AI可以自审代码了,Opus 4.7出手解决“屎山”
2026-04-17 00:25:50 · chineseheadlinenews.com · 来源: 腾讯科技

别的AI厂商发模型,上来一定会告诉你“我们这次的产品多厉害多强大”。但Anthropic不一样,他们说“我们有更强的,但先不能给你。”
于是在2026年4月17日,Anthropic发布了Claude Opus 4.7。
这次发布没有太多悬念,官方博客按部就班地列出了跑分、能力提升和应用场景。但如果你仔细读完整篇公告,会发现一些不太寻常的地方。
Opus 4.7紧跟在Anthropic的Project Glasswing和Mythos Preview之后。而上周他们刚刚宣布Mythos Preview因为网络安全能力过强,暂时限制发布。
因此Opus 4.7被明确定位为“第一款用来测试新网络安全护栏的公开模型”。
官方甚至还说,他们在训练过程中实验性地削弱了这个模型的网络安全能力。
那Opus 4.7具体如何呢?
01
Opus 4.7的性能如何?
先说常规部分。
Opus 4.7在多个基准测试上超过了Opus 4.6,尤其是在高级软件工程任务上。
官方图表里,Opus 4.7在SWE-Bench Verified上为87.6%,Opus 4.6为80.8%;在更难的SWE-Bench Pro上,Opus 4.7为64.3%,Opus 4.6为53.4%;在Terminal-Bench 2.0上,Opus 4.7为69.4%,Opus 4.6为65.4%;Finance agent v11上,Opus 4.7为64.4%,Opus 4.6为60.1%。
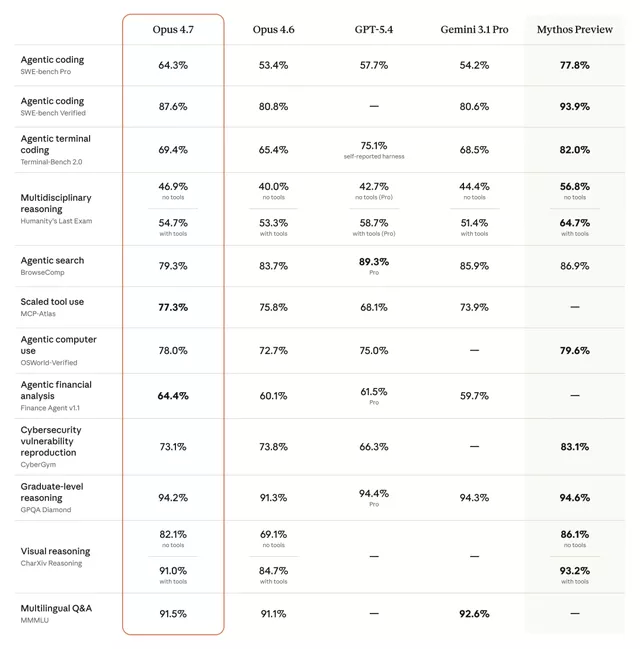
让我们用人话来解释一下这一串数字:你现在可以把更复杂的编程工作交给Opus 4.7,它会更严谨地处理长时间运行的任务,更精确地遵循指令,还会在汇报之前想办法验证自己的输出。
在Opus 4.7早期测试者的反馈里,有几个点值得注意。
第一个是指令遵循能力大幅提升。
Opus 4.7会严格按照字面意思理解指令,而之前的模型往往会松散解读或者跳过某些部分。
这听起来是好事,但实际上可能带来麻烦。其表现为Opus 4.7更“听话”了,但这反而会让一些旧提示词失效。
以前的Claude可能会比较“会意”。你写一个模糊指令,它会自动补全你的真实意图,或者忽略一些不太重要、互相冲突、写得不清楚的要求。很多用户的提示词,其实是在这种旧模型习惯上调出来的。
但Opus 4.7官方说,它更倾向于严格按字面意思执行指令。这样一来,旧提示词里那些以前被模型自动忽略的小细节,现在可能会被认真执行。而以前模型会灵活处理的模糊表达,现在反而会按最直接的方式理解。
结果就是模型明明更强了,但输出反而和用户预期不一样。
第二个是多模态支持改进。
Opus 4.7可以接受长边最高2576像素的图像,大约3.75兆像素,是之前Claude模型的三倍多。
这不是普通的“识图能力”升级,而是为了让AI能看懂软件界面,服务于Anthropic的Computer Use功能。
Opus 4.7的视觉升级,不是为了让用户问“这张图里有什么”,而是为了让agent能看懂软件界面。
agent如果看不清密集表格、终端输出、设计稿细节、代码截图,它的操作能力再强也没用,因为它只知道怎么干活,却不知道去哪上班。
Anthropic把图像分辨率往上提,本质上是在给Claude装更清楚的眼睛。
未来AI办公、AI测试、AI安全、AI前端开发,很多任务都不是纯文本任务,而是屏幕任务。
第三个是实际工作表现。
内部测试显示,Opus 4.7在金融分析任务上比Opus 4.6更有效,能产出更严谨的分析和模型、更专业的演示文稿,以及更紧密的跨任务整合。
它在GPQAval-AA这个第三方评估中也是最高分,这是一个覆盖金融、法律等领域的评估。
第四个是记忆能力。
Opus 4.7更会使用基于文件系统的记忆。它能在长周期、多会话的工作中记住重要笔记,后续任务需要的前置信息更少。
这个点在官方公告里不显眼,但我认为可能是长期使用中最关键的一个更新特性。
一个能跨会话记住项目约束、用户偏好、架构决策和上次失败原因的agent,才可能从“聪明临时工”变成“稳定同事”。
安全性和对齐方面,Opus 4.7和Opus 4.6的整体表现相似。
它在诚实度和抵抗恶意提示注入攻击的能力上有所提升,在给出危害建议的能力上有所下降,比如如何制作使用管制刀具这类问题。
官方的对齐评估结论是,这个模型“基本对齐且值得信赖,但行为上还不完全理想”。
价格方面,Opus 4.7和Opus 4.6保持一致。输入每百万token 5美元,输出每百万token 25美元。
但迁移指南里提到了两个成本变化。新的tokenizer可能让相同输入变成1.0到1.35倍的token。在强思考模式下,尤其是agent的多轮对话,模型会思考更多,输出的token也可能更多。
所以这就是Anthropic耍小心思的地方了,名义上价格确实没变,但跑多了就会变贵。
过去模型计费主要看输入输出长度,现在还要看思考的等级、任务预算、agent跑了几轮、工具失败后有没有继续推理。
Anthropic新增的x-high effort和task budgets,说明高端模型的使用方式正在走当年云计算的那套逻辑。你买的不是一次回答,而是在给一个会思考、会试错、会验证的任务过程付费。
02
Anthropic为何会发布阉割模型?
