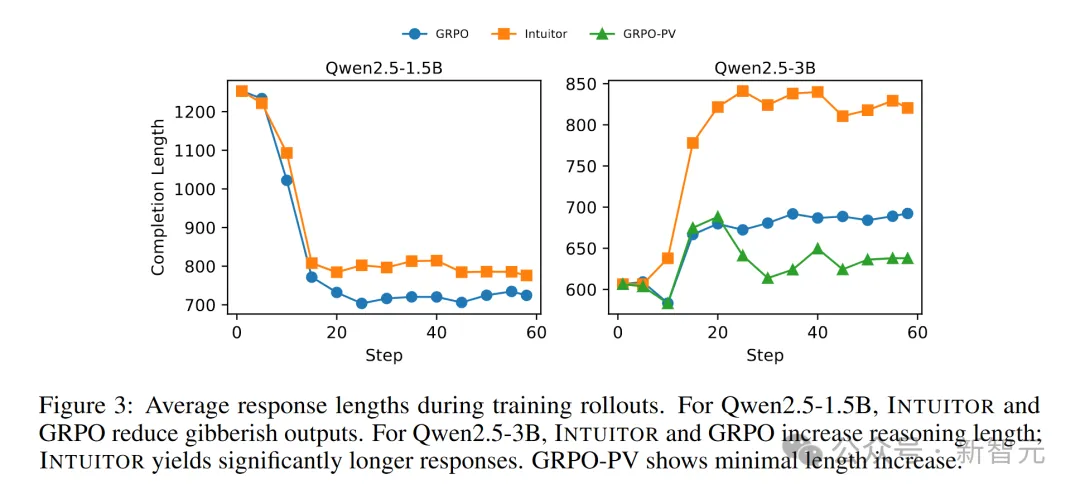
训练过程中平均响应长度。对于Qwen2.5-1.5B模型,INTUITOR和GRPO减少了无意义输出。对于Qwen2.5-3B模型,INTUITOR和GRPO增加了推理长度,其中INTUITOR的响应长度显著更长。GRPO-PV的长度增加最小
学会遵循指令
INTUITOR在遵循指令方面有了显著提升。
最初,预训练的Qwen2.5-1.5B模型在处理对话式提示时表现不佳,在所有对话模板任务上的得分低于10%(见表1),生成的回答往往重复且无意义,导致平均回答长度过长(见图3)。
通过INTUITOR的微调,这种无意义输出大幅减少,回答长度缩短,且在所有评估基准上都取得了非凡的性能提升。
此外,在MATH数据集上,INTUITOR显著提高了Qwen2.5-1.5B和Qwen2.5-3B模型在AlpacaEval上的长度控制胜率,超越了相同设置下的GRPO。
这表明INTUITOR在遵循指令方面取得了稳健的进步。
培养结构化推理
快速初步学习。“自我确定性”是一种连续的、内在的奖励信号,来自模型对所有token的内部评估,与二元奖励形成对比。
这种内部信号可能推动大语言模型(LLMs)走上更高效的学习路径。
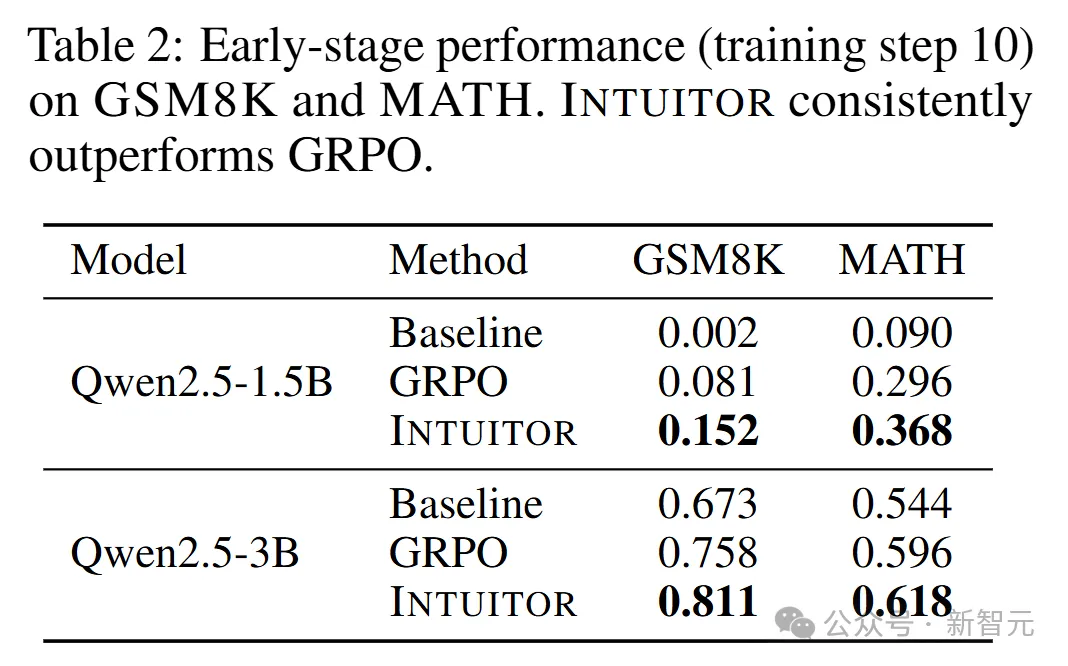
考虑到GRPO和INTUITOR的最终表现不分伯仲,团队通过对比两者在训练至第10步时的领域内准确率,来评估它们早期的学习能力。
如表2所示,在GSM8K和MATH基准测试中,INTUITOR在Qwen2.5-1.5B和Qwen2.5-3B模型上始终优于GRPO,凸显了其在快速初步学习上的优势。
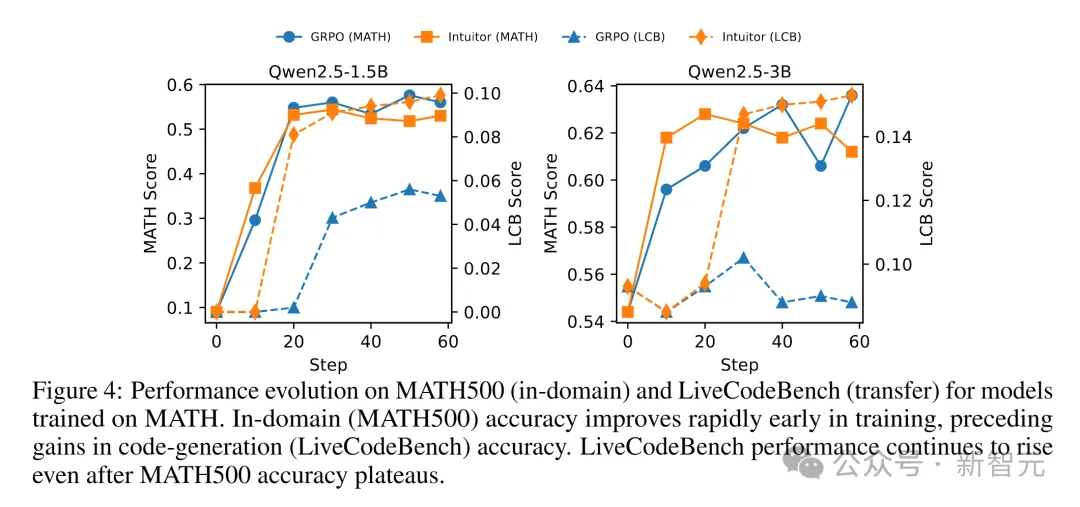
跨任务泛化。图4展示了在MATH数据集上训练的模型在MATH500(领域内任务)和LiveCodeBench(迁移任务)上的表现变化。
无论是INTUITOR还是GRPO,模型都会先在MATH500上率先提分,而LiveCodeBench的准确率提升要到训练后期才逐渐显现。
更有意思的是,哪怕MATH500的成绩已经进入平台期,LiveCodeBench上的表现仍在继续攀升。
这说明:先在MATH数据上学到的“本行”知识,为之后迁移到代码生成任务(LiveCodeBench)提供了扎实的基础。
长推理的涌现。虽然像Deepseek-R1这样的大模型通过大量强化学习(RL)实现长篇推理,但INTUITOR使较小的模型在有限数据下也能发展出结构化推理能力。
在CRUXEval-O基准(图5)上,用INTUITOR训出来的模型常常先用自然语言随意地想一番,再把结论浓缩进要求的JSON里——尽管提示里已经要求它直接用JSON推理。