话又说回来,Opus 4.7的真正卖点之一,恰恰是它没有完全释放能力。
这听起来有点反直觉,但可能是下一代模型公司的常态。
模型越接近真实生产环境,越不能只追求更强。它要知道哪些事能做、哪些事不能做、哪些用户能开放更多权限,哪些请求必须拦住。
Anthropic在发布Opus 4.7的同时,推出了Cyber Verification Program。
这个项目本质上是在给能力分级。普通用户拿到的是有护栏的Opus,经过验证的安全专家才能申请更宽的网络安全用途。
模型会自动检测和阻止那些表明禁止或高风险网络安全用途的请求。
Anthropic说,他们会从Opus 4.7的真实部署中学习,为未来Mythos级别模型的广泛发布做准备。
不得不说还是Anthropic会玩,他们认为Opus目前的能力是过剩的,所以他们就把安全这件事,变成了产品能力。
过去几年,AI公司的竞争逻辑是“我比你强”。跑分更高、参数更多、能做的事更复杂。但当模型能力达到某个临界点后,这个逻辑开始失效。
一个在网络安全测试中表现太好的模型,可能意味着它也能被恶意使用。一个完全不设限的agent,就有可能会在用户不知情的情况下做出危险决策。
Anthropic选择的路径是,先把最强的模型锁起来,用稍弱但足够好的模型来测试安全机制。这不是技术上做不到,而是主动选择不做。这种“克制”本身成了产品差异化的一部分。
这个策略能不能成功,取决于市场是否认可“谨慎”这个概念。
如果用户只在乎“能不能做到”,那Anthropic的做法会显得保守。但如果企业客户开始重视“会不会出事”,那这种分级发布、主动削弱某些能力的做法,反而可能成为竞争优势。
在发布Opus 4.7的同时,Anthropic还更新了Claude Code,新增了auto mode和/ultrareview功能。
auto mode不是模型自动选型,而是权限选项。它允许Claude替用户做一些权限决策,让长任务少被打断,但风险低于完全跳过权限确认。
这个设计针对的是agent产品的核心矛盾:问太多,agent像实习生;不问,风险又太大。
agent时代最难设计的按钮,不是“开始”,而是“允许”。
过去AI只是回答问题,权限很少。
现在它要改代码、读文件、跑命令、开网页、提交PR,每一步都牵涉风险。
如果每个操作都要用户确认,agent的自主性就失去了意义。但如果完全放手,用户又会担心AI做出不可逆的错误决策。
auto mode的本质,就是在“别烦我”和“别乱来”之间找平衡。
它会根据操作的风险级别,决定是自动执行、提示用户、还是要求明确授权。
这也是agent从“能干什么”,到“能不能用”之间巨大的飞跃。
/ultrareview是一个专门的代码审查会话,读取变更并指出bug和设计问题。
这个功能可比写代码好玩多了,因为它说明AI编程正式进入了第二阶段,让AI自己审查AI自己生成的代码。
AI写代码已经不稀奇,真正稀缺的是AI能不能审自己的代码。
/ultrareview像是Anthropic给Claude Code补上的第二双眼睛。
一个agent负责写,另一个更谨慎的会话负责审。
不用看数狙桃都能猜到,这两个功能一定是高频功能。因为本质上,这两个功能过去就是所有使用Claude Code的程序员干的活。
生成代码只是开发流程的一部分,审查、测试、重构、文档同样重要。如果AI只能做第一步,它永远只是辅助工具。如果它能参与整个流程,它才可能真正改变软件开发的方式。
这次发布还有一个细节值得注意。官方在迁移指南里专门提醒广大用户,Opus 4.7的token使用可能增加,但在实际编程评估中,整体效率反而提升了。
这说明他们在优化的不是单次调用的成本,而是完成任务的总成本。一个agent如果第一次就把事情做对,即使单次调用贵一点,总成本也比反复试错要低。
这是一种更成熟的产品思路。早期AI产品追求的是“便宜”和“快”,现在开始追求“靠谱”。
Opus 4.7不是最强的模型,Anthropic也没有把它包装成最强的模型。
它是在能力、安全、成本之间的一个平衡点。但是说它是不是真的平衡,我不知道,这个要等市场来验证。
至少在发布策略上,Anthropic给出了一种新思路,因为有时候“不做什么”比“能做什么”更重要。