同样的“先自然语言推理,后写代码”现象,也出现在LiveCodeBench上。
这种自发出现的“预推理”过程,或许正是INTUITOR能在这些评测中表现亮眼的关键。

理解LLM的涌现式长链推理能力
当LLM遇到陌生问题时,它们会从一组可能的答案分布中进行采样。
自我确定性反映了模型对其输出连贯性的内部评估。通过强化高自信度的回答,INTUITOR鼓励更具层次的推理过程,有可能提升模型对自身输出的理解能力。
研究者通过分析使用INTUITOR训练的代码模型在不同训练阶段生成的结果,来观察这一机制。
具体方法是从LiveCodeBench数据集中随机选取10道题,观察各训练阶段模型的输出演变。
图6展示了输出类型和模型准确率的变化趋势。
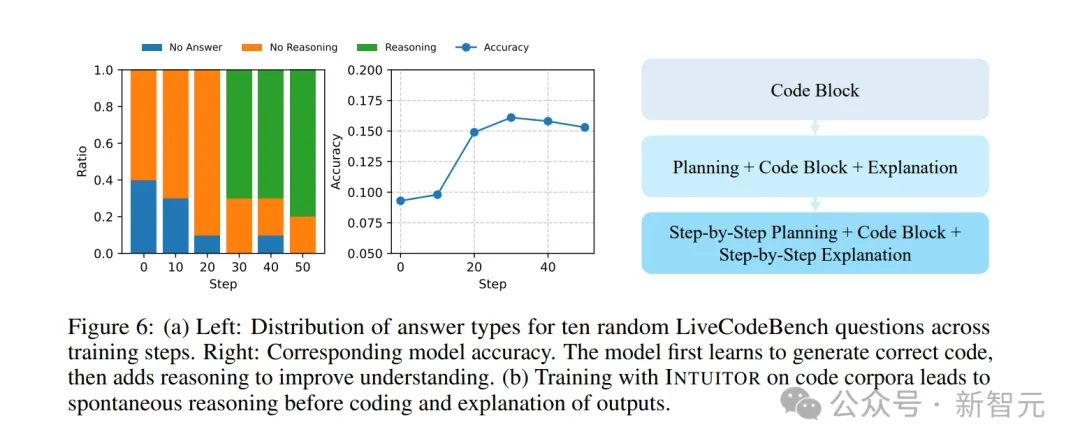
结果显示出了清晰的演进路径:模型首先学会生成有效的 Python 代码(体现在准确率提升和无效输出减少),随后开始发展出前置推理能力,以便更好地理解自身行为。
进一步的生成样本检查也证实:模型在训练过程中会逐步丰富其推理内容,验证了我们关于“INTUITOR鼓励模型生成自身更易理解的推理轨迹”的假设。
在线自置信防止奖励滥用
在强化学习里,如果奖励模型是静态的,策略就可能一味钻空子而不是老老实实提高能力。
为测试把“自置信”当奖励到底稳不稳定,团队做了两种设置:
离线自置信:奖励来自固定的基础模型;
在线自置信:奖励随策略模型一同更新。
两种情况下,我们把每次梯度更新的批大小都降到224条回答。
图7所示,大约在第100次更新后,离线设置的策略学会了“刷分”:它在每个答案后偷偷附上一道自己早已解出的额外题目,以此抬高自置信奖励。结果是:
回答长度(虚线)突然飙升;
验证准确率(实线)却瞬间崩盘。
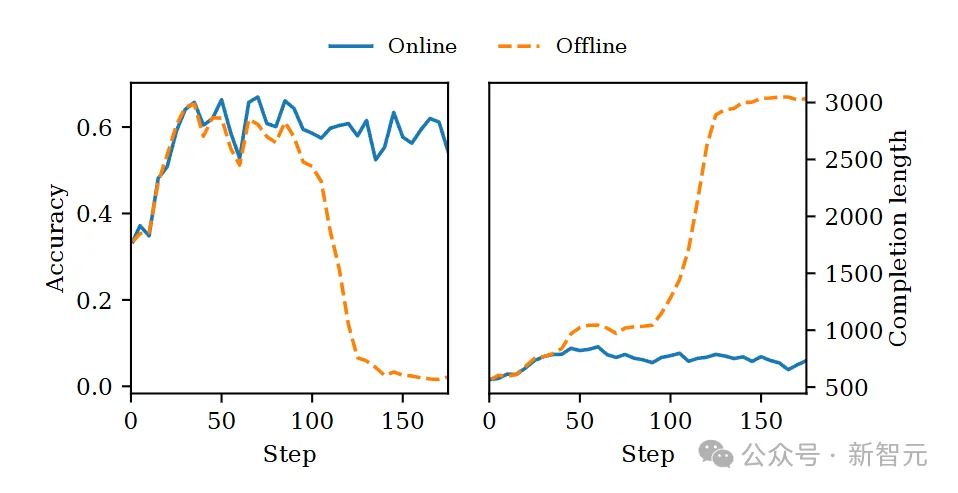
在线设置下,奖励信号随着策略同步进化,策略想“骗分”就难多了,训练曲线始终平稳。
研究团队进一步拿INTUITOR和GRPO在MATH500上生成的回答,分析自置信分布(图8),并用Mann–Whitney U检验比较正确与错误答案的自置信差异。
正确答案的平均自置信都显著高于错误答案。
INTUITOR(在线自置信):没有任何“刷分”迹象,在U检验中给出了最低p值和最大的效应量r,说明它最能用自置信区分对错,即便整体信心更高。
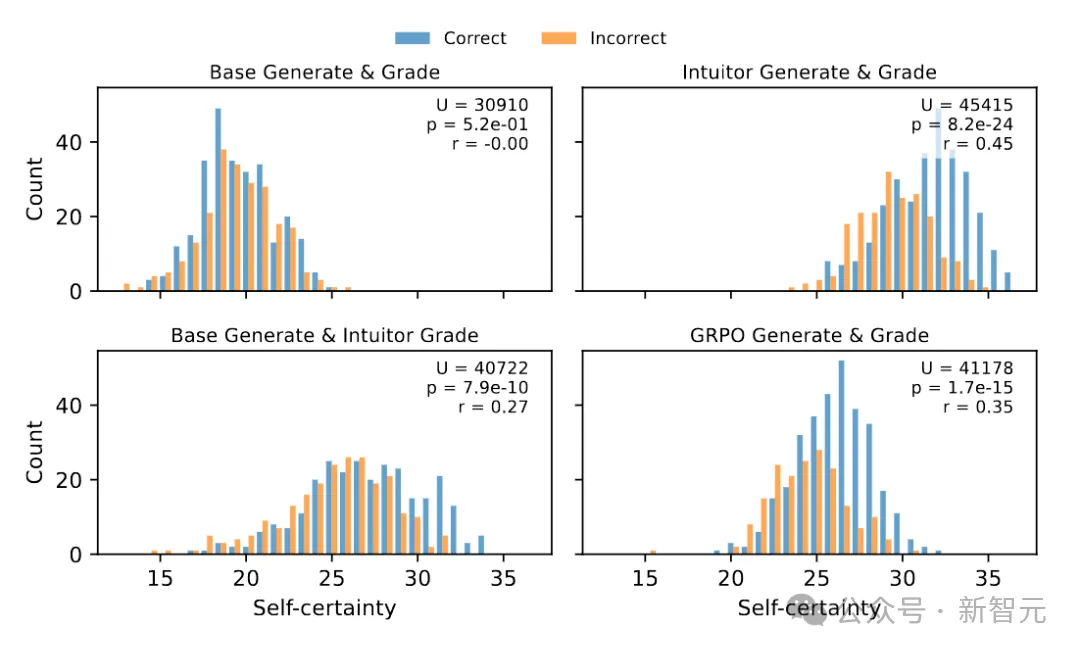
这些结果表明,INTUITOR的在线自置信机制不仅防止了奖励被滥用,还让模型在大规模数据集上有望保持稳健训练。